✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
本文系统解析了Redis中跳表(SkipList)的实现原理及其源码细节,详细介绍了跳表节点结构、层级设计、插入、查找和删除操作的具体流程与代码实现,重点阐述了跳表中forward指针、backward指针及跨度(span)的作用和维护机制。文章还深入剖析了Redis Hash的数据结构,包括其底层实现(ziplist/listpack与hashtable)、哈希冲突的链式哈希解决方案及渐进式rehash机制,确保高效存储与访问。最后,介绍了Redis ZSet的实现原理,说明了ZSet如何根据元素数量动态选择ZipList(ListPack)或SkipList结构以兼顾内存效率和查询性能。全文结合源码和数据结构设计,全面揭示Redis核心数据结构的创新点和实用价值。
2025-01-15🌱上海: ☀️ 🌡️+6°C 🌬️↓18km/h
# Redis 中跳表的实现原理是什么?
# 总结分析
# 什么是跳跃链表(跳表)
-
跳表由多层链表组成,底层存所有元素,上层是下层子集。
-
插入操作:从最高层找位置,随机确定新节点层数,插入并更新指针。
-
删除操作:从最高层找节点,在各层更新指针以保持结构。
-
查找操作:从最高层开始逐层向下,效率高,时间复杂度为 O (logn)。
# 扩展知识
首先回顾下单链表,对于有序链表,若要查找其中某个数据,只能从头到尾遍历,这种方式查找效率低,时间复杂度为 O (n)。

在单链表中,查找一个数需从头结点开始依次遍历匹配,时间复杂度为 O (n);插入一个数时,先从头遍历找到合适位置再插入,时间复杂度同样是 O (n)。这表明单链表在查找和插入操作上效率相对较低,随着链表长度增加,耗时会线性增长。
为了提高查询效率,对有序链表进行改造,先对链表中每两个节点建立第一级索引。如下图

假设我们要找15这个值,跳表是的查询流程如下图
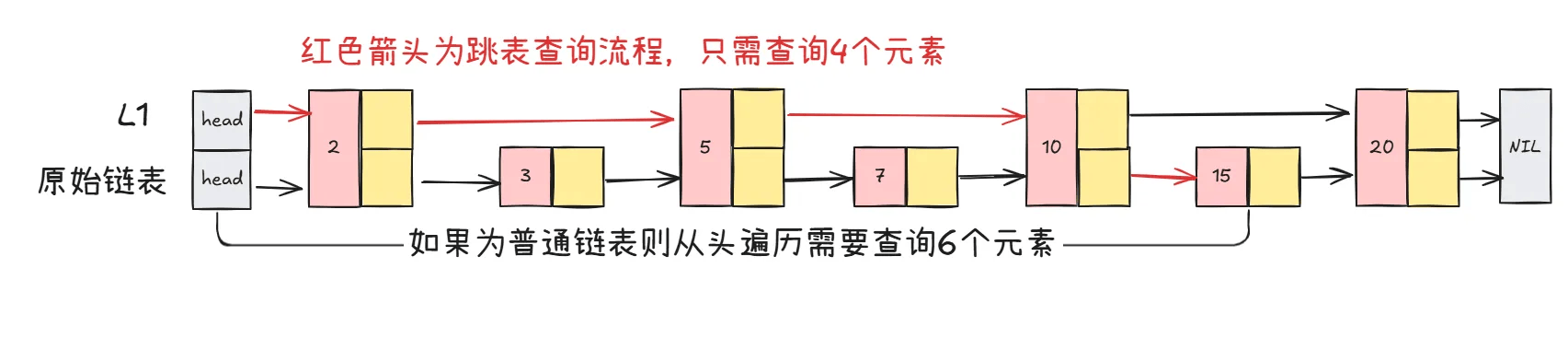
加来一层索引之后,查找一个结点需要遍的结点个数减少了,也就是说查找效率提高了,同理再加一级索引。

从图中能看出查找效率得到提升,在数据量少的例子中已有体现;当存在大量数据时,通过增加多级索引,查找效率可获得明显提升
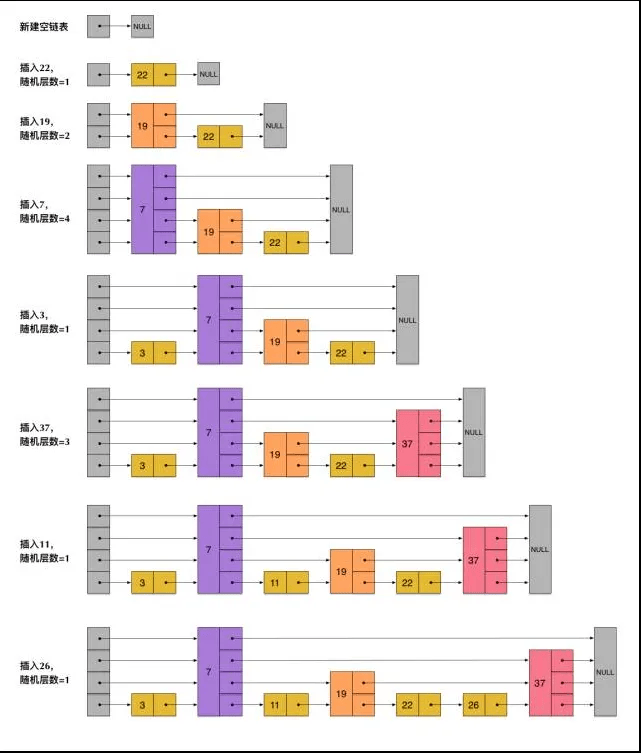
# 插入实现
以上知识跳表查询的实现,插入的实现如下图:
# Redis 中的跳表实现解析(通过源码进一步分析)
# 1.1. 基本概念
- 跳表:是一种基于链表的多层数据结构,每一层都是一个有序的链表。最底层的链表包含所有的元素,而高层的链表是底层链表的 “快速通道”,通过跳过一些节点来加快查找速度。
- 节点:跳表中的每个节点包含多个字段,其中最重要的是指向其他节点的指针数组(用于不同层次的链表),以及存储的数据和分值(用于排序)。
# 1.2. 结构示例
# 跳表节点
Redis 的跳表相对于普通的跳表多了一个回退指针,且 score 可以重复。
首先看下Redis中的跳表节点代码实现
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//后退指针
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;结构如下图:
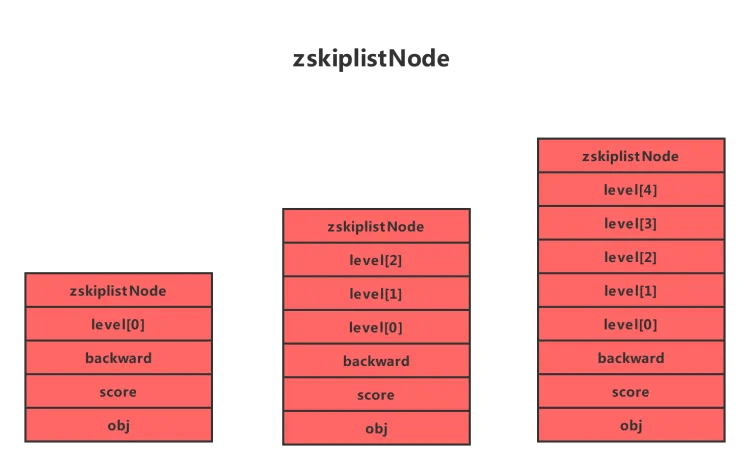
分析一下几个属性的含义:
- ele:采用 Redis 字符串底层实现 sds,用于存储数据。
- score:表示节点的分数,数据类型为 double 浮点型。
- backward:zskiplistNode 结构体指针类型,指向跳表的前一个节点。
- level:zskiplistNode 的结构体数组,数组索引即层级索引;其中 forward 指向同一层的下一个跳表节点,span 表示距离下一个节点的步数 。
跳表是有层级关系的链表,每层可有多个节点,节点间通过指针连接,这依赖跳表节点结构体中的 zskiplistLevel 结构体类型的 level 数组。level 数组每个元素代表跳表一层,如 level[0] 为第一层,level[1] 为第二层。zskiplistLevel 结构体定义了指向下一个跳表节点的指针和跨度,跨度用于记录节点间距离。
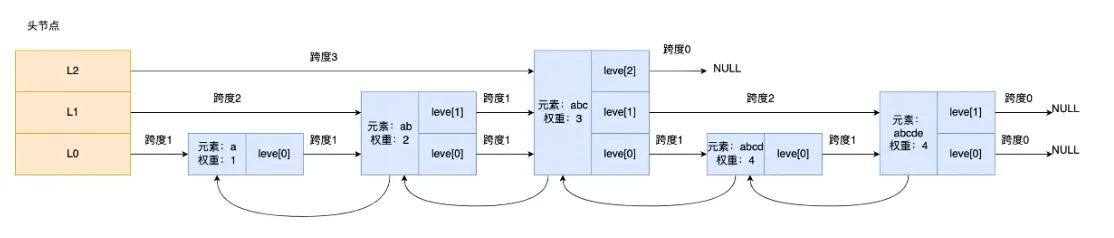
