✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
本文系统介绍了Redis的常见数据类型及其应用场景,包括String、Hash、List、Set、Sorted Set,以及在不同版本新增的BitMap、HyperLogLog、GEO和Stream等高级数据结构。文章详细解析了Redis键值对的底层实现机制,阐述了Redis基于内存存储、单线程模型、多路复用I/O及高效数据结构等设计,解释了其高性能的技术原理。通过Java代码示例,展示了BitMap、HyperLogLog、GEO和Stream的具体应用。并以朋友圈点赞功能为例,演示了基于ZSet实现的点赞操作设计。最后,文章深入探讨了Redis为何采用单线程设计及6.0版本引入多线程的原因,结合五种常见I/O模型,全面解析了Redis的性能优势和架构演进,具有较强的技术指导和实用价值。
2025-01-15🌱上海: ☀️ 🌡️+6°C 🌬️↓18km/h
# Redis中常见的数据类型有哪些?
# 总结分析
- String(字符串)
- 特点:最基本数据类型,能存储文本、数字、二进制数据,最大长度 512MB。
- 使用场景:缓存临时数据(如用户会话、页面缓存),作为计数器统计访问量、点赞数等。
- Hash(哈希)
- 特点:键值对集合,适合存对象属性,内部用哈希表实现,适合小规模数据。
- 使用场景:存储商品详情的各个属性以便快速检索。
- List(列表)
- 特点:有序字符串集合,支持两端推入和弹出,底层是双向链表。
- 使用场景:消息队列(通过 LPUSH 和 RPOP 实现生产者消费者模式),存储用户操作历史记录。
- Set(集合)
- 特点:无序且不重复的字符串集合,用哈希表实现,支持快速查找和去重。
- 使用场景:标签系统(存储用户兴趣标签防重复),记录访问页面的唯一用户用于分析。
- Sorted Set(有序集合)
- 特点:类似集合,每个元素有分数用于排序,底层用跳表,支持快速范围查询。
- 使用场景:实现实时排行榜(存储用户分数),根据任务优先级排序进行任务调度 。
# 扩展知识
# 键值对数据库怎么实现的?
-
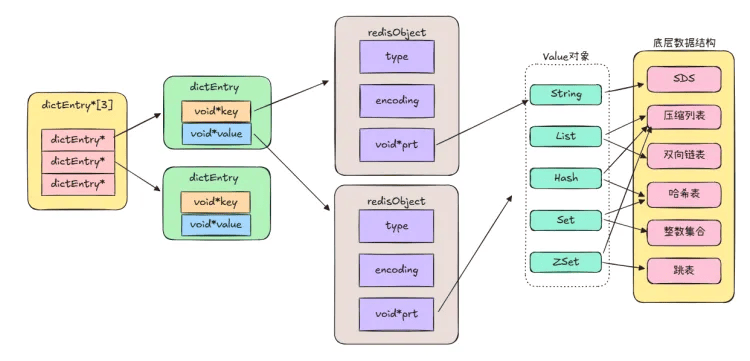
Redis 键值对概述:
-
Redis 的键(key)是字符串对象,值(value)可以是字符串对象或集合数据类型对象(如 List、Hash、Set、Zset)。
-
Redis 键值对存储方式:
-
使用哈希表保存所有键值对,哈希表本质是数组,数组元素为哈希桶。
-
哈希桶存放指向键值对数据的指针(dictEntry*),键值对数据结构中通过 void * key 和 void * value 指针分别指向实际的键对象和值对象,值对象可以是各种类型,通过指针找到对应对象。
-
相关数据结构及用途:
-
redisDb 结构:表示 Redis 数据库结构,包含指向 dict 结构的指针。
-
dict 结构:结构体里存放 2 个哈希表,正常用 “哈希表 1”,“哈希表 2” 用于 rehash(后续讲解)。
-
ditctht 结构:表示哈希表结构,包含哈希表数组,数组元素是指向哈希表节点结构(dictEntry)的指针。
-
dictEntry 结构:表示哈希表节点结构,存放 void * key(指向 String 对象)和 void * value(可指向 String、List、Hash、Set、Zset 等对象)指针。
-
redisObject 结构:每个 Redis 对象由其表示,包含成员变量 type(标识对象类型)、encoding(标识底层数据结构)、ptr(指向底层数据结构的指针)。
示例图如下:
# Redis 在不同版本新增了多种高级数据类型:
- BitMap(2.2 版新增):以位为单位存储数据,适合表示布尔值,每个 bit 表示一个状态,空间使用少且操作快,如可记录用户每天在线状态。
- HyperLogLog(2.8 版新增):概率性数据结构,用于估算基数,内存占用固定,适用于大规模数据去重和计数,如估算网站独立访客数量。
- GEO(3.2 版新增):存储地理位置信息,支持空间查询,能存储经纬度并进行距离计算、范围查询等,如查找特定范围内的城市。
- Stream(5.0 版新增):日志数据结构,适合存储时间序列或消息流,支持高效消息生产和消费,有持久性和序列化特性,可用于存储传感器数据流 。
yes哥通过redis命令演示了具体使用,这里我使用jedis通过代码进行了测试
// BitMap测试
public static void bitmapTest() {
String date = "2025-01-02";
long userId = 12345;
// 设置用户在线状态
jedis.setbit("user:online:" + date, userId, true);
// 获取用户在线状态
