✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
文章系统梳理了Redis缓存与数据库数据一致性的多种实现方案,重点推荐基于先写数据库再删除缓存及结合Binlog与消息队列实现最终一致性的策略,兼顾实时性与可靠性。针对缓存击穿、穿透和雪崩三大典型问题,文章详细解析定义、危害及解决方案,包括互斥锁、布隆过滤器、随机过期时间、多级缓存等技术手段,并提供了互斥锁的Java代码示例。最后,深入剖析Redis String类型的底层实现——SDS结构及其三种编码方式(int、embstr、raw),阐述各编码的适用场景、内存布局及性能特点,揭示Redis优化存储与访问效率的设计理念,具备较高的技术参考价值。
2025-01-15🌱上海: ☀️ 🌡️+6°C 🌬️↓18km/h
# Redis 中如何保证缓存与数据库的数据一致性?
# 总结分析
缓存和数据库的同步有六种方式:
- 先更新缓存,再更新数据库;
- 先更新数据库,再更新缓存;
- 先删除缓存,再更新数据库,后续查询回种数据到缓存;
- 先更新数据库,再删除缓存,后续查询回种数据到缓存;
- 缓存双删策略:更新数据库前后各进行一次删除缓存操作,第二次为延迟删除;
- 使用定时任务进行重试删除缓存
- 使用MQ异步定时重试删除缓存
- 使用 Binlog 异步更新缓存,监听数据库 Binlog 变化异步更新 Redis 缓存。
前三种方式不太推荐。后三种方式需根据实际场景选择:
- 追求实时一致性,优先选择先写 MySQL,再删除 Redis 的方案,虽短期内数据可能不一致,但能尽量保证数据一致性。
- 考虑最终一致性,推荐使用 binlog + 消息队列的方式,该方案具备重试和顺序消费功能,能最大限度保证缓存与数据库的最终一致性。
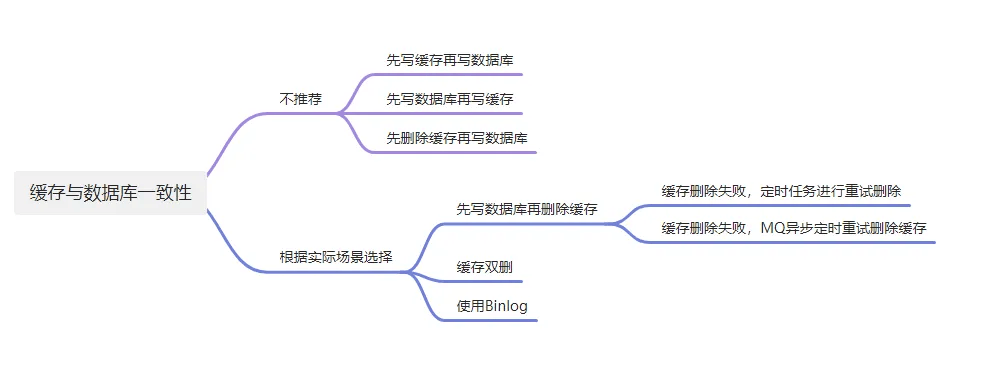
之前我对于这个问题针对上面的8个不同的解决方案进行了详细分析
详细文档方案:
