✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
文章详细介绍了单例模式和策略模式的定义、实现方式及应用场景。单例模式确保类的唯一实例,介绍了饿汉式、懒汉式、双重检查锁、静态内部类、枚举等多种线程安全实现方式,并讨论了反射入侵与序列化安全问题及其解决方案。文章结合JDK和MyBatis源码,分析了单例模式的实际应用及存在的局限性。策略模式则通过定义策略接口和具体策略类,实现算法的独立封装与动态切换,避免大量条件判断,提升代码的可维护性和扩展性。文中通过计算器和报文解析示例,结合工厂模式展示了策略模式的设计与使用,并列举了其在支付、促销、日志、压缩、认证等多种实际场景中的应用,强调了策略模式在系统灵活性和解耦方面的重要价值。
2025-01-15🌱上海: ☀️ 🌡️+6°C 🌬️↓18km/h
# 单例模式有哪几种实现?如何保证线程安全?
# 什么是单例模式?
单例设计模式(Singleton Design Pattern)理解起来非常简单。一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
单例模式属于创建型模式,这类模式主要关注对象的创建过程。
# 为什么要使用单例?
# 1.1. 表示全局唯一
对于系统中应该且只能保存一份的数据,可设计为单例类,比如:
- 配置类:系统仅有一个配置文件,加载到内存后映射成唯一的【配置实例】,可选择使用单例模式。
- 全局计数器:用于数据统计、生成全局递增 ID 等功能,必须唯一,否则可能导致统计无效、ID 重复等问题 。代码如下
public class GlobalCounter {
private AtomicLong atomicLong = new AtomicLong(0);
private static final GlobalCounter instance = new GlobalCounter();
// 私有化无参构造器
private GlobalCounter() {}
public static GlobalCounter getInstance() {
return instance;
}
public long getId() {
return atomicLong.incrementAndGet();
}
}
// 查看当前的统计数量
long courrentNumber = GlobalCounter.getInstance().getId();以上代码也可以实现全局ID生成器的代码。
# 1.2. 处理资源访问冲突
假如我们自己设计一个日志输出的功能,就可以使用单例避免资源访问冲突。
简单例子如下:
public class Logger {
private String basePath = "D://info.log";
private FileWriter writer;
public Logger() {
File file = new File(basePath);
try {
writer = new FileWriter(file, true); //true表示追加写入
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public void log(String message) {
try {
writer.write(message);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public void setBasePath(String basePath) {
this.basePath = basePath;
}
}@RestController("user")
public class UserController {
public Result login(){
// 登录成功
Logger logger = new Logger();
logger.log("tom logged in successfully.");
// ...
return new Result();
}
}但是以上代码会出现什么问题呢?
每次登录都会创建一个logger实例,多个实例在多个线程中同时操作同一个文件,就有可能产生相互覆盖的问题。因为tomcat处理每一个请求都会使用一个新的线程(暂不考虑多路复用)。这时候日志文件就成了一个共享资源,但凡是多线程访问共享资源,都需要考虑并发修改产生的问题。很多人肯定第一时间想到的解决方案就是加锁,但是加锁应该怎么加?
public synchronized void log(String message) {
try {
writer.write(message);
} catch (IOException e) {
throw new RuntimeException(e);
}
}以上代码是加锁到方法上,这样可以避免多线程并发修改的问题么?
事实上这样加锁毫无卵用,方法级别的锁可以保证new出来的同一个实例多线程下可以同步执行log方法,但是创建了多个实例,并且writer方法本身就是加了锁的,所以这样做并没有意义。
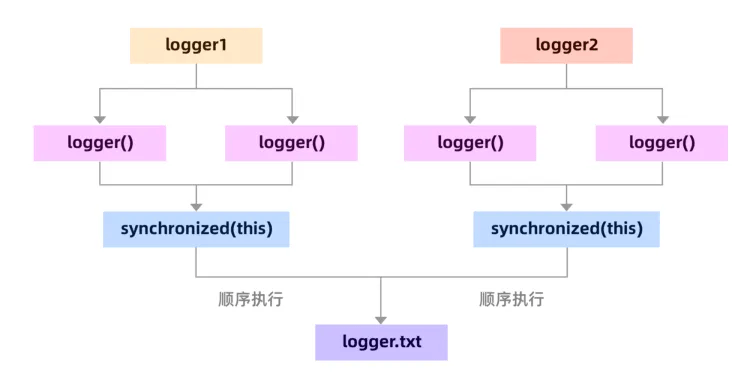
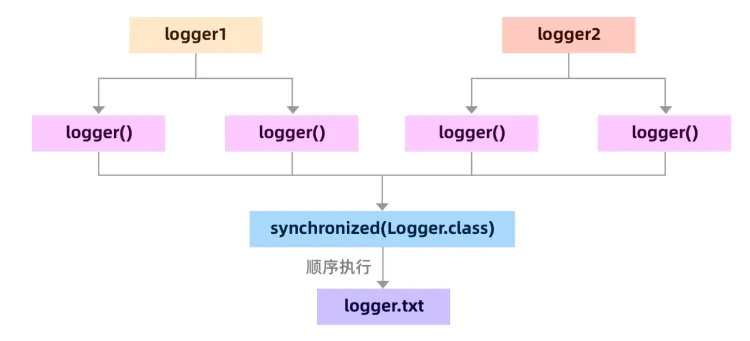
但是并不是说加锁没用,加锁是一定能解决共享资源冲突问题的,只是应该加在哪里,怎样使用。我们只需要放大锁的范围从this到class,也是可以解决这个问题的
public void log(String message) {
synchronized (Logger.class) {
try {
writer.write(message);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
从以上的内容我们也发现了:
- 如果使用单个实例输出日志,锁【this】即可。
- 如果要保证JVM级别防止日志文件访问冲突,锁【class】即可。
- 如果要保证集群服务级别的防止日志文件访问冲突,加分布式锁即可。
如果我们是一个简单工程,对日志输入要求不高。单例模式的解决思路就十分合适,既然同一个Logger无法并行输出到一个文件中,那么针对这个日志文件创建多个Logger实例也就失去了意义,如果工程要求我们所有的日志输出到同一个日志文件中,这样其实并不需要创建大量的Logger实例,这样的好处有:
- 一方面节省内存空间。
- 另一方面节省系统文件句柄(对于操作系统来说,文件句柄也是一种资源,不能随便浪费)。
按照这个设计思路,我们实现了 Logger 单例类。具体代码如下所示:
public class Logger {
private String basePath = "D://log/";
private static Logger instance = new Logger();
private FileWriter writer;
private Logger() {
File file = new File(basePath);
try {
writer = new FileWriter(file, true); //true表示追加写入
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static Logger getInstance(){
return instance;
}
public void log(String message) {
try {
writer.write(message);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public void setBasePath(String basePath) {
