✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
文章系统梳理了五种主要的I/O模型:阻塞I/O、非阻塞I/O、I/O多路复用、信号驱动I/O和异步I/O,详细解析了各自的工作流程、优缺点及适用场景。阻塞I/O简单但效率低,非阻塞I/O通过轮询或事件驱动避免阻塞,I/O多路复用利用select、poll、epoll实现单线程监控多文件描述符,提升并发处理能力。信号驱动I/O通过内核信号通知减少轮询开销,异步I/O则由内核后台完成数据传输,最大化非阻塞性能。文章还深入比较了select、poll、epoll三者在数据结构、连接数限制、遍历方式及适用场景上的差异,并结合Linux内核机制说明网络I/O阻塞的根因,为理解高效网络编程提供了系统性技术指导。
# I/O模型有哪些?
# 总结分析
| I/O 模型 | 特点 |
|---|---|
| 阻塞 I/O | 调用 I/O 操作时进程阻塞,直到数据准备好或操作完成才继续执行 |
| 非阻塞 I/O | I/O 操作不阻塞进程,数据未准备好立即返回错误或状态,进程可继续执行其他操作 |
| I/O 多路复用 | 使用 select、poll、epoll 等系统调用,可同时等待多个 I/O 操作,有就绪的就进行处理 |
| 信号驱动 I/O | 数据准备好时,内核发信号通知进程进行 I/O 操作,进程接收到信号后再读写数据 |
| 异步 I/O | 发起 I/O 请求后立即返回,内核后台完成 I/O 操作,完成时通知进程,进程无需等待 I/O 完成可执行其他任务 |
# 深入研究五种I/O模型(看完包会)
想要深入的理解各种IO模型,我们首先必须了解产生各种IO的原因,其中的本质问题就是一个消息是如何传递的。(之前题解,用户从输入网址到网站显示期间发生了什么?也有提到过,通过一张图片回顾下)
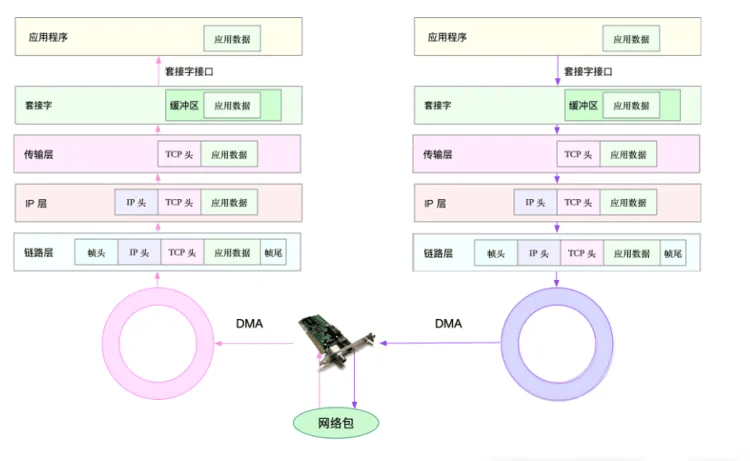
以两个应用程序通讯为例,假设应用程序A向应用程序B发送一条消息,简单来说会经过如下流程(简化):
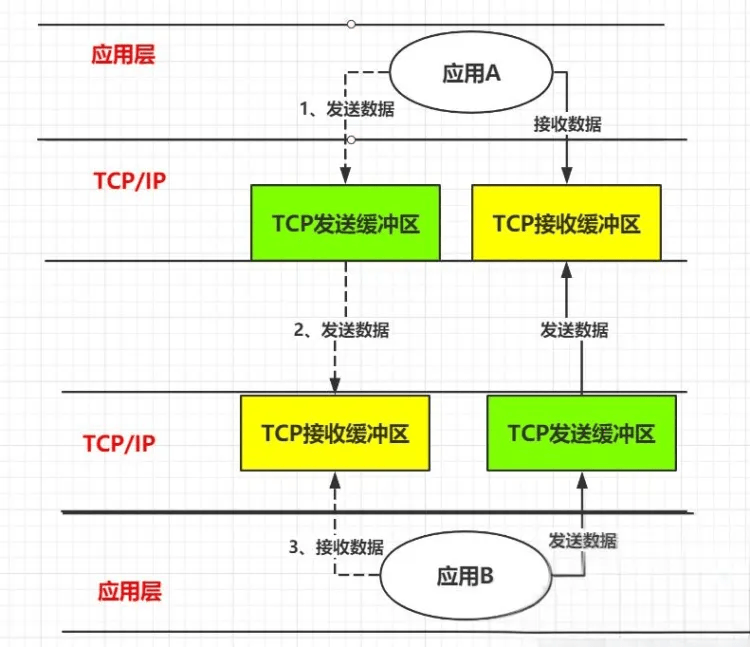
通过上图我们可以了解到基本的消息发送流程,那么我们就继续深入挖掘IO不同的模型是如何实现的