# Redis 中的缓存击穿、缓存穿透和缓存雪崩是什么?
# 总结分析
| 问题名称 | 定义 | 可能后果 | 解决方案 |
|---|---|---|---|
| 缓存击穿 | 某个热点数据在缓存中失效,大量请求直接访问数据库 | 高并发下可能导致数据库崩溃 | 1. 使用互斥锁,同一时间仅一个请求可查询并更新数据库和缓存 <br>2. 热点数据设置为永不过期 |
| 缓存穿透 | 查询不存在的数据,缓存无记录,每次请求都查询数据库 | 加重数据库负担 | 1. 使用布隆过滤器过滤不存在请求 <br>2. 对查询结果(包括不存在数据)进行缓存,减少数据库请求 |
| 缓存雪崩 | 多个缓存数据在同一时间过期,大量请求同时访问数据库 | 数据库瞬间负载激增 | 1. 采用随机过期时间策略,防止数据同时过期 <br>2. 使用双缓存策略,将数据存储在两层缓存中,减少对数据库的直接请求 |
# 扩展知识
# 缓存击穿
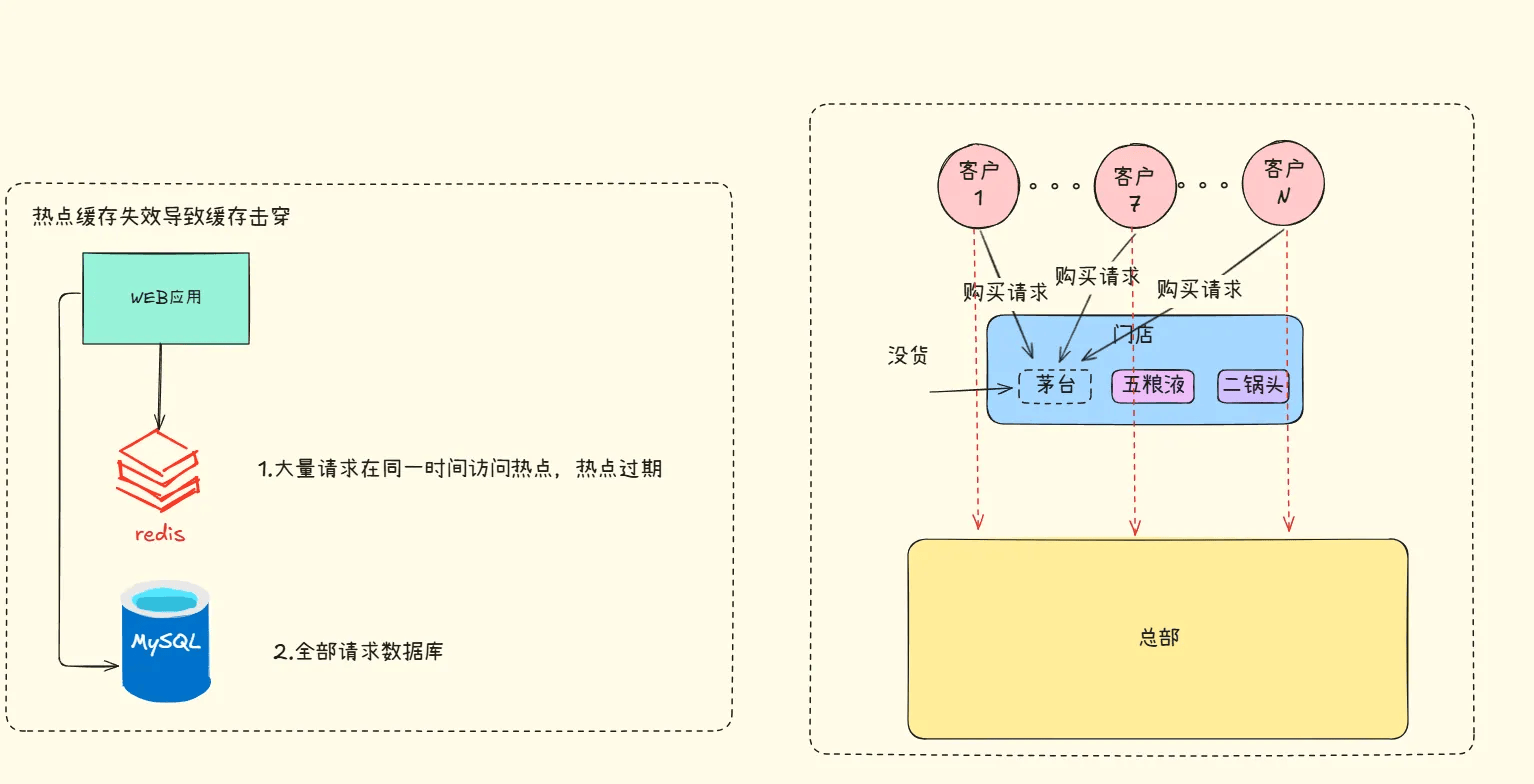
缓存击穿是指当某一key的缓存过期时大并发量的请求同时访问此key,瞬间击穿缓存服务器直接访问数据库,让数据库处于负载的情况。
# 解决方案
# 异步定时更新
通过上图 ,对于已知畅销的酒,可通过定时咨询总部、更新库存情况来避免可能出现的问题。
在缓存处理方面,针对过期时间为 1 小时的热点数据,可每 59 分钟通过定时任务更新热点 key 并重新设置过期时间 ,或者就是不给热点数据设置过期时间。
# 互斥锁
对于顾客集中咨询同一款酒的情况,处理方式是先处理首位顾客咨询,其余相同请求的顾客排队,待店员获取总部最新库存信息后再安排后续购买。
在缓存处理中,针对缓存击穿问题,常用互斥锁解决。即当 Redis 中依据 key 获取的 value 值为空时,先上锁,接着从数据库加载数据,加载完成后释放锁;其他线程请求该 key 时,若获取锁失败则先阻塞等待。