- 跨度与遍历操作并无关联,遍历依靠前向指针就能完成。
- 跨度用于计算节点在跳表中的排位,做法是在从头节点到目标节点的查询路径上,累加沿途各层跨度。
- 以节点 3 为例,经过一层(L2)且跨度为 3,其排位是 3。
- 这里需要指出的是,表头节点是一个包含了所有层的虚拟节点(不包含任何数据),每一层中表头节点的forward都指向该层的第一个真实节点。
上面是跳表节点的具体实现,接下来我们看下跳表的结构实现。
# 跳表
先看下代码实现
typedef struct zskiplist{
struct zskiplistNode *header, *tail,
unsigned long length,
int level;
} zskiplist;跳表结构包含:
- 头尾节点,可在 O (1) 时间复杂度内访问跳表的头、尾节点。
- 跳表的长度,能在 O (1) 时间复杂度获取跳表节点数量。
- 跳表的最大层数,可在 O (1) 时间复杂度获取跳表中层高最大节点的层数量 。
接下来根据更具体的实现来分析下跳表的查询过程
-
查找跳表节点从跳表头节点的最高层开始,逐一遍历每一层。
-
遍历某一层节点时,依据节点中 SDS 类型元素和元素权重进行判断:
-
若当前节点权重「小于」要查找的权重,访问该层下一个节点。
-
若当前节点权重「等于」要查找的权重且当前节点 SDS 类型数据「小于」要查找的数据,访问该层下一个节点。
-
若上述两个条件都不满足或下一个节点为空,使用当前遍历节点 level 数组里的下一层指针,跳到下一层继续查找 。
如图:
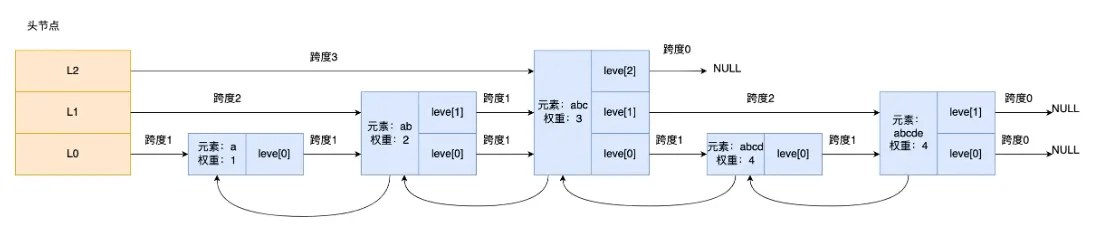
查找「元素:abcd,权重:4」的节点时:
- 从跳表头节点最高层 L2 开始,指向「元素:abc,权重:3」节点,因其权重小于目标权重,访问下一个节点,却发现下一个节点为空。
- 跳到「元素:abc,权重:3」节点的下一层 leve [1],其下一个指针指向「元素:abcde,权重:4」节点,虽权重相同,但该节点 SDS 类型数据大于目标数据,继续跳到下一层 leve [0]。
- 在 leve [0] 层,「元素:abc,权重:3」节点的下一个指针指向「元素:abcd,权重:4」节点,找到目标节点,查询结束。
# 跳表的创建
先上源码
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
// 初始化头节点, O(1)
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 初始化层指针,O(1)
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}创建跳跃表函数有几点说明:
ZSKIPLIST_MAXLEVEL为跳跃表最大层数,源码通过宏定义设为 32,节点再多也不会超 32 层。- 初始化头节点时,由于节点最多 32 层,所以先建立好 32 层链表对应的头节点,其余简单初始化工作未赘述 。
其中,**ZSKIPLIST_MAXLEVEL** 定义的是最高的层数,Redis 7.0 定义为 32,Redis 5.0 定义为 64,Redis 3.0定义为 32。
# 跳表的插入
zskiplistNode *zslInsert(zskiplist *zsl, double score, robj *obj) {
// 记录寻找元素过程中,每层能到达的最右节点
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
// 记录寻找元素过程中,每层所跨越的节点数
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
redisAssert(!isnan(score));
x = zsl->header;
// 记录沿途访问的节点,并计数 span 等属性
// 平均 O(log N) ,最坏 O(N)
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 右节点不为空
while (x->level[i].forward &&
// 右节点的 score 比给定 score 小
(x->level[i].forward->score < score ||
// 右节点的 score 相同,但节点的 member 比输入 member 要小