this.basePath = basePath;
}
}除此之外,并发队列(比如 Java 中的 BlockingQueue)也可以解决这个问题:多个线程同时往并发队列里写日志,一个单独的线程负责将并发队列中的数据写入到日志文件。这种方式实现起来也稍微有点复杂。当然,我们还可将其延伸至消息队列处理分布式系统的日志。
# 如何实现一个单例?
常见的单例模式,有以下五种写法,但是编写代码的时候需要注意以下几点:
1、构造器需要私有化
2、暴露一个公共的获取单例对象的接口
3、是否支持懒加载(延迟加载)
4、是否线程安全
# 1.1. 饿汉式
饿汉式的实现方式比较简单。在类加载的时候,instance 静态实例就已经创建并初始化好了,所以,instance 实例的创建过程是线程安全的。从名字中我们也可以看出这一点。具体的代码实现如下所示:
public class EagerSingleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}我个人认为饿汉式的单例工作中值得提倡,可能觉得饿汉式不支持懒加载,浪费资源,也会增加初始化的开销,但是其实并不会占用太多资源,并且如果一个实例初始化的过程比较复杂更应该放在启动时处理,避免运行时卡顿或者发生问题。满足了fail-fast的设计原则。
# 1.2. 懒汉式
懒汉式相对于饿汉式的优势是支持延迟加载,具体的代码实现如下所示:
public class LazySingleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}以上的写法本质上是有问题,当面对大量并发请求时,其实是无法保证其单例的特点的,很有可能会有超过一个线程同时执行了new Singleton();怎么解决呢?当然就是加锁呗
public class Singleton {
private static Singleton instance;
private Singleton (){}
public synchronized static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}以上的写法确实可以保证jvm中有且仅有一个单例实例存在,但是方法上加锁会极大的降低获取单例对象的并发度。同一时间只有一个线程可以获取单例对象,为了解决以上的方案则有了第三种写法。
# 1.3. 双重检查锁
饿汉式不支持延迟加载,懒汉式有性能问题,不支持高并发。那我们再来看一种既支持延迟加载、又支持高并发的单例实现方式,也就是双重检测实现方式:
在这种实现方式中,只要 instance 被创建之后,即便再调用 getInstance() 函数也不会再进入到加锁逻辑中了。所以,这种实现方式解决了懒汉式并发度低的问题。具体的代码实现如下所示:
public class DclSingleton {
// volatile如果不加可能会出现半初始化的对象
// 现在用的高版本的 Java 已经在 JDK 内部实现中解决了这个问题(解决的方法很简单,只要把对象 new 操作和初始化操作设计为原子操作,就自然能禁止重排序),为了兼容性我们加上
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}# 1.4. 静态内部类
我们再来看一种比双重检测更加简单的实现方法,那就是利用 Java 的静态内部类。它有点类似饿汉式,但又能做到了延迟加载。具体是怎么做到的呢?我们先来看它的代码实现。
public class InnerSingleton {
/** 私有化构造器 */
private Singleton() {
}
/** 对外提供公共的访问方法 */
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
/** 写一个静态内部类,里面实例化外部类 */
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
}SingletonHolder 是一个静态内部类,当外部类 Singleton被加载的时候,并不会创建 SingletonHolder 实例对象。只有当调用 getInstance() 方法时,SingletonHolder 才会被加载,这个时候才会创建 instance。insance 的唯一性、创建过程的线程安全性,都由 JVM 来保证。所以,这种实现方法既保证了线程安全,又能做到延迟加载。
# 1.5. 枚举
最后,我们介绍一种最简单的实现方式,基于枚举类型的单例实现。这种实现方式通过 Java 枚举类型本身的特性,保证了实例创建的线程安全性和实例的唯一性。具体的代码如下所示:
这是一个最简单的实现,因为枚举类中,每一个枚举项本身就是一个单例的:
public enum EnumSingleton {
INSTANCE;
}更通用的写法
public class EnumSingleton {
// 私有构造函数,防止外部实例化
private EnumSingleton() {
}
// 定义一个枚举类型
public static enum SingletonEnum {
INSTANCE;
private EnumSingleton singleton;
// 枚举常量的构造函数
private SingletonEnum() {
singleton = new EnumSingleton();
}
public EnumSingleton getInstance() {
return singleton;
}
}
// 提供一个公共的静态方法来获取单例实例
public static EnumSingleton getInstance() {
return SingletonEnum.INSTANCE.getInstance();
}
}事实上我们还可以将单例项作为枚举的成员变量,累加器可以这样编写:
public enum GlobalCounter {
INSTANCE;
private AtomicLong atomicLong = new AtomicLong(0);
public long getNumber() {
return atomicLong.incrementAndGet();
}
}这种写法是Head-first中推荐的写法,除了可以和其他的方式一样实现单例,还能有效的防止反射入
# 1.6. 反射入侵
事实上,我们想要阻止其他人构造实例仅仅私有化构造器还是不够的,因为我们还可以使用反射获取私有构造器进行构造,当然使用枚举的方式是可以解决这个问题的,对于其他的书写方案,我们通过下边的方式解决:
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){
if(singleton != null)
throw new RuntimeException("实例:【"
+ this.getClass().getName() + "】已经存在,该实例只允许实例化一次");
}
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}此时方法如下
@Test
public void testReflect() throws NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
Class<DclSingleton> clazz = DclSingleton.class;