boolean status = jedis.getbit("user:online:" + date, userId);
System.out.println("用户ID " + userId + " 在 " + date + " 的在线状态: " + status);
}
// HyperLogLog测试
public static void hyperLogLogTest() {
String key = "unique:visitors";
String[] visitors = {"user1", "user2", "user3"};
// 添加用户ID
jedis.pfadd(key, visitors);
// 估算独立用户数量
long count = jedis.pfcount(key);
System.out.println("估算的独立用户数量: " + count);
}
// GEO测试
public static void geoTest() {
String key = "cities";
// 添加城市
jedis.geoadd(key, 13.361389, 38.115556, "Palermo");
jedis.geoadd(key, 15.087269, 37.502669, "Catania");
// 计算两个城市之间的距离
Double distance = jedis.geodist(key, "Palermo", "Catania", GeoUnit.KM);
System.out.println("Palermo和Catania之间的距离: " + distance + " km");
// 查找指定范围内的城市
Set<String> citiesInRange = jedis.georadius(key, 15.0, 37.5, 100, GeoUnit.KM);
System.out.println("距离 (15.0, 37.5) 100 km范围内的城市: " + citiesInRange);
}
// Stream测试
public static void streamTest() {
String key = "sensor:data";
// 向Stream添加传感器数据
Map<String, String> data = new HashMap<>();
data.put("temperature", "22.5");
data.put("humidity", "60");
String id = jedis.xadd(key, "*", data);
System.out.println("添加到Stream的消息ID: " + id);
// 获取Stream中的所有数据
List<StreamEntry<String, String>> allData = jedis.xrange(key, "-", "+");
System.out.println("Stream中的所有数据:");
for (StreamEntry<String, String> entry : allData) {
System.out.println(entry);
}
// 读取新的传感器数据
XReadParams params = XReadParams.xReadParams().count(10).block(0);
Map<String, List<StreamEntry<String, String>>> newData = jedis.xread(params, key);
System.out.println("新的传感器数据:");
for (Map.Entry<String, List<StreamEntry<String, String>>> entry : newData.entrySet()) {
for (StreamEntry<String, String> streamEntry : entry.getValue()) {
System.out.println(streamEntry);
}
}
}# Redis 常见数据类型及应用场景
-
String:
-
应用广泛,可用于缓存对象,方便数据快速读取;作为计数器,实现原子性的计数操作,如统计访问量等;实现分布式锁,保证多个客户端对共享资源的互斥访问;用于分布式 session,在分布式系统中存储用户会话信息。
-
List:
-
可充当阻塞队列和消息队列,但存在生产者需自行实现全局唯一 ID 以及不能以消费组形式消费数据的问题。适用于简单的消息传递和任务调度等场景。
-
Hash:
-
适合缓存对象,能高效存储和获取对象的多个属性;可用于实现购物车功能,方便管理商品及其数量等信息。
-
Set:
-
适用于集合聚合计算场景,如点赞、共同关注、收藏等,可快速计算并集、交集、差集等。
-
Zset:
-
最典型应用是排行榜,能根据元素的分数实时排序,常用于游戏排名、热门商品排名等。
-
BitMap(2.2 版新增):
-