(x->level[i].forward->score == score &&
compareStringObjects(x->level[i].forward->obj,obj) < 0))) {
// 记录跨越了多少个元素
rank[i] += x->level[i].span;
// 继续向右前进
x = x->level[i].forward;
}
// 保存访问节点
update[i] = x;
}
/* we assume the key is not already inside, since we allow duplicated
* scores, and the re-insertion of score and redis object should never
* happpen since the caller of zslInsert() should test in the hash table
* if the element is already inside or not. */
// 因为这个函数不可能处理两个元素的 member 和 score 都相同的情况,
// 所以直接创建新节点,不用检查存在性
// 计算新的随机层数
level = zslRandomLevel();
// 如果 level 比当前 skiplist 的最大层数还要大
// 那么更新 zsl->level 参数
// 并且初始化 update 和 rank 参数在相应的层的数据
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
// 创建新节点
x = zslCreateNode(level,score,obj);
// 根据 update 和 rank 两个数组的资料,初始化新节点
// 并设置相应的指针
// O(N)
for (i = 0; i < level; i++) {
// 设置指针
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
// 设置 span
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
// 更新沿途访问节点的 span 值
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 设置后退指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
// 设置 x 的前进指针
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
// 这个是新的表尾节点
zsl->tail = x;
// 更新跳跃表节点数量
zsl->length++;
return x;
}以上代码流程总结:
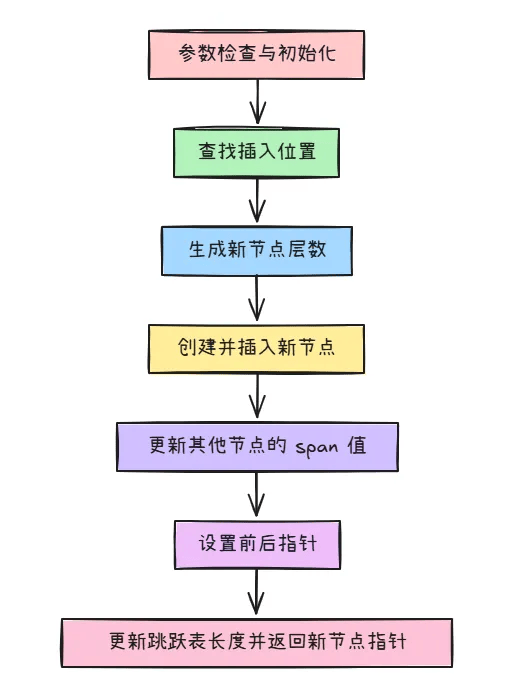
- 参数检查与初始化:确保插入节点的分数
score不是NaN,初始化遍历指针x指向跳跃表的头节点,定义update数组记录每层查找的最右节点,rank数组记录每层跨越的节点数。 - 查找插入位置:从跳跃表的最高层开始,逐层向下查找插入位置。在每一层中,找到满足条件的最右节点,记录该节点到
update数组,并更新rank数组记录跨越的节点数。 - 生成新节点层数:使用
zslRandomLevel函数生成新节点的随机层数。若新节点层数大于当前跳跃表最大层数,更新跳跃表最大层数,并初始化新增层的update和rank数组数据。 - 创建并插入新节点:创建新节点,根据
update和rank数组信息,在每一层中插入新节点,设置forward指针和span值。 - 更新其他节点的
**span**值:对于未触及的层,更新update节点的span值。 - 设置前后指针:设置新节点的
backward指针,若新节点有下一个节点,设置下一个节点的backward指针指向新节点;否则更新跳跃表的tail指针。 - 更新跳跃表长度:跳跃表节点数量加一,返回插入的新节点指针。
上面代码中有一个生成随机层数的函数
redis的跳跃表在插入节点时,会随机生成节点的层数,通过控制每一层的概率,控制每一层的节点个数,也就是保证第一层的节点个数,之后逐层增加
这里面有一个宏定义ZSKIPLIST_P ,在源码中定义为了0.25,所以,上面这段代码,生成n+1的概率是生成n的概率的4倍。