Constructor<DclSingleton> constructor = clazz.getDeclaredConstructor();
constructor.setAccessible(true);
boolean flag = DclSingleton.getInstance() == constructor.newInstance();
log.info("flag -> {}",flag);
}
# 1.7. 序列化与反序列化安全
事实上,到目前为止,此时单例依然是有漏洞的,看如下代码:
@Test
public void testSerialize() throws IllegalAccessException, NoSuchMethodException, IOException, ClassNotFoundException {
// 获取单例并序列化
Singleton singleton = Singleton.getInstance();
FileOutputStream fout = new FileOutputStream("D://singleton.txt");
ObjectOutputStream out = new ObjectOutputStream(fout);
out.writeObject(singleton);
// 将实例反序列化出来
FileInputStream fin = new FileInputStream("D://singleton.txt");
ObjectInputStream in = new ObjectInputStream(fin);
Object o = in.readObject();
log.info("他们是同一个实例吗?{}",o == singleton);
}结果如下

readResolve()方法可以用于替换从流中读取的对象,在进行反序列化时,会尝试执行readResolve方法,并将返回值作为反序列化的结果,而不会克隆一个新的实例,保证jvm中仅仅有一个实例存在:
public class Singleton implements Serializable {
// 省略其他的内容
public static Singleton getInstance() {
}
// 需要加这么一个方法
public Object readResolve(){
return singleton;
}
}
# 单例模式的源码应用
在JDK或者其他的通用框架中很少能看到标准的单例设计模式,这也就意味着他确实很经典,但严格的单例设计确实有它的问题和局限性,我们先看看在源码中的一些案例。
# 1.1. jdk中的单例
jdk中有一个类的实现是一个标准单例模式->Runtime类,该类封装了运行时的环境。每个 Java 应用程序都有一个 Runtime 类实例,使应用程序能够与其运行的环境相连接。 一般不能实例化一个Runtime对象,应用程序也不能创建自己的 Runtime 类实例,但可以通过 getRuntime 方法获取当前Runtime运行时对象的引用。
public class Runtime {
// 典型的饿汉式
private static final Runtime currentRuntime = new Runtime();
private static Version version;
public static Runtime getRuntime() {
return currentRuntime;
}
/** Don't let anyone else instantiate this class */
private Runtime() {}
public void exit(int status) {
@SuppressWarnings("removal")
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkExit(status);
}
Shutdown.exit(status);
}
public Process exec(String command) throws IOException {
return exec(command, null, null);
}
public native long freeMemory();
public native long maxMemory();
public native void gc();
}# 1.2. Mybatis中的单例
Mybaits中的org.apache.ibatis.io.VFS使用到了单例模式。VFS就是Virtual File System的意思,mybatis通过VFS来查找指定路径下的资源。查看VFS以及它的实现类,不难发现,VFS的角色就是对更“底层”的查找指定资源的方法的封装,将复杂的“底层”操作封装到易于使用的高层模块中,方便使用者使用
public class public abstract class VFS {
// 使用了内部类
private static class VFSHolder {
static final VFS INSTANCE = createVFS();
@SuppressWarnings("unchecked")
static VFS createVFS() {
// ...省略创建过程
return vfs;
}
}
public static VFS getInstance() {
return VFSHolder.INSTANCE;
}
}# 单例存在的问题
尽管单例是一个很经典的设计模式,但在实际的开发中,我们也很少按照严格的定义去使用它,以上的知识大多是为了理解和面试而使用和学习,有些人甚至认为单例是一种反模式(anti-pattern),压根就不推荐使用。
大部分情况下,我们在项目中使用单例,都是用它来表示一些全局唯一类,比如配置信息类、连接池类、ID 生成器类。单例模式书写简洁、使用方便,在代码中,我们不需要创建对象。但是,这种使用方法有点类似硬编码(hard code),会带来诸多问题,所以我们一般会使用spring的单例容器作为替代方案。
# 1.1. 无法支持面向对象编程
OOP 的三大特性是封装、继承、多态。单例将构造私有化,直接导致的结果就是,他无法成为其他类的父类,这就相当于直接放弃了继承和多态的特性,也就相当于损失了可以应对未来需求变化的扩展性,以后一旦有扩展需求,比如写一个类似的具有绝大部分相同功能的单例,就得新建一个十分相似的单例。

# 1.2. 很难做横向扩展
单例类只能有一个对象实例。如果未来某一天,一个实例已经无法满足我们的需求,我们需要创建一个,或者更多个实例时,就必须对源代码进行修改,无法友好扩展。
# 不同作用范围下的单例
首先再复习下单例的定义:“一个类只允许创建唯一一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。”
定义中提到,“一个类只允许创建唯一一个对象”。那对象的唯一性的作用范围是什么呢?在标准的单例设计模式中,其单例是进程唯一的,也就意味着一个项目启动,在其整个运行环境中只能有一个实例。
事实上,在实际的工作当中,我们能够看到极多【只有一个实例的情况】,但是大多并不是标准的单例设计模式,如:
- 1、使用ThreadLocal实现的线程级别的单一实例。
- 2、使用spring实现的容器级别的单一是实例。
- 3、使用分布式锁实现的集群状态的唯一实例。
以上的情况都不是标准的单例设计模式,但我们可以将其看做单例设计模式的扩展,我们以前两种情况为例进行介绍。
# 1.1. 线程级别的单例
上面说的单例类对象是进程唯一的,一个进程只能有一个单例对象。那如何实现一个线程唯一的单例呢?