只有 0 和 1 两种状态,可用于签到统计,记录用户每天的签到情况;也可用于用户登录态判断,快速确定用户是否登录过。
-
HyperLogLog(2.8 版新增):
-
适用于海量数据基数统计场景,虽有一定误差,但在网页 PV(页面浏览量)、UV(独立访客数)统计等对精度要求不是极高的情况下可使用,能节省大量存储空间。
-
GEO(3.2 版新增):
-
用于存储地理位置信息,如百度地图、高德地图等应用中的位置数据存储,以及实现附近的人等功能。
-
Stream(5.0 版新增):
-
主要用于消息队列,相比 List,它能自动生成全局唯一消息 ID,并且支持以消费组形式消费数据,同一个消息可被分发给多个单消费者和消费者组,还具有可持久化的优点,相比 pub/sub 更具优势。
# 业务场景具体实现
# 朋友圈点赞功能基于 Redis ZSet 的实现方案
-
数据结构选择与设计:
-
采用 Redis 的 ZSet 数据结构来实现朋友圈点赞功能。以具体朋友圈的 ID 作为字符串存储,作为 ZSet 的 KEY。ZSet 的 value 存储点赞用户的 ID,score 存储点赞时间的时间戳。
-
主要操作及实现方式:
-
点赞操作:将用户 ID 添加到对应朋友圈 ID 的 ZSet 中,score 设为当前时间戳。若用户已点赞,则更新其点赞时间戳,以此记录点赞顺序和时间。
-
取消点赞操作:直接从有序集合中删除该用户的 ID,实现取消点赞功能。
-
查询点赞信息:通过 ZREVRANGEBYSCORE 命令,按照 score(时间戳)逆序返回 ZSet 的 value,即能获取点赞用户的 ID,从而可查看哪些人点过赞以及点赞顺序。
import redis.clients.jedis.Jedis;
public class MomentsLike {
// 点赞操作
public void like(String momentId, String userId) {
long currentTime = System.currentTimeMillis();
// 添加用户点赞信息到ZSet,若用户已存在则更新时间戳
jedis.zadd(momentId, currentTime, userId);
}
// 取消点赞操作
public void unlike(String momentId, String userId) {
jedis.zrem(momentId, userId);
}
// 查询点赞信息
public void queryLikes(String momentId) {
// 按照时间戳逆序获取点赞用户ID
jedis.zrevrange(momentId, 0, -1).forEach(System.out::println);
}
public static void main(String[] args) {
MomentsLike momentsLike = new MomentsLike();
String momentId = "moment1";
String userId1 = "user1";
String userId2 = "user2";
// 用户1点赞
momentsLike.like(momentId, userId1);
// 用户2点赞
momentsLike.like(momentId, userId2);
// 查询点赞信息
System.out.println("点赞用户:");
momentsLike.queryLikes(momentId);
// 用户1取消点赞
momentsLike.unlike(momentId, userId1);
// 再次查询点赞信息
System.out.println("取消点赞后点赞用户:");
momentsLike.queryLikes(momentId);
}
}# ZSet实现排行榜
暂略,后续补充
# 实现附近的人
暂略,后续补充
# 实现滑动窗口限流
这个我之前实现了四种限流方式,并通过策略模式,根据不同的接口应用不同限流模式(具体实现代码后续补上)
# Redis为什么这么快
# 总结分析
- 基于内存(重点):Redis 是内存数据库,数据存于内存,内存访问速度远快于硬盘,极大提升数据读写速度。
- 单线程模型(重点):采用单线程,所有操作在一个线程内完成,避免线程切换和上下文切换,提高运行效率与响应速度。
- 多路复用 I/O 模型(重点):在单线程基础上运用 I/O 多路复用技术,单个线程能同时处理多个客户端连接,提升并发性能。
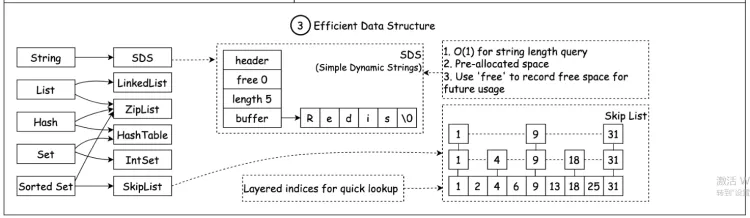
- 高效的数据结构(重点):提供哈希表、有序集合、列表等多种高效数据结构,能在 O (1) 时间复杂度内完成数据读写,利于快速处理数据请求。
- 多线程的引入(重点):Redis 6.0 引入多线程机制,提升 IO 性能。能让网络处理请求并发进行,减少网络 I/O 等待影响,还能利用 CPU 多核优势 。