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}如果生成的新节点层数大于当前跳跃表的最大层数,由于之前的遍历是从当前最大层数开始,多出来的层尚未获取 update 节点和 rank。因此需通过特定程序为这些多出来的层写入相应的 rank 和 update 节点。这一过程较为简单,多出来层的 update 节点为头节点,rank 都为 0 ,span 被设置为当前跳跃表的节点个数(为后续插入新节点时计算新节点的 span 做准备)。
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}# 跳表的查询遍历
// 记录寻找元素过程中,每层能到达的最右节点
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
// 记录寻找元素过程中,每层所跨越的节点数
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
redisAssert(!isnan(score));
x = zsl->header;
// 记录沿途访问的节点,并计数 span 等属性
// 平均 O(log N) ,最坏 O(N)
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 右节点不为空
while (x->level[i].forward &&
// 右节点的 score 比给定 score 小
(x->level[i].forward->score < score ||
// 右节点的 score 相同,但节点的 member 比输入 member 要小
(x->level[i].forward->score == score &&
compareStringObjects(x->level[i].forward->obj,obj) < 0))) {
// 记录跨越了多少个元素
rank[i] += x->level[i].span;
// 继续向右前进
x = x->level[i].forward;
}
// 保存访问节点
update[i] = x;
}这里创建了两个数组,数组大小都是最大层数,其中:
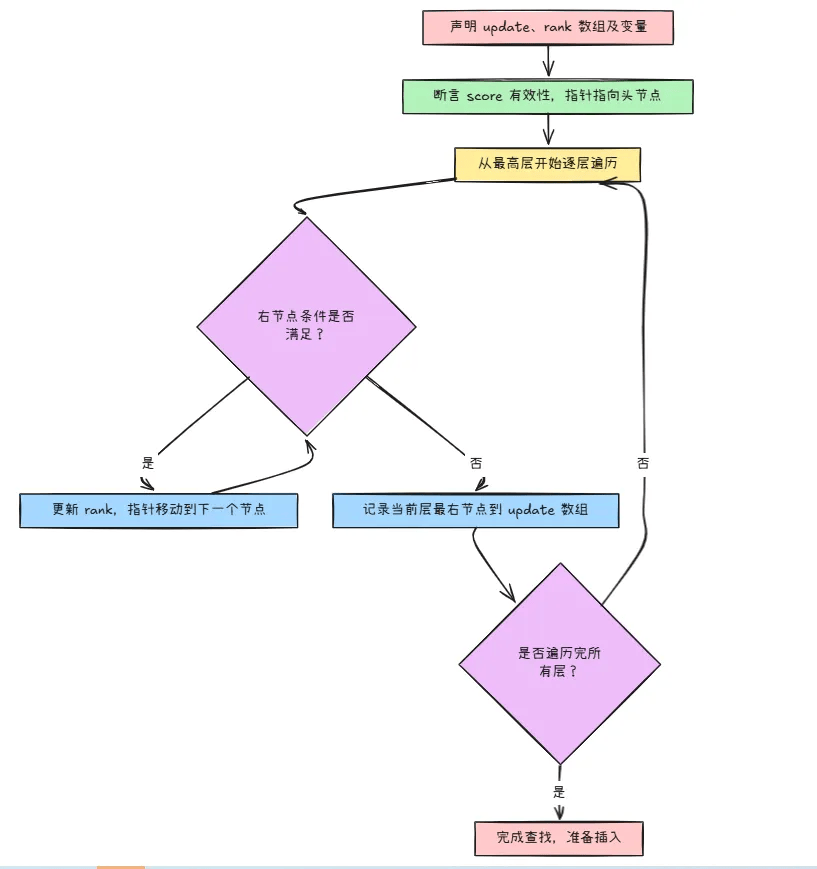
- update数组用来记录新节点在每一层的上一个节点,也就是新节点要插到哪个节点后面;
- rank数组用来记录update节点的排名,也就是在这一层,update节点到头节点的距离,这个上一节说过,是为了用来计算span
代码分析
- 变量声明:
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;:声明了一个update数组,用于存储在每一层查找过程中能到达的最右节点;x是用于遍历跳跃表的指针。unsigned int rank[ZSKIPLIST_MAXLEVEL];:声明rank数组,用于记录在每一层查找过程中跨越的节点数。int i, level;:声明循环变量i和用于存储新节点层数的level。
- 初始化与断言:
redisAssert(!isnan(score));:断言输入的分数score不是NaN(非数字),确保数据的有效性。x = zsl->header;:将遍历指针x初始化为跳跃表的头节点。
- 查找插入位置:
-
外层
for循环从跳跃表的最高层(zsl->level - 1)开始,逐层向下遍历到最低层(0)。 -
在每次循环中,根据当前层是否为最高层来初始化
rank[i]:如果是最高层,rank[i] = 0;否则,rank[i] = rank[i + 1]。 -
内层
while循环在当前层中查找满足条件的节点: -
当当前节点的下一个节点存在,且下一个节点的
score小于给定的score,或者下一个节点的score等于给定的score且其member小于输入的member时,执行循环体。 -
在循环体中,将当前节点的
span值累加到rank[i]中,以记录跨越的节点数,然后将x移动到下一个节点。 -
内层
while循环结束后,将当前层遍历到的最右节点存储到update[i]中
# 跳表的删除
老规矩 先上源码
/*
* 内部函数,被 zslDelete、zslDeleteRangeByScore 和 zslDeleteRangeByRank 使用
* 功能:从跳跃表中删除指定节点,并更新相关节点的跨度和指针
* 参数:
* - zsl: 指向跳跃表的指针
* - x: 要删除的节点
* - update: 一个数组,记录每层中查找过程中到达的最后一个节点,用于后续指针更新
*/
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
// 遍历跳跃表的每一层
for (i = 0; i < zsl->level; i++) {
// 如果当前层的 update[i] 节点的下一个节点是要删除的节点 x
if (update[i]->level[i].forward == x) {
// 更新 update[i] 节点的跨度
update[i]->level[i].span += x->level[i].span - 1;
// 将 update[i] 节点的下一个节点直接指向 x 的下一个节点
update[i]->level[i].forward = x->level[i].forward;
} else {
// 如果当前层的 update[i] 节点的下一个节点不是 x,说明 x 在这一层对 update[i] 的跨度没有影响,只需要将跨度减 1
update[i]->level[i].span -= 1;
}
}
// 如果要删除的节点 x 的下一个节点存在
if (x->level[0].forward) {
// 将 x 的下一个节点的前驱指针指向 x 的前驱节点
x->level[0].forward->backward = x->backward;
} else {
// 如果 x 没有下一个节点,说明 x 是尾节点,更新跳跃表的尾节点为 x 的前驱节点
zsl->tail = x->backward;
}
// 如果跳跃表的层数大于 1 且最高层的头节点的下一个节点为空
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
// 减少跳跃表的层数
zsl->level--;
// 跳跃表的节点数减 1
zsl->length--;
}
/*
* 从跳跃表中删除具有匹配分数和元素的节点
* 参数:
* - zsl: 指向跳跃表的指针
* - score: 要删除节点的分数
* - ele: 要删除节点的元素
* - node: 指向指针的指针,如果为 NULL,删除节点后会释放该节点;否则,将该指针设置为被删除的节点指针,供调用者重用该节点
* 返回值:
* - 如果找到并删除节点,返回 1
* - 否则,返回 0
*/
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
// 从跳跃表的头节点开始遍历
x = zsl->header;
// 从最高层开始,逐层向下遍历
for (i = zsl->level-1; i >= 0; i--) {
// 在当前层中,找到满足条件的节点
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
// 移动到下一个节点
x = x->level[i].forward;
}
// 记录当前层遍历到的最后一个节点
update[i] = x;
}
// 继续移动到下一层的第一个节点,准备检查是否是要删除的节点
x = x->level[0].forward;
// 如果找到的节点存在,且分数和元素都匹配
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
// 调用 zslDeleteNode 函数删除节点
zslDeleteNode(zsl, x, update);
// 如果 node 为 NULL,说明调用者不需要重用该节点,释放该节点
if (!node)
zslFreeNode(x);
else
// 如果 node 不为 NULL,将 *node 设置为被删除的节点指针,供调用者重用
*node = x;
// 返回 1 表示成功删除节点
return 1;
}
// 如果没有找到匹配的节点,返回 0
return 0;
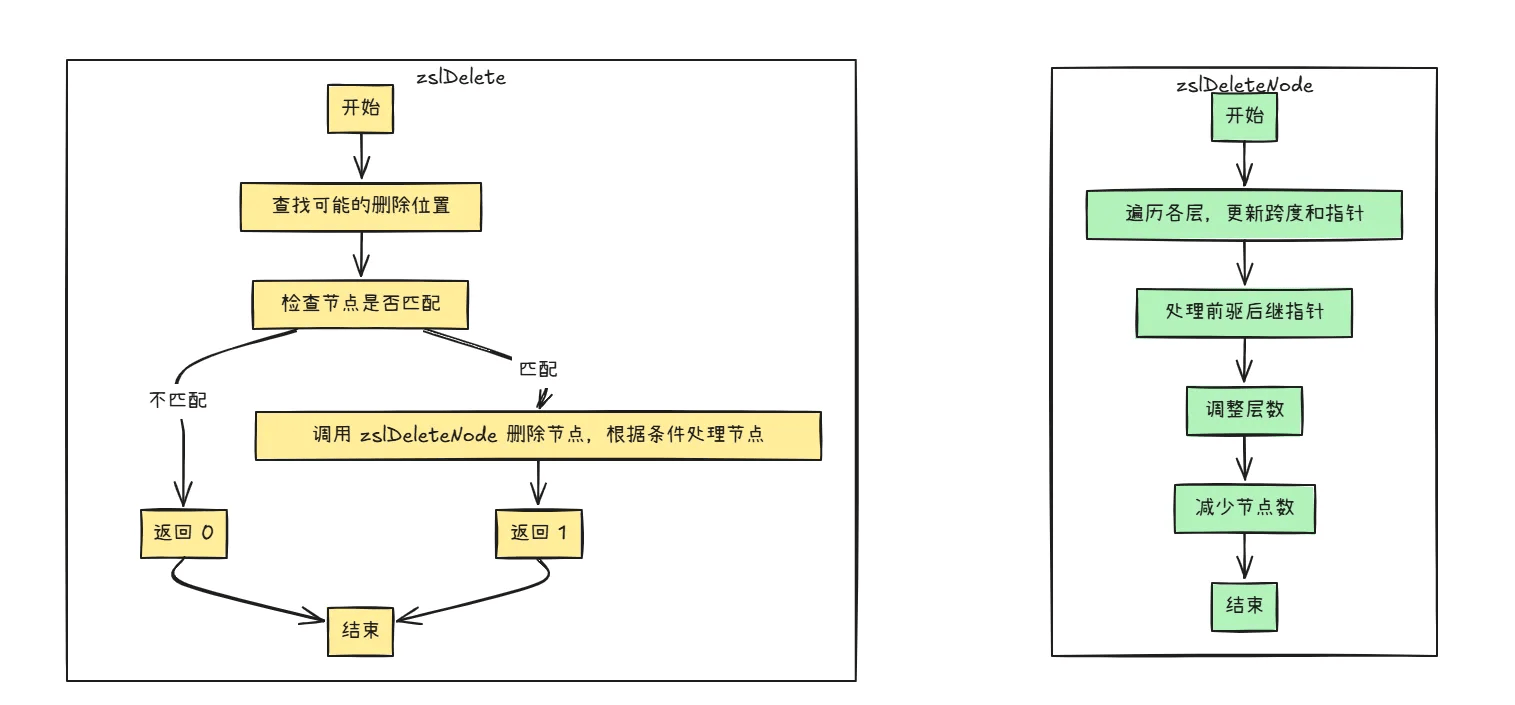
}zslDeleteNode函数负责从跳跃表中删除指定节点,并更新相关节点的跨度和指针,同时根据情况调整跳跃表的层数和节点数。zslDelete函数用于在跳跃表中查找具有特定分数和元素的节点,并调用zslDeleteNode函数进行删除操作,最后根据是否找到匹配节点返回相应的结果。