如果在不允许使用ThreadLocal的时候我们可能想到如下的解决方案,定义一个全局的线程安全的ConcurrentHashMap,以线程id为key,以实例为value,每个线程的存取都从共享的map中进行操作,代码如下:
public class Connection {
private static final ConcurrentHashMap<Long, Connection> instances
= new ConcurrentHashMap<>();
private Connection() {}
public static Connection getInstance() {
Long currentThreadId = Thread.currentThread().getId();
instances.putIfAbsent(currentThreadId, new Connection());
return instances.get(currentThreadId);
}
}其实ThreadLocal的原理也大致如此
- 在spring使用ThreadLocal对当前线程和一个连接资源进行绑定,实现事务管理:
public abstract class TransactionSynchronizationManager {
// 本地线程中保存了当前的连接资源,key(datasource)--> value(connection)
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
// 保存了当前线程的事务同步器
private static final ThreadLocal<Set<TransactionSynchronization>> synchronizations = new NamedThreadLocal<>("Transaction synchronizations");
// 保存了当前线程的事务名称
private static final ThreadLocal<String> currentTransactionName =
new NamedThreadLocal<>("Current transaction name");
// 保存了当前线程的事务是否只读
private static final ThreadLocal<Boolean> currentTransactionReadOnly =
new NamedThreadLocal<>("Current transaction read-only status");
// 保存了当前线程的事务隔离级别
private static final ThreadLocal<Integer> currentTransactionIsolationLevel =
new NamedThreadLocal<>("Current transaction isolation level");
// 保存了当前线程的事务的活跃状态
private static final ThreadLocal<Boolean> actualTransactionActive =
new NamedThreadLocal<>("Actual transaction active");
}- 在spring中使用RequestContextHolder,可以再一个线程中轻松的获取request、response和session。如果将来我们在静态方法,切面中想获取一个request对象就可以使用这个类。
public abstract class RequestContextHolder {
private static final ThreadLocal<RequestAttributes> requestAttributesHolder = new NamedThreadLocal("Request attributes");
private static final ThreadLocal<RequestAttributes> inheritableRequestAttributesHolder = new NamedInheritableThreadLocal("Request context");
@Nullable
public static RequestAttributes getRequestAttributes() {
RequestAttributes attributes = (RequestAttributes)requestAttributesHolder.get();
if (attributes == null) {
attributes = (RequestAttributes)inheritableRequestAttributesHolder.get();
}
return attributes;
}
}- 在pageHelper使用ThreadLocal保存分页对象:
public abstract class PageMethod {
protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();
protected static boolean DEFAULT_COUNT = true;
}# 1.2. 容器范围的单例
有的时候我们将单例的作用范围由进程切换到一个容器,可能会更加方便我们进行单例对象的管理。这也是spring的核心思想。spring通过提供一个单例容器,来确保一个实例在容器级别单例,并且可以在容器启动时完成初始化,他的优势如下:
- 所有的bean以单例形式存在于容器中,避免大量的对象被创建,造成jvm内存抖动严重,频繁gc。
- 程序启动时,初始化单例bean,满足fast-fail,将所有构建过程的异常暴露在启动时,而非运行时,更加安全。
- 缓存了所有单例bean,启动的过程相当于预热的过程,运行时不必进行对象创建,效率更高。
- 容器管理bean的生命周期,结合依赖注入使得解耦更加彻底、扩展性无敌。
# 什么是策略模式?一般用在什么场景?
# 原理及实现
策略模式是一种行为型设计模式,它定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,让算法独立于使用它的客户端(调用方)而变化。
很多情况下,我们代码里有大量的 if else、switch 等,可以通过使用策略模式,避免大量条件语句的使用,实现算法的分离和独立变化。
它的主要目的是为了解耦多个策略,并方便调用方在针对不同场景灵活切换不同的策略。
策略模式主要包含以下角色:
- 策略接口(Strategy):定义所有支持的算法的公共接口。客户端使用这个接口与具体策略进行交互。
- 具体策略(Concrete Strategy):实现策略接口的具体策略类。这些类封装了实际的算法逻辑。
- 上下文(Context):持有一个策略对象,用于与客户端进行交互。上下文可以定义一些接口,让客户端不直接与策略接口交互,从而实现策略的封装。
实现一个简单的计算器来说明策略模式,计算器支持加法、减法和乘法运算。我们可以使用策略模式将各种运算独立为不同的策略,并让客户端根据需要选择和使用不同的策略。
首先,我们定义一个策略接口Operation:
public interface Operation {
double execute(double num1, double num2);
}接下来创建具体策略类实现加法、减法和乘法运算:
public class Addition implements Operation {
@Override
public double execute(double num1, double num2) {
return num1 + num2;
}
}
public class Subtraction implements Operation {
@Override
public double execute(double num1, double num2) {
return num1 - num2;
}
}
public class Multiplication implements Operation {
@Override
public double execute(double num1, double num2) {
return num1 * num2;
}
}然后创建一个上下文类Calculator,让客户端可以使用这个类来执行不同的运算:
public class Calculator {
private Operation operation;
public void setOperation(Operation operation) {
this.operation = operation;
}
public double executeOperation(double num1, double num2) {
return operation.execute(num1, num2);
}
}然后执行不同的运算
public class Client {
public static void main(String[] args) {
Calculator calculator = new Calculator();
calculator.setOperation(new Addition());
System.out.println("10 + 5 = " + calculator.executeOperation(10, 5));
calculator.setOperation(new Subtraction());
System.out.println("10 - 5 = " + calculator.executeOperation(10, 5));
calculator.setOperation(new Multiplication());
System.out.println("10 * 5 = " + calculator.executeOperation(10,5));
}
}我们使用策略模式将加法、减法和乘法运算独立为不同的策略。客户端可以根据需要选择和使用不同的策略。Calculator上下文类持有一个Operation策略对象,并通过setOperation方法允许客户端设置所需的策略。这种方式使得算法的选择和执行更加灵活,易于扩展和维护。
但是策略模式同样也有优缺点。优点方面,可提高代码可维护性与可扩展性,新增算法只需实现新策略类,无需修改客户端代码,符合开闭原则;还能避免多重条件判断,让代码更清晰易懂。缺点是客户端需了解所有策略以作选择,且该模式会增加类的数量,使代码复杂性上升 。
在实际开发中,我们可以根据业务需求和系统架构灵活地运用策略模式。例如,在电商系统中,我们可以使用策略模式处理不同的促销策略;在游戏系统中,我们可以使用策略模式处理不同的角色行为等。
# 定义
策略类的定义比较简单,包含一个策略接口和一组实现这个接口的策略类。因为所有的策略类都实现相同的接口,所以,客户端代码基于接口而非实现编程,可以灵活地替换不同的策略。示例代码如下所示:
public interface Strategy {
void algorithmInterface();
}
public class ConcreteStrategyA implements Strategy {
@Override
public void algorithmInterface() {
//具体的算法...
}
}
public class ConcreteStrategyB implements Strategy {
@Override
public void algorithmInterface() {
//具体的算法...
}
}# 创建
因为策略模式会包含一组策略,在使用它们的时候,一般会通过类型(type)来判断创建哪个策略来使用。为了封装创建逻辑,我们需要对客户端代码屏蔽创建细节。
事实上我们可以做一定的优化,可以把根据 type 创建策略的逻辑抽离出来,放到工厂类中。示例代码如下所示:
public class StrategyFactory {
private static final Map<String, Strategy> strategies = new HashMap<>();
static {
strategies.put("A", new ConcreteStrategyA());
strategies.put("B", new ConcreteStrategyB());
}
public static Strategy getStrategy(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
return strategies.get(type);
}
}一般来讲,如果策略类是无状态的,不包含成员变量,只是纯粹的算法实现,这样的策略对象是可以被共享使用的,不需要在每次调用 getStrategy() 的时候,都创建一个新的策略对象。针对这种情况,我们可以使用上面这种工厂类的实现方式,事先创建好每个策略对象,缓存到工厂类中,用的时候直接返回。
相反,如果策略类是有状态的,根据业务场景的需要,我们希望每次从工厂方法中,获得的都是新创建的策略对象,而不是缓存好可共享的策略对象,那我们就需要按照如下方式来实现策略工厂类。
public class StrategyFactory {
public static Strategy getStrategy(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
if (type.equals("A")) {
//一些其它初始化逻辑...
return new ConcreteStrategyA();
} else if (type.equals("B")) {
//一些其它初始化逻辑...
return new ConcreteStrategyB();
}
return null;
}
}# 使用
刚刚讲了策略的定义和创建,现在,我们再来看一下,策略的使用。
我们知道,策略模式包含一组可选策略,客户端代码一般如何确定使用哪个策略呢?最常见的是运行时动态确定使用哪种策略,这也是策略模式最典型的应用场景。
这里的“运行时动态”指的是,我们事先并不知道会使用哪个策略,而是在程序运行期间,根据配置、用户输入、计算结果等这些不确定因素,动态决定使用哪种策略。接下来,我们通过一个例子来解释一下。
// 策略接口:EvictionStrategy
// 策略类:LruEvictionStrategy、FifoEvictionStrategy、LfuEvictionStrategy...
// 策略工厂:EvictionStrategyFactory
public class UserCache {
private Map<String, User> cacheData = new HashMap<>();
private EvictionStrategy eviction;
public UserCache(EvictionStrategy eviction) {
this.eviction = eviction;
}
//...
}
// 运行时动态确定,根据配置文件的配置决定使用哪种策略
public class Application {
public static void main(String[] args) throws Exception {
EvictionStrategy evictionStrategy = null;
Properties props = new Properties();
props.load(new FileInputStream("./config.properties"));
String type = props.getProperty("eviction_type");
evictionStrategy = EvictionStrategyFactory.getEvictionStrategy(type);
UserCache userCache = new UserCache(evictionStrategy);
//...