# 缓存穿透
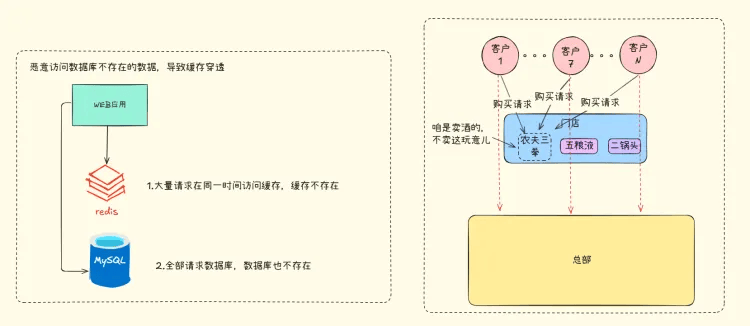
缓存穿透是指缓存服务器中没有缓存数据,数据库中也没有符合条件的数据,导致业务系统每次都绕过缓存服务器查询下游的数据库,缓存服务器完全失去了其应用的作用。
攻击者可以通过构造不存在的 key 发起大量请求,对数据库造成很大的压力,可能会造成系统宕机。
# 空值
对于卖酒门店咨询库存问题,为避免多次询问总部,在帮第一个客户查询得知不卖农夫三拳后,记录该无货信息,后续其他顾客询问直接告知。
在缓存方面,缓存穿透是因未缓存不存在值的 Key,导致每次查询都请求数据库。解决办法是将这类 Key 对应的值设为 null 存入缓存,查询时直接返回 null,但要设置失效时间,以防总部真的要卖农夫三拳的时候影响销量。
# 防止非法请求
检查非法请求,封禁其 IP 以及账号,对于恶意大量请求,记录其ip的信息,进行限制,避免对我们的服务器造成危害。
# 布隆过滤器(BloomFilter)
在实际场景中,店员对顾客询问不存在商品可直接告知
缓存穿透可能源于恶意流量请求随机生成众多在缓存和数据库中均不存在的 Key 。对此,可采用过滤器应对。
在技术领域,常用布隆过滤器防治。它是一种概率性数据结构,利用多个哈希函数将元素映射成多位并置为 1,能判断元素一定不存在或可能存在,相比传统数据结构更省内存、高效。用于缓存穿透防治时,可将查询数据条件哈希到布隆过滤器,拦截一定不存在的数据请求,减轻数据库压力 。
# 布隆过滤器分析(了解即可)
-
布隆过滤器是一种用于快速检索元素是否可能存在于集合(bit 数组)中的数据结构。
-
原理是利用多个哈希函数将元素映射成多个位,并将这些位设置为 1。
-
查询元素时,若对应位都为 1,则认为元素可能存在;否则,元素肯定不存在。
-
布隆过滤器能准确判断元素一定不存在。
-
由于哈希冲突,布隆过滤器无法判断元素一定存在,只能判断可能存在。