# 扩展内容
- 存储方式:Redis 基于内存存储,内存访问速度极快,相比 SSD 磁盘快近千倍,比传统硬盘更快。除持久化等少数场景,多数读写基于内存,大大提升效率。
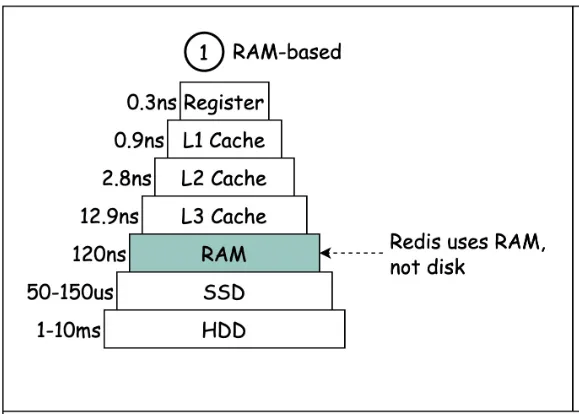
- 优秀的线程模型以及 IO 模型
- 单线程优势:使用单个主线程执行命令,避免线程切换和上下文切换开销,提高运行效率与响应速度。
- I/O 多路复用:采用该技术,单个线程能同时处理多个客户端连接,提升并发能力。
- 多线程引入:4.0 开始引入如 Unlink 等异步执行命令;6.0 后引入多线程机制,并发处理网络请求,减少网络 I/O 等待影响。
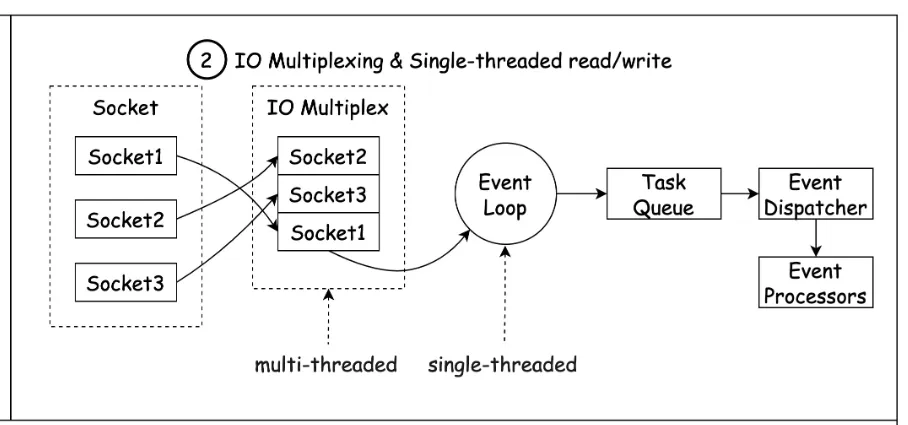
- 高效的数据结构:Redis 提供字符串、哈希、Zset 等丰富数据结构,多数操作时间复杂度为 O (1),能快速完成各种操作 。
# 为什么Redis单线程也能这么快?
Redis 性能好有多方面原因,其中重要一点是在单线程中使用多路复用 I/O 技术提升 I/O 利用率。
多路复用技术:
- Linux 多路复用技术允许多个进程的 I/O 注册到同一管道与内核交互,准备好数据后进程再将其拷贝到用户空间,实现一个线程处理多个 I/O 流。
- Linux 下 I/O 多路复用有 select、poll、epoll 三种,功能类似细节不同。
- Redis 的 I/O 多路复用程序通过包装操作系统的 I/O 多路复用函数库实现功能,每个函数库在源码中有对应文件。