}
}
// 非运行时动态确定,在代码中指定使用哪种策略
public class Application {
public static void main(String[] args) {
//...
EvictionStrategy evictionStrategy = new LruEvictionStrategy();
UserCache userCache = new UserCache(evictionStrategy);
//...
}
}从上面的代码中,我们也可以看出,“非运行时动态确定”,也就是第二个 Application 中的使用方式,并不能发挥策略模式的优势。在这种应用场景下,策略模式实际上退化成了“面向对象的多态特性”或“基于接口而非实现编程原则”。
# 实践应用
一般策略模式主要用来优化屎山代码,也就是所谓的大量的判断分支if-else。那么具体该怎么优化呢?这里我们模拟一个例子,使用工厂模式和策略模式进行优化代码。
# 基础优化
假设我们现在有这么一个大量if分支的报文解析系统代码
public class MessageParser {
public void parseMessage(Message message) {
String messageType = message.getType();
if ("XML".equalsIgnoreCase(messageType)) {
// 解析 XML 报文
System.out.println("解析 XML 报文: " + message.getContent());
} else if ("JSON".equalsIgnoreCase(messageType)) {
// 解析 JSON 报文
System.out.println("解析 JSON 报文: " + message.getContent());
} else if ("CSV".equalsIgnoreCase(messageType)) {
// 解析 CSV 报文
System.out.println("解析 CSV 报文: " + message.getContent());
} else {
throw new IllegalArgumentException("未知的报文类型: " + messageType);
}
}
}使用策略模式进行一步步优化
先定义一个策略接口MessageParserStrategy:
public interface MessageParserStrategy {
// 解析报文内容的方法,输入一个 Message 对象,无返回值
void parse(Message message);
}然后,实现具体实现类
// XML 报文解析策略
public class XmlMessageParserStrategy implements MessageParserStrategy {
@Override
public void parse(Message message) {
System.out.println("解析 XML 报文: " + message.getContent());
}
}
// JSON 报文解析策略
public class JsonMessageParserStrategy implements MessageParserStrategy {
@Override
public void parse(Message message) {
System.out.println("解析 JSON 报文: " + message.getContent());
}
}
// CSV 报文解析策略
public class CsvMessageParserStrategy implements MessageParserStrategy {
@Override
public void parse(Message message) {
System.out.println("解析 CSV 报文: " + message.getContent());
}
}接下来创建一个上下文类MessageParserContext
public class MessageParserContext {
private MessageParserStrategy strategy;
// 设置报文解析策略
public void setStrategy(MessageParserStrategy strategy) {
this.strategy = strategy;
}
// 根据策略解析报文
public void parseMessage(Message message) {
strategy.parse(message);
}
}最近使用策略模式进行报文解析
public class Main {
public static void main(String[] args) {
MessageParserContext parserContext = new MessageParserContext();
// 使用 XML 报文解析策略
parserContext.setStrategy(new XmlMessageParserStrategy());
parserContext.parseMessage(new Message("XML", "<xml>这是一个 XML 报文</xml>"));
// 使用 JSON 报文解析策略
parserContext.setStrategy(new JsonMessageParserStrategy());
parserContext.parseMessage(new Message("JSON", "{\"message\": \"这是一个 JSON 报文\"}"));
// 使用 CSV 报文解析策略
parserContext.setStrategy(new CsvMessageParserStrategy());
parserContext.parseMessage(new Message("CSV", "这是一个,CSV,报文"));
}
}# 结合工厂模式
我们可以将策略模式与工厂模式结合,以便根据不同的消息类型自动匹配不同的解析策略。下面是如何实现这个优化的:
首先,我们创建一个MessageParserStrategyFactory类,用于根据报文类型创建相应的解析策略:
public class MessageParserStrategyFactory {
private static final Map<String, MessageParserStrategy> strategies = new HashMap<>();
static {
strategies.put("XML", new XmlMessageParserStrategy());
strategies.put("JSON", new JsonMessageParserStrategy());
strategies.put("CSV", new CsvMessageParserStrategy());
}
public static MessageParserStrategy getStrategy(String messageType) {
MessageParserStrategy strategy = strategies.get(messageType.toUpperCase());
if (strategy == null) {
throw new IllegalArgumentException("未知的报文类型: " + messageType);
}
return strategy;
}
}接下来修改MessageParserContext类,使其根据报文类型自动选择解析策略:
public class MessageParserContext {
public void parseMessage(Message message) {
MessageParserStrategy strategy = MessageParserStrategyFactory.getStrategy(message.getType());
strategy.parse(message);
}
}现在,我们的代码可以根据不同的消息类型自动匹配不同的解析策略,而无需手动设置策略。以下是使用此优化的示例:
public class Main {
public static void main(String[] args) {
MessageParserContext parserContext = new MessageParserContext();
// 自动使用 XML 报文解析策略
parserContext.parseMessage(new Message("XML", "<xml>这是一个 XML 报文</xml>"));
// 自动使用 JSON 报文解析策略
parserContext.parseMessage(new Message("JSON", "{\"message\": \"这是一个 JSON 报文\"}"));
// 自动使用 CSV 报文解析策略
parserContext.parseMessage(new Message("CSV", "这是一个,CSV,报文"));
}
}还可以继续优化,就是不用修改策略工厂类中的静态代码段来添加新的策略解析模式,怎么实现呢?