# Redis的Hash是什么?
# 总结分析
Redis 的 hash 是一种键值对集合,可以将多个字段和值存储在同一个键中,便于管理一些关联数据。 特点如下:
- 适合存储小数据,使用哈希表实现,能够在内存中高效存储和操作。
- 支持快速的字段操作(如增、删、改、查),非常适合存储对象的属性。
# 扩展知识
# Hash常用命令
HSET:设置 hash 中指定字段的值。
HSET user:1001 name "Muzi"HGET:获取 hash 中指定字段的值。
HGET user:1001 nameHMSET:一次性设置多个字段的值。
HMSET user:1001 name "Muzi" age "18" city "shanghai"HMGET:一次性获取多个字段的值。
HMGET user:1001 name ageHDEL:删除 hash 中的一个或多个字段。
HDEL user:1001 ageHINCRBY:为 hash 中的字段加上一个整数值。
HINCRBY user:1001 age 1测试示例
127.0.0.1:6379> HSET user:1001 name "Muzi"
(integer) 1
127.0.0.1:6379> HGET user:1001 name
"mianshiya"
127.0.0.1:6379> HMSET user:1001 name "Muzi" age "18" city "shanghai"
OK
127.0.0.1:6379> HMGET user:1001 name age
1) "Muzi"
2) "18"
127.0.0.1:6379> HDEL user:1001 age
(integer) 1
127.0.0.1:6379> HSET user:1001 age 18
(integer) 1
127.0.0.1:6379> HINCRBY user:1001 age 1
(integer) 19
127.0.0.1:6379> HGET user:1001 age
"19"# Hash 底层实现解析
- Hash 是 Redis 基础数据结构,类似哈希表,能存约 40 亿个键值对。
- 底层结构:Redis 6 及之前为 ziplist + hashtable,Redis 7 之后是 Listpack + hashtable。
- ziplist 和 listpack 查找 key 时间复杂度均为 O (n),listpack 解决 ziplist 级联更新问题。
- Redis 有
hash-max-ziplist-entries(hash-max-listpack-entries)和 hash-max-ziplist-value(hash-max-listpack-value)两个值,默认分别为 512 和 64。 - 当 hash 字段个数及字段名、值长度小于上述值时,用 listpack 或 ziplist 存储;大于则用 hashtable 存储,且用 hashtable 后不再退回。
# Redis中的Hashtable分析
- 哈希表是用于存储键值对(key - value)的数据结构,每个 key 具有唯一性,支持基于 key 的查询、更新和删除操作。
- Redis 的 Hash 对象底层实现包括压缩列表ziplicst(已被 listpack 替代)和哈希表hashtable。
- 哈希表的优势在于能以 O (1) 的时间复杂度快速查询数据,通过 Hash 函数计算 key 来确定数据在数组中的位置。
- 然而,在哈希表大小固定的情况下,随着数据量增加,哈希冲突的可能性也会增大。
- Redis 采用 “链式哈希” 策略解决哈希冲突,在不扩大哈希表的前提下,将哈希值相同的数据连接成链表,以保证数据可被查询
# hashtable结构
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有的节点数量
unsigned long used;
} dictht;table:存储元素的哈希表结构,由哈希节点dictEntry组成的数组。size:哈希表的大小。sizemask:大小掩码,值为size - 1,与哈希值共同确定节点在哈希表中的位置(index = hash & sizemask)。used:已使用的节点数量 。
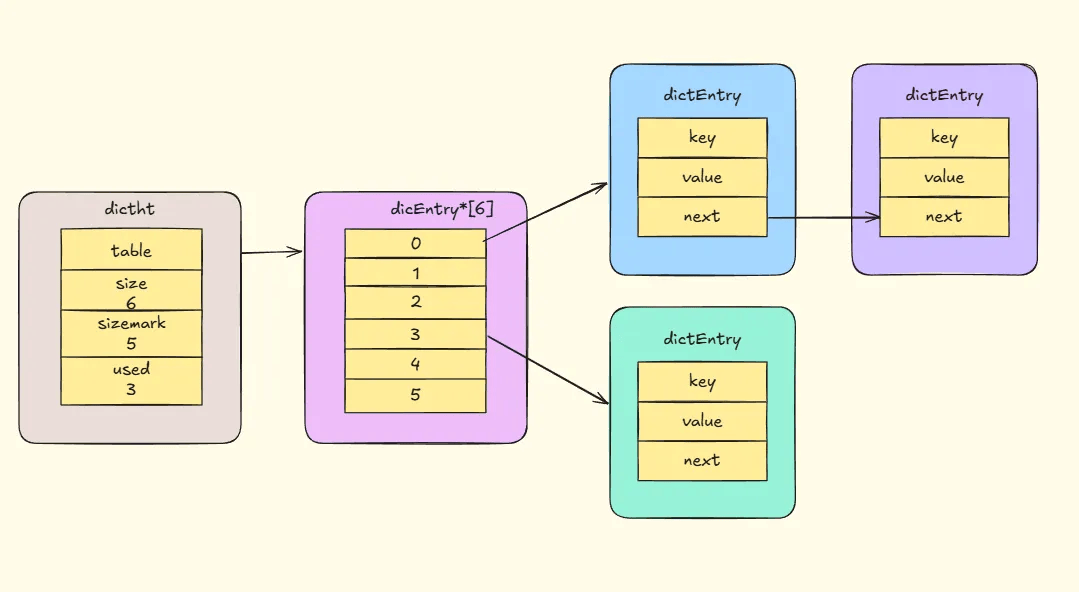
# 哈希节点dictEntry结构
typedef struct dictEntry {
//键值对中的键
void *key;
//键值对中的值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;dictEntry结构不仅有指向键和值的指针,还包含指向下一个哈希表节点的指针,通过将多个哈希值相同的键值对链接起来解决哈希冲突,这就是链式哈希。dictEntry结构中键值对的值由「联合体 v」定义,值可以是指向实际值的指针,也可以是无符号 64 位整数、有符号 64 位整数或double类型的值。这种设计能节省内存空间,当值为整数或浮点数时,可将值内嵌在dictEntry结构中,无需额外指针指向实际值 。
联合体和结构体的区别及定义(大概了解即可)
struct 结构体名 {
数据类型 成员名1;
数据类型 成员名2;
// 可以有更多成员
};union 联合体名 {
数据类型 成员名1;
数据类型 成员名2;
// 可以有更多成员
};联合体与结构体的主要区别就在内存上。
- 结构体的每个成员都拥有自己独立的内存空间,结构体大小为所有成员的大小之和(不考虑内存对齐的情况)。
- 而联合体的所有成员都使用同一段内存空间,联合体大小即为联合体中最大的那个成员大小
# 哈希冲突
- 哈希表本质是数组,数组元素即哈希桶。
- 键值对的键经哈希函数计算出哈希值,再对哈希表大小取模,所得结果就是该键值对对应的数组元素位置(哈希桶)。
什么是哈希冲突呢?