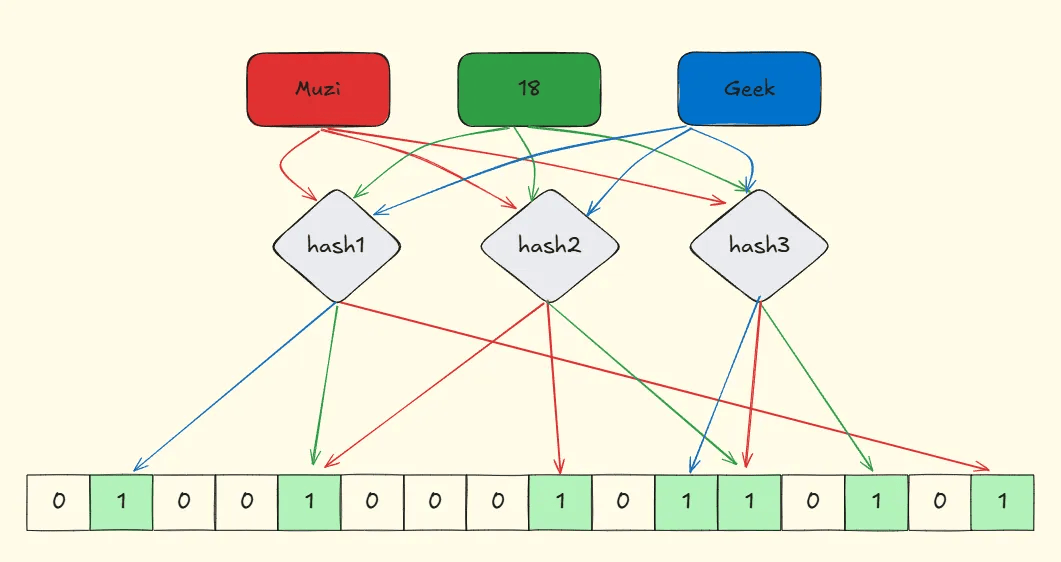
但是会不会存在一个元素三次hash都正好发生hash冲突到存在的位。如下图(概率很小)
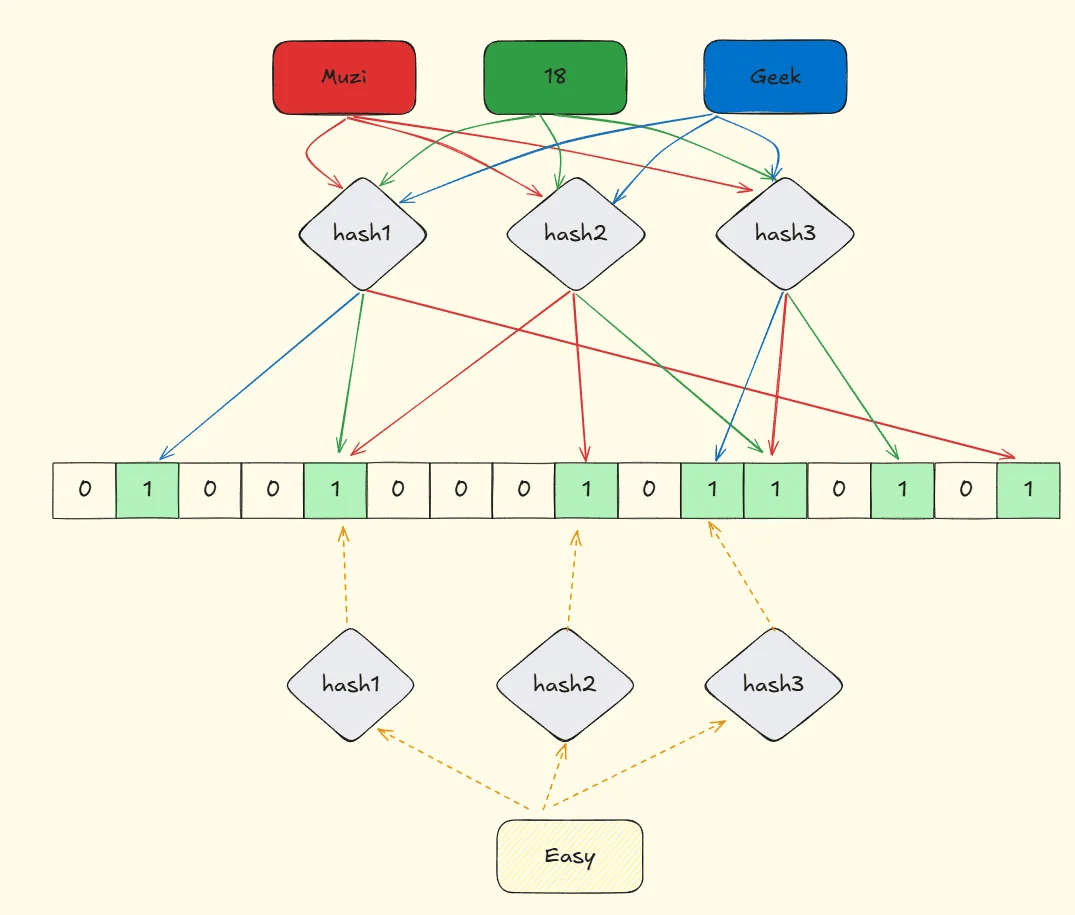
降低误判概率的办法主要通过降低哈希冲突概率及引入更多哈希算法来实现。 -
工作过程:
-
初始化:指定集合大小和误判率,内部含 bit 数组与多个哈希函数,哈希函数生成索引值。
-
添加元素:元素经多个哈希函数生成索引值,将对应位设为 1,若已为 1 则无需再设。
-
查询元素:元素经哈希函数得索引值,若对应位都为 1 则可能存在,否则肯定不存在。
-
主要优点:可快速判断元素是否属某集合,空间和时间效率高。
-
主要缺点:判断元素存在时有一定误判率,且无法删除元素,因删除元素需将对应位设为 0,但这些位可能被其他元素共享。
布隆过滤器的广泛应用场景
- 网页爬虫:用于过滤已爬取网页,防止重复爬取与资源浪费。
- 缓存系统:判断查询是否可能在缓存中,减少查询次数、提高效率,还可解决缓存穿透问题。
- 分布式系统:判断元素是否在分布式缓存中,避免全节点查询,减轻网络负载。
- 垃圾邮件过滤:判断邮件地址是否在垃圾邮件列表,过滤垃圾邮件。
- 黑名单过滤:判断 IP 地址或手机号码是否在黑名单,阻止恶意请求。
# 缓存雪崩
缓存雪崩是指当大量缓存同时过期或缓存服务宕机,所有请求的都直接访问数据库,造成数据库高负载,影响性能,甚至数据库宕机。
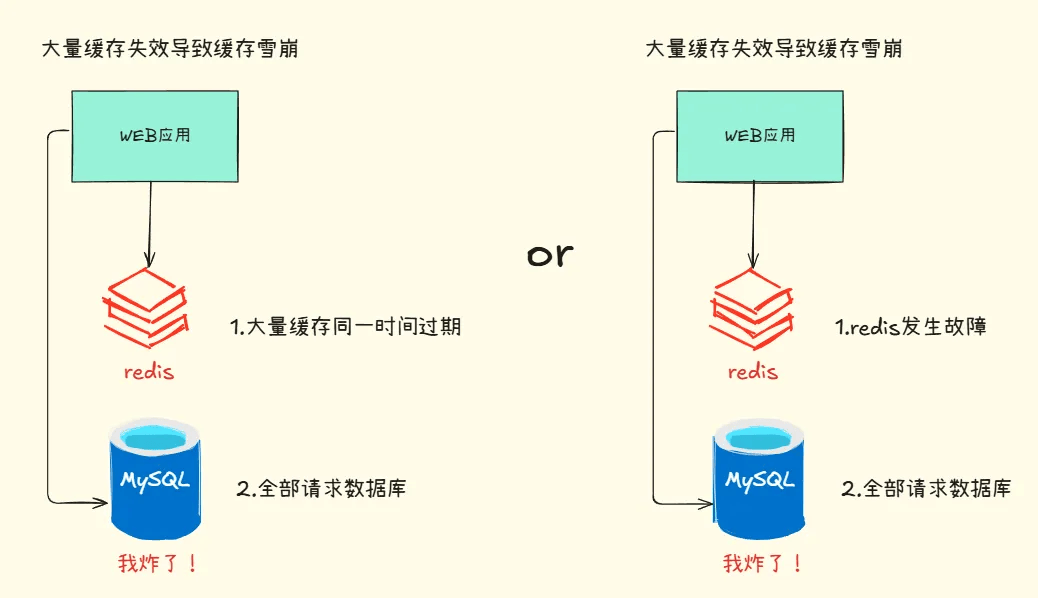
缓存键同时失效的解决办法
- 过期时间随机化:设置缓存过期时间时添加随机值,防止大量缓存同时失效。
- 使用多级缓存:结合本地缓存与分布式缓存,降低单点故障风险。
- 缓存预热:系统启动时预先加载缓存数据,避免大量请求冲击冷启动数据库。
- 加互斥锁:在无缓存或缓存失效时,确保同一时间仅一个请求构建缓存,减轻数据库压力。