- 在 Redis 中,套接字准备好执行相关操作时会产生文件事件,多个文件事件可能并发出现,请求到达后由 Redis 线程处理,达成一个线程处理多个 I/O 流的效果。
Redis 高性能的其他原因:
- 完全基于内存,多数请求为内存操作,速度极快。
- 数据结构简单,操作也简单,如哈希表、跳表性能高。
- 采用单线程,避免上下文切换、竞争条件以及多进程或多线程切换带来的 CPU 消耗 。
# 说一下常见的五种I/O模型
下面我们讲一个例子先来浅浅谈一下这5个模型IO的做法。
- 从前有一条小河,河里有许多条鱼,一个叫张三的少年就很喜欢钓鱼,他带着自己的鱼竿就去钓鱼了,但张三这个人很固执,只要鱼没上钩,张三就一直等着,什么都不干,死死的盯着鱼漂,只有鱼漂动了,张三才会动,然后把鱼钓上来,钓上来之后,张三就又会重复之前的动作,一动不动的等待鱼儿上钩。
- 而此时走过来一个李四,李四这名少年也很喜欢钓鱼,但李四和张三不一样,李四左口袋装着《Linux高性能服务器编程》,右口袋装着一本《算法导论》,左手拿手机,右手拿了一根鱼竿,李四拿了钓鱼凳坐下之后,李四就开始钓鱼了,但李四不像张三一样,固执的死盯着鱼漂看,李四一会看会儿左口袋的书,一会玩会手机,一会儿又看算法导论,一会又看鱼漂,所以李四一直循环着前面的动作,直到循环到看鱼漂时,发现鱼漂已经动了好长时间了,此时李四就会把鱼儿钓上来,之后继续重复循环前面的动作。