其实了解hashmap的底层原理,对于hash冲突都不陌生
以一个有 8 个哈希桶的哈希表为例,说明不同键对应哈希桶的过程:key1 经哈希函数计算并对 8 取模得 1,对应哈希桶 1;key9、key10 分别对应哈希桶 1 和哈希桶 6 。如下图:
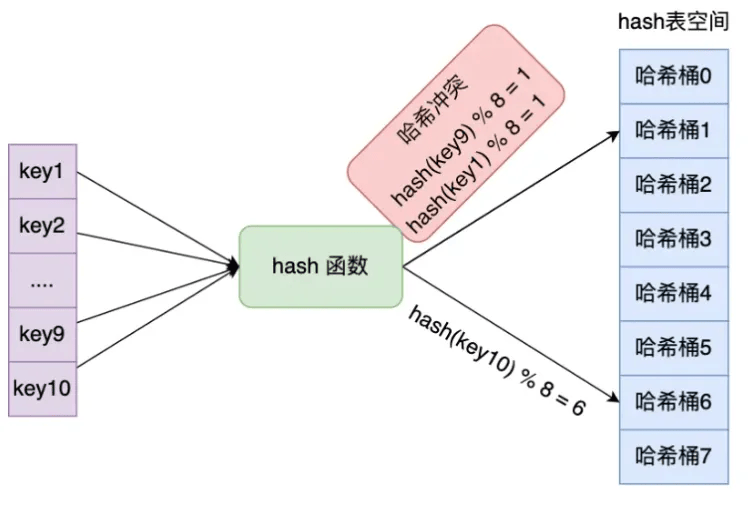
Redis采用了链式哈希的方法来解决哈希冲突,这里应该和hashmap的原理一样。
# 链式哈希
链式哈希解决哈希冲突的方式是:每个哈希表节点设 next 指针指向下一节点,可构成单向链表。同一哈希桶上的多个节点借此链表相连。如 key1 和 key9 经哈希计算落入同一哈希桶,key1 会通过 next 指针指向 key9 形成单向链表 。如下图:
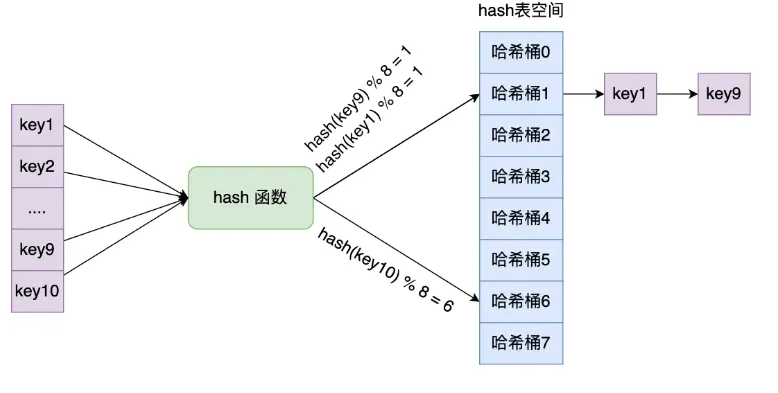
链式哈希存在局限性,随着链表长度增加,查询数据耗时会增加,其查询时间复杂度为 O (n)。解决此问题需进行 rehash(扩展哈希表大小),接下来将介绍 Redis 实现 rehash 的方式。
# rehash
在介绍哈希表结构设计时,提到 Redis 用 dictht 结构体表示哈希表,而在实际使用中,Redis 定义了 dict 结构体,该结构体中包含两个哈希表(ht[2])。
typedef struct dict {
…
//两个Hash表,交替使用,用于rehash操作
dictht ht[2];
…
} dict;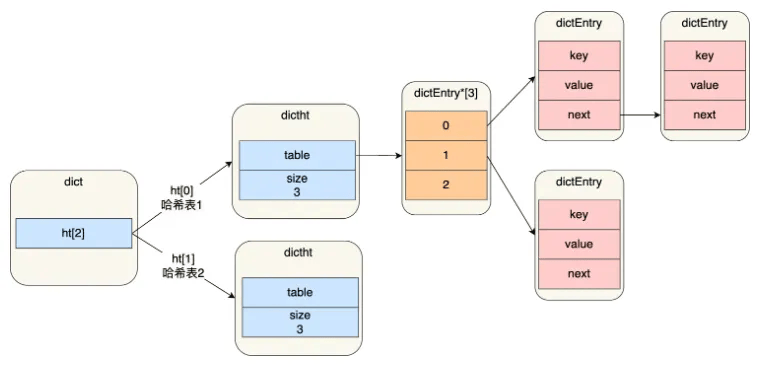
Redis 为解决哈希冲突及数组空间不足问题,采用双哈希表机制。当正在使用的哈希表节点数达到其数组长度时,会将另一个原本为空的哈希表的数组长度设为当前表的 2 倍,并把旧表节点迁移至新表,新表成为当前使用表,从而实现数组长度增长与冲突缓解,实际使用中始终保持一个表用于当前操作,另一个用于 rehash 操作。
流程如下:
- 给「哈希表 2」分配比「哈希表 1」大一倍的空间
- 将「哈希表 1」的数据迁移到「哈希表 2」中
- 释放「哈希表 1」空间,把「哈希表 2」设为「哈希表 1」,并在「哈希表 2」新创建空白哈希表为下次 rehash 做准备
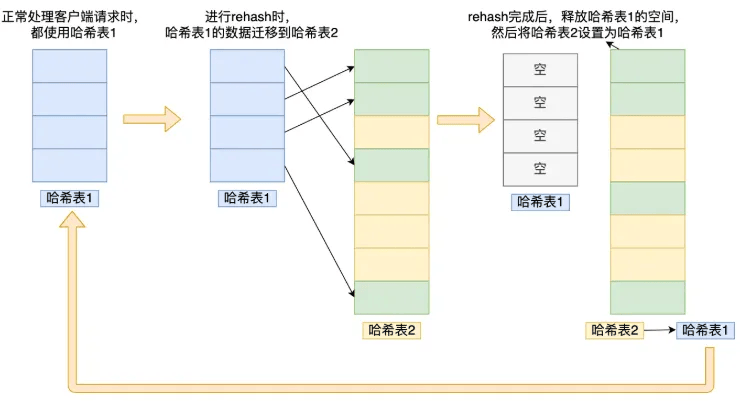
第二步可能会存在问题,当「哈希表 1」数据量巨大时,迁移数据至「哈希表 2」会因大量数据拷贝而可能阻塞 Redis,使其无法响应其他请求。所以接下来了解下渐进式rehash
# 渐进式rehash
- Redis 采用渐进式 rehash 避免 rehash 数据迁移耗时影响性能,分多次迁移数据。
- 先给 “哈希表 2” 分配空间。
- 在 rehash 期间每次哈希表操作时会将 “哈希表 1” 对应索引位置 key - value 迁移到 “哈希表 2”。
- 查找操作先在 “哈希表 1” 进行,未找到再到 “哈希表 2”。
- 新增 key - value 保存到 “哈希表 2”,“哈希表 1” 不再添加,使其 key - value 数量减少直至为空表。
# rehash触发条件
- rehash 触发条件与负载因子有关,
负载因子 = 哈希表已保存节点数量 / 哈希表大小。 - 当负载因子大于等于 1,且 Redis 未执行 bgsave 命令(RDB 快照)或 bgrewiteaof 命令(AOF 重写)时,会进行 rehash 操作。
- 当负载因子大于等于 5 时,无论 Redis 是否在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。