缓存中间件故障的解决办法
- 服务熔断:暂停业务数据返回,直接返回错误。
- 构建集群:构建多个 Redis 集群,保障高可用性。
# 互斥锁代码示例
使用hashmap模拟redis缓存
import java.util.HashMap;
import java.util.Map;
public class CacheWithMutex {
private Map<String, Object> cache = new HashMap<>();
private boolean isFetching = false;
public Object getFromCache(String key) {
Object value = cache.get(key);
if (value == null) {
synchronized (this) {
// 再次检查,防止多个线程同时进入等待锁的状态
value = cache.get(key);
if (value == null) {
if (!isFetching) {
isFetching = true;
try {
// 模拟从数据库获取数据
Thread.sleep(2000);
value = "Data from DB for key: " + key;
cache.put(key, value);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
isFetching = false;
}
} else {
// 其他线程等待
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 唤醒其他等待的线程
this.notifyAll();
}
return value;
}
public static void main(String[] args) {
CacheWithMutex cacheWithMutex = new CacheWithMutex();
// 模拟多个线程同时请求
for (int i = 0; i < 5; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " : " + cacheWithMutex.getFromCache("key"));
}).start();
}
}
}# Redis String 类型的底层实现是什么?(SDS)
# 总结分析
Redis 中的 String 类型底层实现主要基于 SDS(Simple Dynamic String 简单动态字符串)结构,并结合 int、embstr、raw 等不同的编码方式进行优化存储
# 扩展知识
先上源码
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};- len(长度):记录 SDS 字符串数组长度,获取长度时直接返回该值,时间复杂度为 O (1)。
- alloc(分配空间长度):表示分配给字符数组的存储空间大小,通过 alloc - len 可计算剩余空间,以判断是否满足修改需求,解决缓冲区溢出问题。
- flags(SDS 的类型):设计了 sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64 五种类型,依据 2 的幂次方记忆,能灵活存储不同大小字符串,节省内存空间。
- buf(存储数据的字符数组):用于保存字符串、二进制数据等,具备二进制安全特性 。
接下来了解下redisObject结构
# redisObject结构
之前也了解过redis的底层存储结构
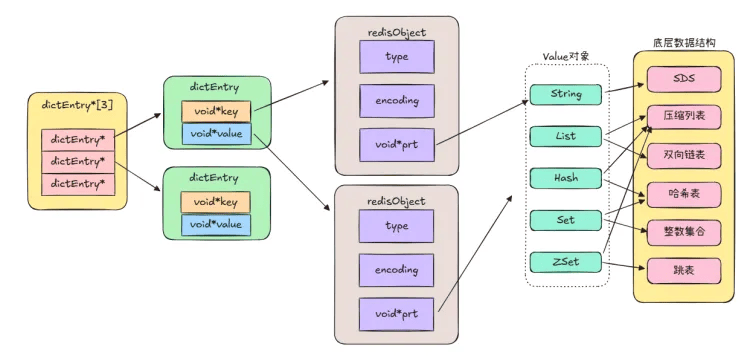
这里单独分析redisObject
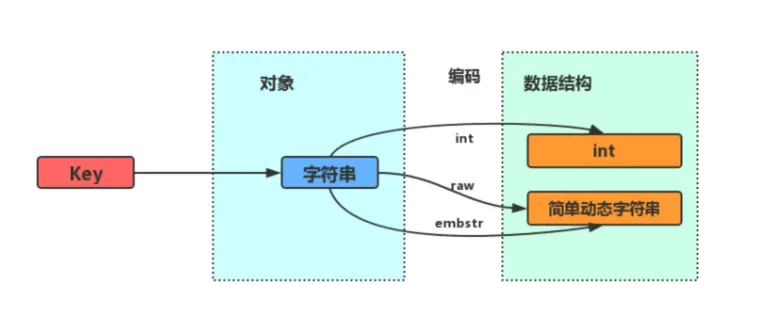