- 此时又来了一个王五少年,王五就拿着他自己的iphone14pro max和一根鱼竿外加一个铃铛,然后就来钓鱼了,王五把铃铛挂到鱼竿上,等鱼上钩的时候,铃铛就会响,王五根本不看鱼竿,就一直玩自己的iphone,等鱼上钩的时候,铃铛会自动响,王五此时再把鱼儿钓上来就好了,之后王五又继续重复前面的动作,只要铃铛不响,王五就一直玩手机,只有铃铛响了,王五才会把鱼钓上来。
- 此时又来了一个赵六的人,赵六和前面的三个人都不一样,赵六是个小土豪,赵六手里拿了一堆鱼竿,目测有几百根鱼竿,赵六到达河边,首先就把几百根鱼竿每隔几米插上去,总共插了好几百米的鱼竿,然后赵六就依次遍历这些鱼竿,哪个鱼竿上的鱼漂动了,赵六就把这根鱼竿上的鱼钓上来,然后接下来赵六就又继续重复之前遍历鱼竿的动作进行钓鱼了。
- 然后又来了一个钱七,钱七比赵六还有钱,钱七是上市公司的CEO,钱七有自己的司机,钱七不喜欢钓鱼,但钱七喜欢吃鱼,所以钱七就把自己的司机留在了岸边,并且给了司机一个电话和一个桶,告诉司机,等你把鱼钓满一桶的时候,就给我打电话,然后我就从公司开车过来接你,所以钱七就直接开车回公司开什么股东大会去了,而他的司机就被留在这里继续钓鱼了。
常见的 I/O 模型有五种,从读取网络数据角度,以演进视角介绍如下:
-
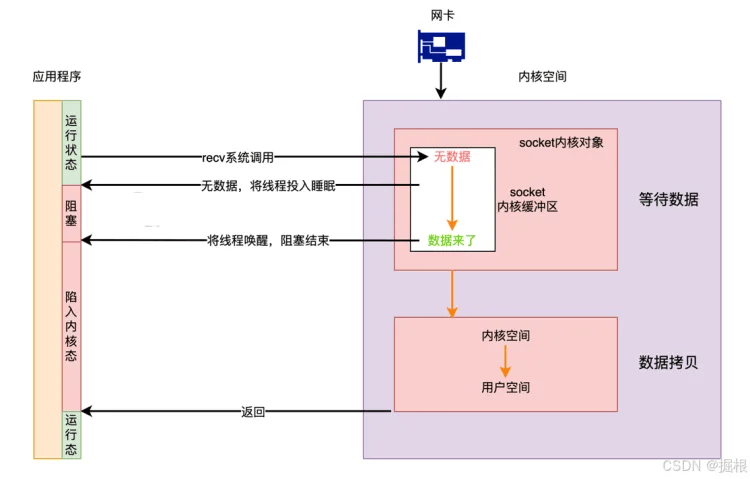
同步阻塞 I/O(BIO):
- 原理:用户线程调用
read获取网络数据时,需等待网卡接收数据、数据拷贝到内核、再拷贝到用户空间,整个过程线程阻塞。 - 优点:简单,调用