我们可以通过反射来避免对策略工厂类的修改。
具体是这么做的:我们通过一个配置文件或者自定义的 annotation 来标注都有哪些策略类;策略工厂类读取配置文件或者搜索被 annotation 标注的策略类,然后通过反射了动态地加载这些策略类、创建策略对象;当我们新添加一个策略的时候,只需要将这个新添加的策略类添加到配置文件或者用 annotation 标注即可。
# 源码使用
# ssm框架
- Spring中的Resource接口:在Spring框架中,
org.springframework.core.io.Resource接口用于抽象不同类型的资源,例如文件系统资源、类路径资源、URL资源等。Resource接口就像策略模式中的策略接口,而不同类型的资源类(如ClassPathResource、FileSystemResource等)就像具体策略。客户端可以根据需要选择和使用不同的资源类。 - Spring中的AOP代理:在Spring AOP中,代理类的创建使用了策略模式。
org.springframework.aop.framework.ProxyFactory中的AopProxy接口定义了创建代理对象的策略接口,而JdkDynamicAopProxy和CglibAopProxy这两个类分别为基于JDK动态代理和CGLIB动态代理的具体策略。客户端可以根据需要选择使用哪种代理方式。 - MyBatis中的Executor接口:在MyBatis中,
Executor接口定义了执行SQL语句的策略接口。MyBatis提供了不同的Executor实现,例如SimpleExecutor、ReuseExecutor和BatchExecutor等,它们分别表示不同的执行策略。客户端可以通过配置选择使用哪种执行策略。 - Spring MVC中的HandlerMapping接口:在Spring MVC框架中,
HandlerMapping接口定义了映射请求到处理器的策略接口。Spring MVC提供了多种HandlerMapping实现,例如BeanNameUrlHandlerMapping、RequestMappingHandlerMapping等,分别表示不同的映射策略。客户端可以通过配置选择使用哪种映射策略。
这些例子展示了策略模式在SSM框架中的应用。策略模式通过将算法和客户端分离,使得系统更加灵活和可扩展。在实际开发中,我们可以参考这些例子,根据业务需求和系统架构灵活地运用策略模式。
这里我们以MyBatis中的Executor接口为例,展示策略模式在MyBatis中的应用。
首先,Executor接口是策略接口,定义了执行SQL语句的公共方法。以下是简化后的Executor接口:
public interface Executor {
<E> List<E> query(MappedStatement ms, Object parameter) throws SQLException;
int update(MappedStatement ms, Object parameter) throws SQLException;
// ... 其他方法
}接下来,我们来看MyBatis提供的不同Executor实现:
(1)SimpleExecutor:简单执行器,每次执行SQL都会创建一个新的预处理语句(PreparedStatement)。
public class SimpleExecutor extends BaseExecutor {
@Override
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
// ... 省略具体实现
}
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter) throws SQLException {
// ... 省略具体实现
}
// ... 其他方法
}(2)ReuseExecutor:重用执行器,会尽量重用预处理语句(PreparedStatement),以减少创建和销毁预处理语句的开销。
public class ReuseExecutor extends BaseExecutor {
@Override
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
// ... 省略具体实现
}
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter) throws SQLException {
// ... 省略具体实现
}
// ... 其他方法
}(3)BatchExecutor:批处理执行器,可以将多个SQL语句一起发送到数据库服务器,减少网络开销。
public class BatchExecutor extends BaseExecutor {
@Override
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
// ... 省略具体实现
}
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter) throws SQLException {
// ... 省略具体实现
}
// ... 其他方法
}客户端可以通过配置选择使用哪种执行策略。在MyBatis配置文件(mybatis-config.xml)中,我们可以设置<setting>标签的defaultExecutorType属性来指定执行器类型:
<settings>
<setting name="defaultExecutorType" value="SIMPLE" />
<!-- 可选值:SIMPLE, REUSE, BATCH -->
</settings>在这个例子中,Executor接口就像策略模式中的策略接口,而SimpleExecutor、ReuseExecutor和BatchExecutor这三个类就像具体策略。客户端可以根据需要选择和使用不同的执行器类型。这种方式使得SQL执行策略的选择和实现更加灵活和可扩展。
# jdk源码
下面我们以java.util.Comparator接口为例,展示策略模式在JDK中的应用。
假设我们有一个Student类,表示学生。我们需要对一个Student对象的列表进行排序。根据不同的需求,我们可能需要按照学生的姓名、年龄或成绩进行排序。这时,我们可以使用策略模式,通过实现Comparator接口,为不同的排序需求提供不同的比较策略。
首先,定义Student类:
public class Student {
private String name;
private int age;
private double score;
// 构造方法、getter和setter方法省略
}然后,实现Comparator接口,定义不同的比较策略:
public class NameComparator implements Comparator<Student> {
@Override