从代码可以看到有不同的编码类型(int、embstr、raw等),接下来逐一分析
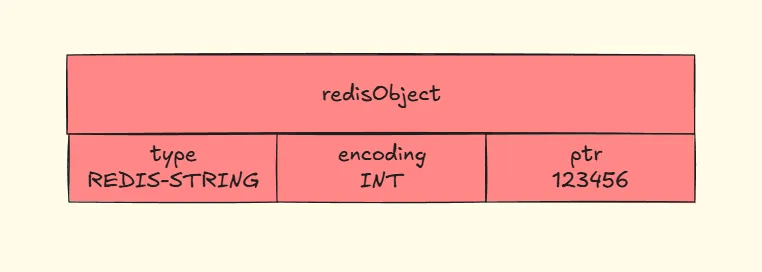
# int编码
struct redisObject {
unsigned type:4; // 数据类型(字符串、哈希等)
unsigned encoding:4; // 编码类型(int、embstr、raw等)
int64_t ptr; // 实际的数据指针,这里直接存储整数值
};若字符串对象保存的整数值能用 long 类型表示,该对象会把整数值存于结构的 ptr 属性(将 void* 转换为 long),并将编码设为 int 。
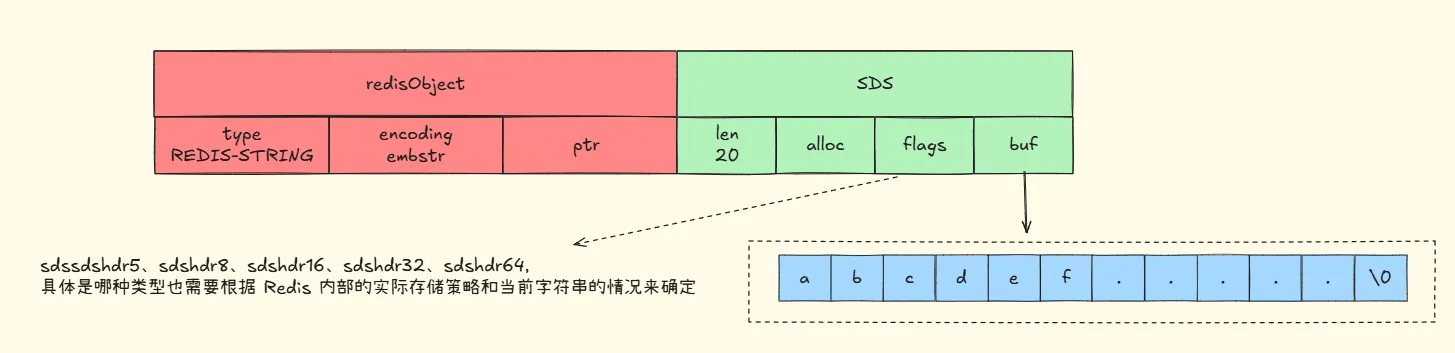
# embstr编码
struct redisObject {
unsigned type:4; // 数据类型
unsigned encoding:4; // 编码类型,这里是 embstr
void *ptr; // 指向 sdshdr 结构
};
struct sdshdr {
uint32_t len; // 当前字符串长度
uint32_t alloc; // 已分配的内存大小
unsigned char flags; // 编码类型
char buf[]; // 实际字符串数据
};若字符串对象保存的字符串长度小于等于 32 字节(Redis 2.+ 版本),会用 SDS 保存该字符串,且将对象编码设为 embstr,embstr 是专为保存短字符串的优化编码方式。
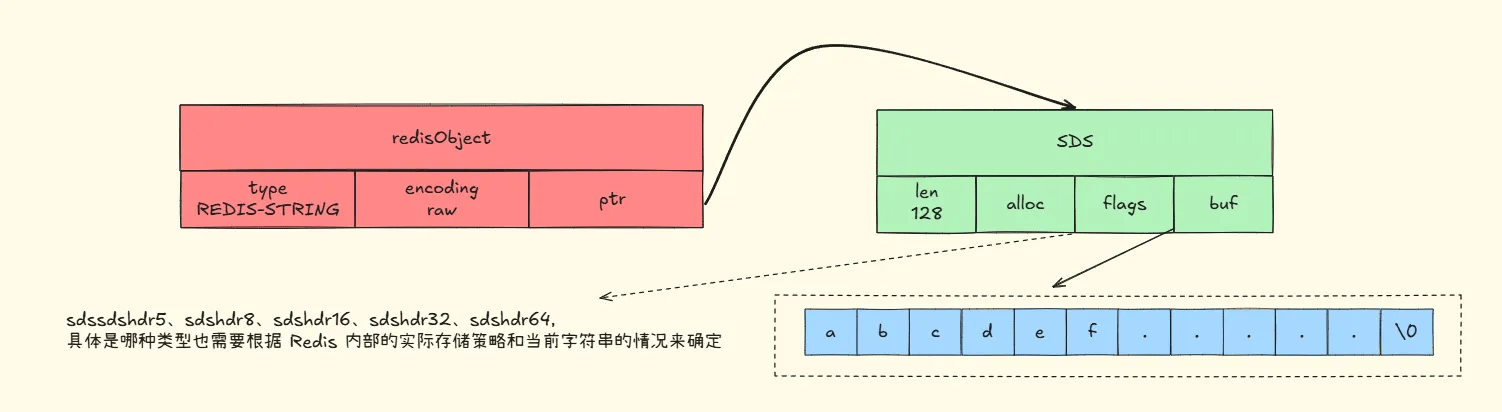
# raw编码
struct redisObject {
unsigned type:4; // 数据类型
unsigned encoding:4; // 编码类型,这里是 raw
void *ptr; // 指向 sdshdr 结构
};