read后等待数据处理即可。 - 缺点:一个线程对应一个连接,资源浪费,即便无数据也会阻塞。
- 原理:用户线程调用
-
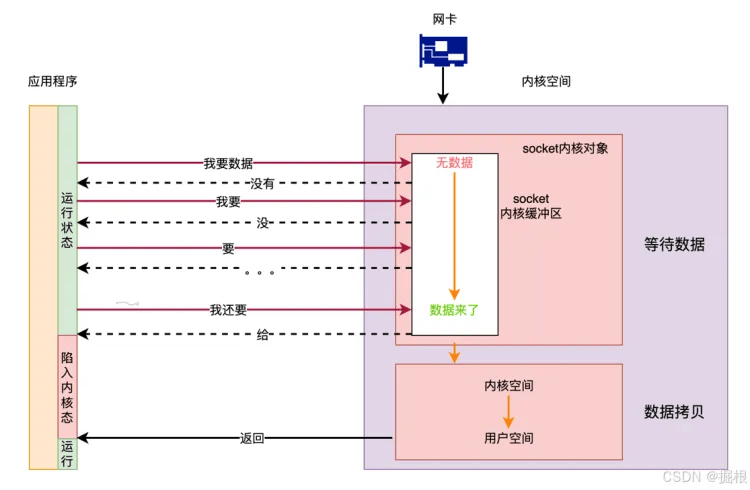
同步非阻塞 I/O(NIO):
- 原理:无数据时,用户程序不再阻塞,直接返回错误,通过轮询发起
read调用,数据从内核拷贝到用户空间时会阻塞。 - 优点:比 BIO 灵活,线程可在无数据时处理其他任务。
- 缺点:若线程仅处理数据,海量连接下会频繁系统调用,CPU 上下文切换频繁,资源消耗大。
- 原理:无数据时,用户程序不再阻塞,直接返回错误,通过轮询发起
-
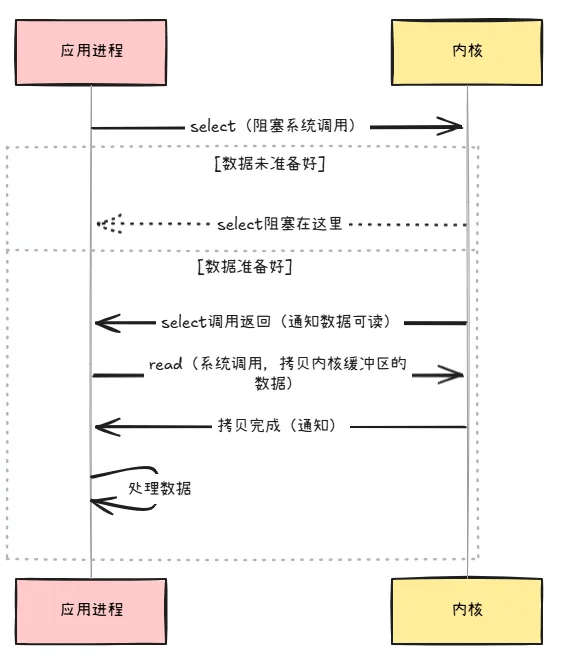
I/O 多路复用:
- 原理:使用一个线程监控多个连接是否有数据就绪,通过
select注册监听连接,有数据时通知其他线程read数据,read仍会阻塞线程。 - 优点:减少线程数量,降低内存消耗和上下文切换次数。
- 缺点:
select需时刻查询数据就绪状态。
- 原理:使用一个线程监控多个连接是否有数据就绪,通过
-
信号驱动式 I/O:
- 原理:内核告知数据准备就绪,用户线程再去
read(仍会阻塞)。 - 优点:无需轮询等待数据。
- 缺点:TCP 协议下,多种事件产生同一信号,应用程序难区分信号来源,基本不可用;UDP 协议下可用。
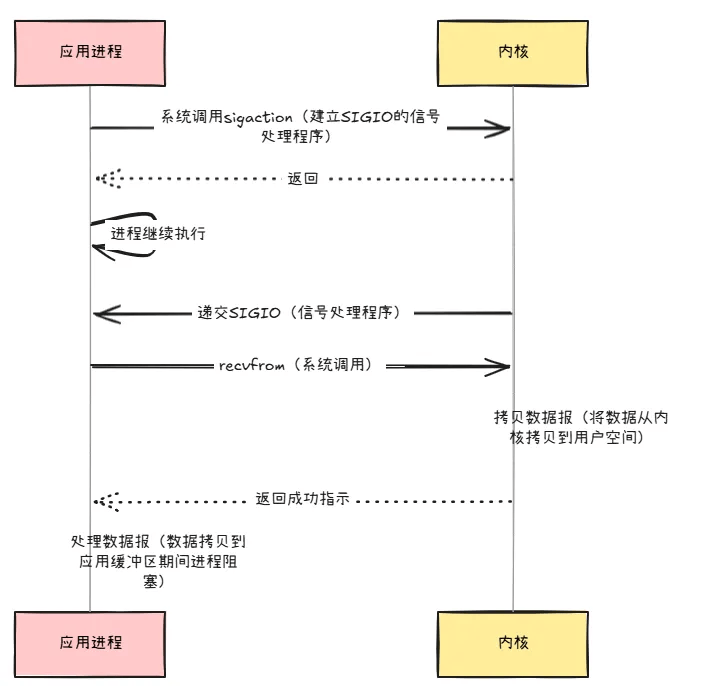
- 原理:内核告知数据准备就绪,用户线程再去
-
异步 I/O(AIO):