# 阻塞IO
从名字就可以大概看出来,阻塞就是持续等待一个资源。之前我们学习TCP和UDP的时候也了解到应用之间发送消息通常不是一次性把数据发送完成,而是间断性的。也就是说在上图中TCP缓冲区还有接收到属于应用B应该读取的消息时,那么应用B就需要持续等待数据状态,知道内核把数据准备好了交给应用B才结束。
阻塞IO流程
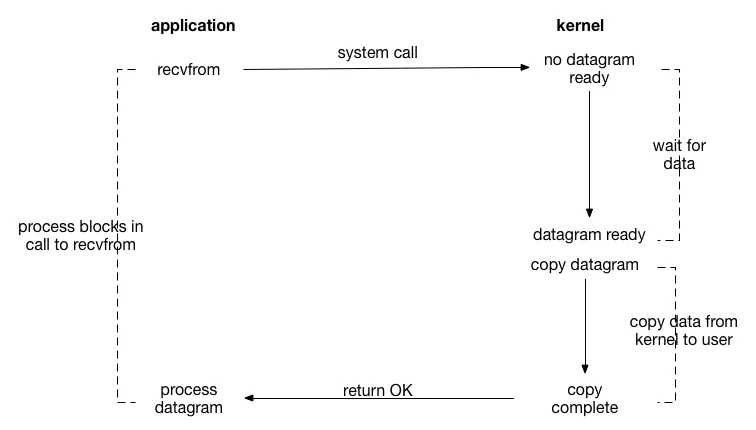
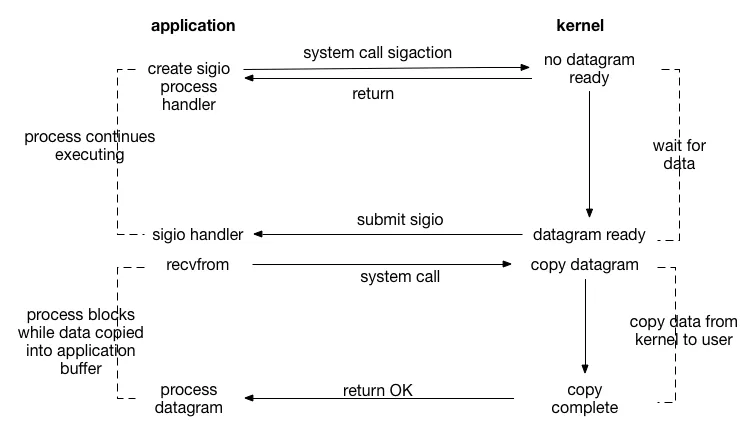
- 应用程序(application)发起
recvfrom系统调用(system call),请求接收数据报(datagram)。 - 此时内核(Kernel)中没有准备好的数据报(no datagram ready),所以应用程序的进程会被阻塞(process blocks in call to recvfrom),等待数据。
- 当内核中有数据报准备好(datagram ready)后,内核会将数据报从内核空间复制到用户空间(copy datagram,copy data from kernel to user)。
- 数据复制完成(copy complete)后,系统调用返回成功(return OK),应用程序的进程解除阻塞,并可以处理接收到的数据报(process datagram)。
阻塞IO模型的特点
| 特点 | 说明 |
|---|---|
| 实现和使用 | 简单,易于实现和使用 |
| 数据情况 | 数据未准备好或无法立即发送时,用户进程阻塞 |
| 性能影响 | 数据传输时用户进程占用 CPU 时间片,限制应用程序性能和可伸缩性 |
| 适用场景 | 适用于单线程、同步、串行的应用程序,如文件传输、打印机等 |
# 非阻塞IO模型
既然已经了解了阻塞IO模型,那么非阻塞IO也就能明白其特性了,就是应用B发起读取数据申请时,内核数据没有准备好会立即告诉应用B,不用让B继续等待。
实现非阻塞IO的方式一般是通过轮询或者事件驱动的方式。
- 轮询就是程序会不断地询问IO操作是否完成,没有完成就继续执行其他操作,知道IO操作完成为止。通俗点讲,就是我去饭店点了一份饭,隔一段时间就问下服务员饭做好了么?