public int compare(Student s1, Student s2) {
return s1.getName().compareTo(s2.getName());
}
}
// 根据学生的年龄进行排序
public class AgeComparator implements Comparator<Student> {
@Override
public int compare(Student s1, Student s2) {
return Integer.compare(s1.getAge(), s2.getAge());
}
}
// 根据学生的成绩进行排序
public class ScoreComparator implements Comparator<Student> {
@Override
public int compare(Student s1, Student s2) {
return Double.compare(s1.getScore(), s2.getScore());
}
}最后,在客户端代码中,根据需要选择和使用不同的比较策略:
public class Client {
public static void main(String[] args) {
// 创建一个Student对象的列表
List<Student> students = new ArrayList<>();
students.add(new Student("Alice", 20, 90.0));
students.add(new Student("Bob", 18, 85.0));
students.add(new Student("Charlie", 22, 88.0));
// 使用姓名比较策略进行排序
Collections.sort(students, new NameComparator());
System.out.println("按姓名排序: " + students);
// 使用年龄比较策略进行排序
Collections.sort(students, new AgeComparator());
System.out.println("按年龄排序: " + students);
// 使用成绩比较策略进行排序
Collections.sort(students, new ScoreComparator());
System.out.println("按成绩排序: " + students);
}
}在这个例子中,我们使用策略模式将不同的排序策略独立为不同的类。客户端可以根据需要选择和使用不同的排序策略,而无需修改代码。这种方式使得排序策略的选择和实现更加灵活和可扩展。在实际开发过程中,可以根据业务需求和系统架构灵活地运用策略模式。
# 使用场景
策略模式在实际工作场景中有很多应用,以下是一些常见的使用场景:
- 支付系统:在电商或其他在线支付场景中,我们可能需要支持多种支付方式(如信用卡、PayPal、微信支付、支付宝等)。我们可以使用策略模式定义一个支付接口,并为每种支付方式提供一个具体的实现。客户端可以根据用户的选择使用不同的支付策略。
- 促销策略:在商城系统中,我们可能需要根据不同的促销活动(如满减、打折、买一送一等)提供不同的折扣策略。我们可以使用策略模式定义一个折扣接口,并为每种促销活动提供一个具体的实现。客户端可以根据不同的促销活动选择合适的折扣策略。
- 日志记录:在实际项目中,我们可能需要将日志记录到不同的存储介质(如控制台、文件、数据库等)。我们可以使用策略模式定义一个日志记录接口,并为每种存储介质提供一个具体的实现。客户端可以根据需要选择和使用不同的日志记录策略。
- 数据压缩:在处理大量数据时,我们可能需要对数据进行压缩,以节省存储空间和网络传输时间。我们可以使用策略模式定义一个数据压缩接口,并为不同的压缩算法(如ZIP、GZIP、LZ77等)提供具体的实现。客户端可以根据需要选择和使用不同的压缩策略。
- 路由选择:在网络通信或分布式系统中,我们可能需要根据不同的情况(如网络状况、负载均衡等)选择不同的路由策略。我们可以使用策略模式定义一个路由选择接口,并为不同的路由选择算法提供具体的实现。客户端可以根据实际情况选择合适的路由策略。
- 机器学习算法:在机器学习领域,我们可能需要根据不同的问题和数据类型选择不同的学习算法(如线性回归、支持向量机、神经网络等)。我们可以使用策略模式定义一个学习算法接口,并为不同的学习算法提供具体的实现。客户端可以根据实际问题选择合适的学习算法。
- 密码加密:在安全领域,我们可能需要对用户密码进行加密,以保护用户数据的安全。我们可以使用策略模式定义一个加密接口,并为不同的加密算法(如MD5、SHA-1、SHA-256等)提供具体的实现。客户端可以根据需要选择和使用不同的加密策略。
- 认证策略:在Web应用中,我们可能需要根据不同的场景选择不同的认证策略(如基于用户名/密码的认证、OAuth认证、单点登录等)。我们可以使用策略模式定义一个认证接口,并为不同的认证方式提供具体的实现。客户端可以根据实际需求选择合适的认证策略。
- 图像处理:在图像处理领域,我们可能需要对图像进行不同的处理操作(如缩放、旋转、滤镜等)。我们可以使用策略模式定义一个图像处理接口,并为不同的处理操作提供具体的实现。客户端可以根据需要选择和使用不同的图像处理策略。
- 任务调度:在分布式计算或并行计算中,我们可能需要根据不同的场景选择不同的任务调度策略(如FIFO、优先级队列、轮询等)。我们可以使用策略模式定义一个任务调度接口,并为不同的调度算法提供具体的实现。客户端可以根据实际情况选择合适的任务调度策略。
- 语言翻译:在开发多语言支持的应用程序时,我们可能需要根据用户的语言选择不同的翻译策略。我们可以使用策略模式定义一个翻译接口,并为不同的语言提供具体的实现。客户端可以根据用户的语言选择合适的翻译策略。
- 数据库访问:在开发支持多种数据库的应用程序时,我们可能需要根据不同的数据库类型选择不同的数据访问策略。我们可以使用策略模式定义一个数据库访问接口,并为不同的数据库(如MySQL、PostgreSQL、Oracle等)提供具体的实现。客户端可以根据实际的数据库类型选择合适的数据访问策略。
- 验证码生成:在开发Web应用程序时,我们可能需要为用户提供不同类型的验证码(如数字验证码、字母验证码、图像验证码等)。我们可以使用策略模式定义一个验证码生成接口,并为不同类型的验证码提供具体的实现。客户端可以根据需要选择和使用不同的验证码生成策略。
- 通信协议:在开发网络通信应用时,我们可能需要支持多种通信协议(如HTTP、FTP、SMTP等)。我们可以使用策略模式定义一个通信协议接口,并为不同的协议提供具体的实现。客户端可以根据需要选择和使用不同的通信协议策略。
- 地图导航:在开发地图导航应用时,我们可能需要根据用户的需求提供不同的路径规划策略(如最短路径、最快路径、避免拥堵等)。我们可以使用策略模式定义一个路径规划接口,并为不同的路径规划需求提供具体的实现。客户端可以根据用户的需求选择合适的路径规划策略。