- 原理:用户线程调用
aio_read,内核完成数据从内核到用户空间的拷贝,操作完成后调用回调通知用户线程,全程无阻塞。 - 优点:真正的非阻塞 I/O。
- 缺点:Linux 对其支持不足,实际多为用
epoll模拟实现;Windows 实现了真正的 AIO,但服务器多部署在 Linux 上,故主流仍是 I/O 多路复用 。
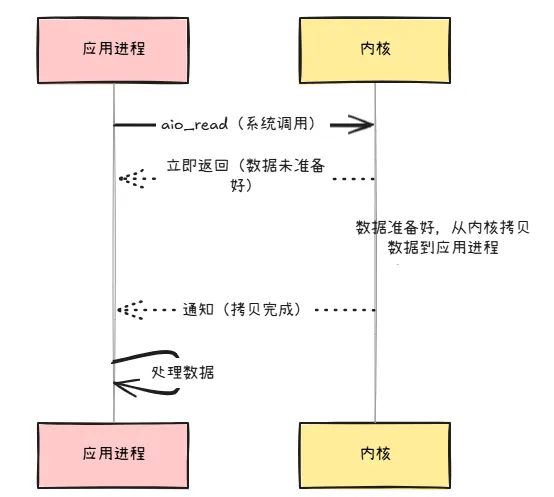
- 原理:用户线程调用
# 为什么Redis设计为单线程?6.0版本为何引入多线程?
# 总结分析
Redis 采用单线程设计的原因:
- 基于内存操作,多数操作性能瓶颈非 CPU 导致。
- 单线程模型代码简便,可减少线程上下文切换的性能开销。
- 单线程结合 I/O 多路复用模型能提高 I/O 利用率。
Redis 6.0 版本引入多线程的原因:随着数据规模和请求量增加,执行瓶颈主要在网络 I/O,引入多线程可提高网络 I/O 处理速度。
# 扩展知识
# 前置知识
说说你知道的几种 I/O 模型 - 面试鸭 - 程序员求职面试刷题神器
Select、Poll、Epoll 之间有什么区别? - 面试鸭 - 程序员求职面试刷题神器
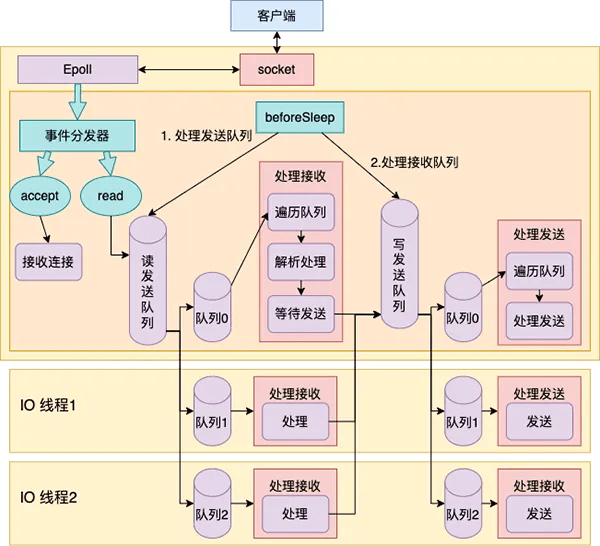
其实对于多线程Redis的具体优化点,需要比较深入了解网络和操作系统的一些相关知识,下面列几个图解大概了解下多线程及单线程的Redis工作原理。需要深入了解的话还需要多学一些基础知识。
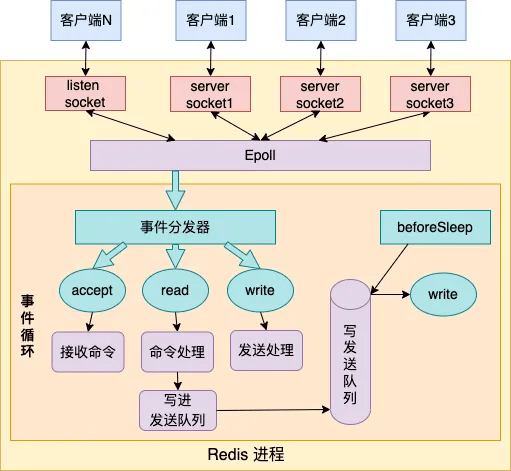
# 单线程下的Redis核心原理
# 多线程下的Redis核心原理
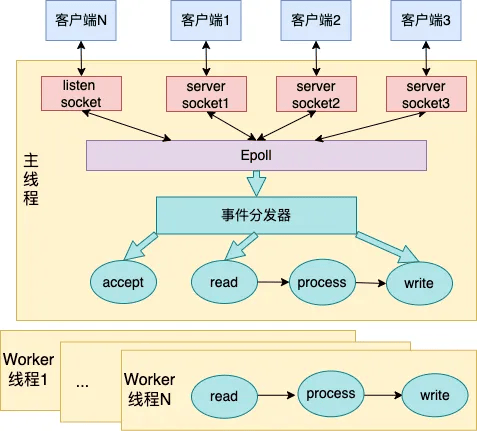
# 多线程下Redis工作流程