struct sdshdr {
uint32_t len; // 当前字符串长度
uint32_t alloc; // 已分配的内存大小
unsigned char flags; // 编码类型
char buf[]; // 实际字符串数据
};若字符串对象保存的字符串长度大于 32 字节(redis 2.+版本),会用简单动态字符串(SDS)保存,且将对象编码设为 raw。
-
embstr 编码和 raw 编码的边界在不同 Redis 版本中存在差异:
- redis 2.+ 版本为 32 字节。
- redis 3.0 - 4.0 版本为 39 字节。
- redis 5.0 版本为 44 字节。
-
embstr 和 raw 编码都使用 SDS 保存值,区别在于:
- embstr 通过一次内存分配函数,分配一块连续内存空间保存 redisObject 和 SDS。
- raw 通过调用两次内存分配函数,分别分配两块空间保存 redisObject 和 SDS。
-
embstr 编码的好处:
- 将创建字符串对象所需的内存分配次数从两次降为一次。
- 释放对象时只需调用一次内存释放函数。
- 所有数据保存在连续内存,利于利用 CPU 缓存提升性能。
-
embstr 编码的缺点:
- 字符串长度增加需重新分配内存时,整个 redisObject 和 SDS 都要重新分配空间。
- 实际上是只读的,Redis 未编写相应修改程序,执行修改命令(如 append)时,会先将编码从 embstr 转换为 raw,再执行修改。
# 总结
| 编码类型 | 适用场景 | 特点 |
|---|---|---|
| int | 存储可解析为整数的字符串 | 内存消耗最小,适合数字值 |
| embstr | 存储较短字符串 | 元数据和内容存于同一块内存,适合读多写少场景 |
| raw | 存储较长字符串 | 元数据和内容分开存储,适合频繁操作的大字符串 |