当负载因子小于 0.1 时,会进行缩容操作。
- 当满足特定条件进行 rehash 时,新表大小是老表
used的最近的一个 2 次方幂,如老表used = 1000,新表大小为 1024。
这种基于负载因子的动态调整机制,能根据数据量和哈希表状态自适应地优化哈希表性能,保持数据存储和检索的高效性。
# Redis Zset的实现原理是什么?
# 总结分析
- ZSet(Sorted Set)是 Redis 中特殊数据结构,内部维护有序字典,元素包含成员和 double 类型分值,可实现记分排行榜数据。
- Redis 中 ZSet 实现结构多样,以往主要有 ziplist 和 skiplist 两类。
- Redis 5.0 新增 listpack 替代 ziplist。
- 到 Redis 7.0 发布,ZSet 实现中不再使用 ziplist。
Redis 中 ZSet 存储结构会根据元素数量动态调整。元素数量较少时,采用 ZipList(ListPack)这种紧凑列表结构连续存储元素以节约内存;元素数量增多,Redis 会遍历 ZipList(ListPack)元素,按分数值依次插入到 SkipList 中,实现结构转换,以保持有序性并支持范围查询。在 ZSet 的具体实现中,SkipList 不仅使用跳表,还会用到 dict(字典) 。
- SkipList 用于实现有序集合,元素按分值大小在跳表中排序,其插入、删除和查找操作时间复杂度为 O (log n),性能较好。
- dict 用于建立元素到分值的映射关系,元素为键,分值为值,哈希表的插入、删除和查找操作时间复杂度为 O (1),性能很高。
# 扩展知识
# ZipList(ListPack)和SkipList之间是什么时候进行转换的呢?
- Redis 中 ZSET 在特定条件下使用 ziplist 作为内部表示。
- 条件一:元素数量小于 zset-max-ziplist-entries(默认 128)。
- 条件二:每个元素(含值和分数)大小小于 zset-max-ziplist-value(默认 64 字节)。
- 不满足上述条件时使用 SkipList。
# 压缩列表
- ziplist 是由特殊编码的连续内存块组成的顺序存储结构,类似数组但内存连续存储。
- 与数组不同,为节省内存,其每个元素所占内存大小可变,每个节点可存储整数或字符串。
- 类似双向链表,不存储前后节点指针,而是存储上一节点长度和当前节点长度,以牺牲部分读写性能换取高效内存利用率,达到节约内存的目的。

- zlbytes:记录了压缩列表占用的内存字节数,在对压缩列表进行内存重分配,或者计算zlend的位置时使用。它本身占了4个字节。
- zltail:记录了尾节点(entry)至起始节点(entry)的偏移量。通过这个偏移量,可以快速确定最后一个entry节点的地址。
- zllen:记录了entry节点的数量。当zllen的值小于65535时,这个值就表示节点的数量。当zllen的值大于65535时,节点的真实数量需要遍历整个压缩列表才能得出。
- entry:压缩列表中所包含的每个节点。每个节点的长度根据该节点的内容来决定。
- zlend:特殊值0XFF,标记了压缩列表的末端。表示该压缩列表到此为止。
typedef struct zlentry {
unsigned int prevrawlensize; /*存储上一个节点长度的数值所需要的字节数*/
unsigned int prevrawlen; /* 上一个节点的长度 */
unsigned int lensize; /* 当前节点长度的数值所需要的字节数*/
unsigned int len; /* 当前节点的长度 */
unsigned int headersize; /* 当前节点的头部大小,值 = prevrawlensize + lensize. */
unsigned char encoding; /* 编码方式,ZIP_STR_* 或 ZIP_INT_* */
unsigned char *p; /* 指向节点内容的指针. */
} zlentry;- 压缩列表(ziplist)的主要特点是内存空间连续,这一特性避免了内存碎片,能有效节省内存。
- entry 是链表中的节点,用于代表一个数据
Redis 中虽定义了 zlentry 结构体,但因其存储小整数或短字符串时空间浪费严重(32 位机占 28 字节、64 位机占 32 字节),不符合 ziplist 提高内存利用率的设计初衷,所以在实际操作中并未使用该结构体,而是通过定义一些宏来处理 ziplist 相关操作。如下图

- prev_entry_len:记录前驱节点的长度。
- encoding:记录当前节点的value成员的数据类型以及长度。
- value:根据encoding来保存字节数组或整数。
ziplist的特点
- ziplist 是由表头、若干 entry 节点和 zlend 组成的连续内存块结构。
- 它通过编码规则提高内存利用率,适合存储整数和短字符串。
- 其缺点是插入或删除元素时要频繁进行内存扩展或减小、数据搬移,甚至可能引发连锁更新,造成严重效率损失。
# skiplist解析
Redis 中跳表的实现原理是什么? - 木子金又二丨的回答记录 - 面试鸭 - 程序员求职面试刷题神器
其实Zset底层实现还涉及到两个数据结构:quicklist和listpack
具体详解可以参考