- 事件驱动则是通过注册事件回调函数,当IO操作完成时自动调用该回调函数,从而实现非阻塞IO操作。通俗点讲,就是我去饭店点完饭后,我给服务员说饭做好了主动告诉我一下。
非阻塞IO流程
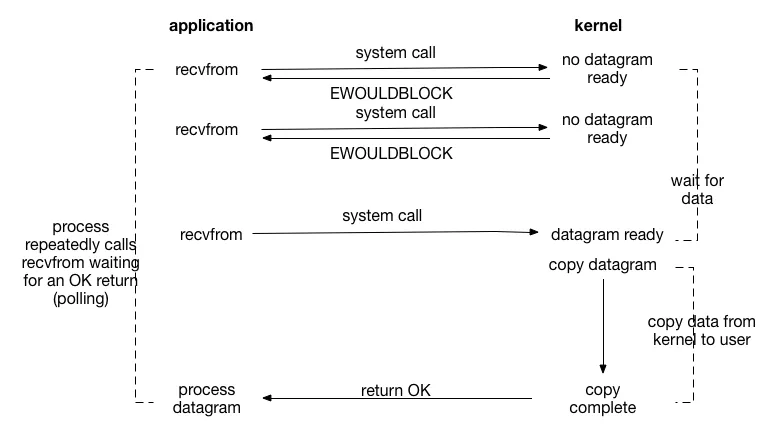
应用程序(application)端:
- 应用程序发起
recvfrom系统调用,请求接收数据报(datagram)。 - 当内核中没有准备好的数据报(no datagram ready)时,系统调用不会阻塞进程,而是立即返回一个错误码
EWOULDBLOCK,表示当前没有数据可接收。 - 应用程序的进程不会像阻塞 I/O 那样一直等待,而是会反复调用
recvfrom(即轮询 polling),不断地检查数据是否准备好。 - 直到某次调用
recvfrom时,内核中有数据报准备好(datagram ready)。
内核(Kernel)端:
- 内核一直等待数据到来(wait for data)。
- 当数据报准备好后,内核将数据报从内核空间复制到用户空间(copy datagram,copy data from kernel to user)。
- 数据复制完成(copy complete)后,系统调用返回成功(return OK)给应用程序,此时应用程序可以处理接收到的数据报(process datagram)。
accept 函数:
- 非阻塞 I/O 下不阻塞,无新连接请求时立即返回 -1,设置
errno为EAGAIN或EWOULDBLOCK。 - 常与
select、poll、epoll等 I/O 多路复用机制配合,处理新连接时可将客户端套接字设为非阻塞模式,需谨慎处理返回值和错误码,避免死循环或错误逻辑,可使用状态机处理 I/O 事件。
#include <sys/socket.h>
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);sockfd:是一个监听套接字的文件描述符,通常是由socket()函数创建并通过bind()和listen()函数配置好的。addr:是一个指向struct sockaddr结构的指针,用于存储客户端的地址信息(如果不关心客户端地址可以设为NULL)。addrlen:是一个指向socklen_t类型的指针,存储addr结构体的长度,在调用accept之前应该初始化为addr的长度,调用之后存储实际存储客户端地址的长度。
read 函数:
- 非阻塞 I/O 下立即返回,无数据时返回 -1,
errno设为EAGAIN或EWOULDBLOCK。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);fd:是文件描述符,可以是文件、套接字等的描述符。buf:是一个指向存储读取数据的缓冲区的指针。count:是要读取的字节数。
# IO多路复用
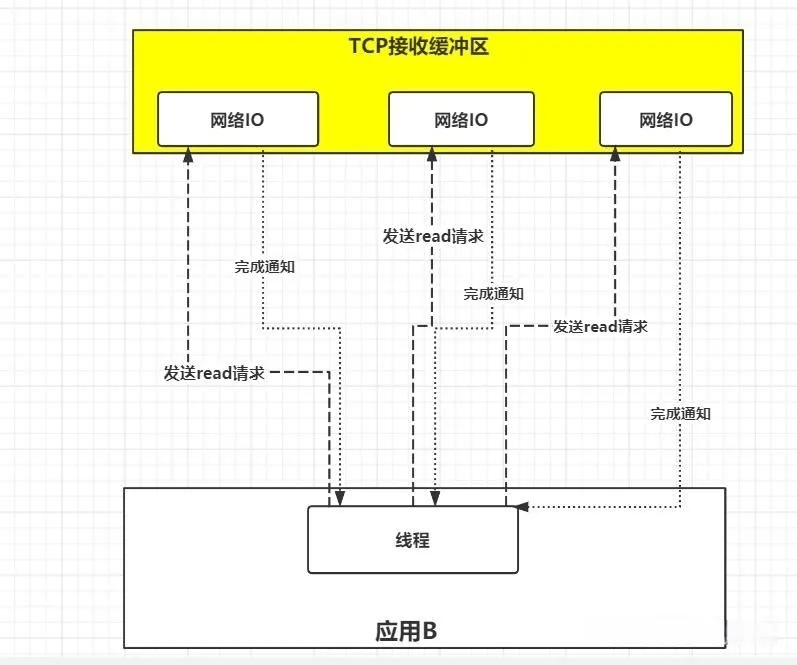
了解前,首先思考一个问题,假设在并发的环境中,可能会有多个应用程序向应用B发送消息数据,那么这种情况应用B就必须创建多个线程去读取数据,此时的情况如下图:
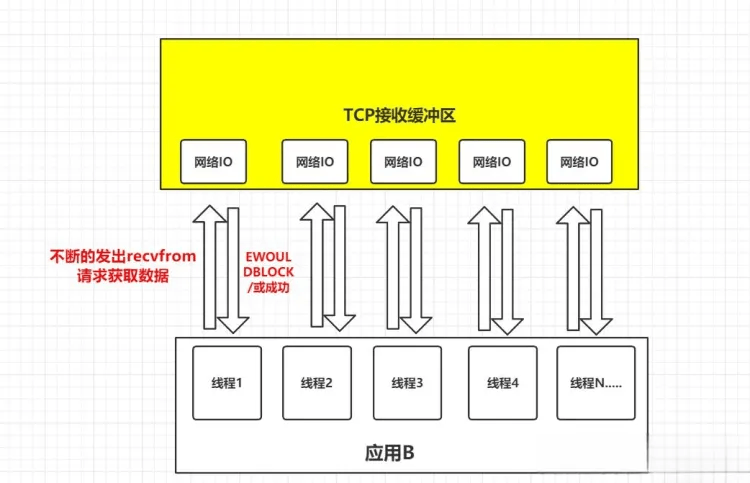
如上图,并发情况下服务器可能瞬间收到大量的请求,这种情况下应用B就需要创建大量的线程去读取数据,同时又因为应用线程不知道什么时候会有数据读取,为了保证消息数据能够即使读取到,那么这些线程就必须不断轮询向内核发送请求来读取数据。
这样的话,不仅可能会导致服务器崩溃,还会浪费大量资源。
那如果可以由一个线程监控多个网络请求(在linux系统中把所有的网络请求以一个fd文件描述符来标识),这样的话只需要一个或者少量的线程就可以完成数据状态询问的操作,当数据准备就绪之后再分配对应的线程去读取数据,这样就可以节省出大量的线程资源出来。没错上面就是IO复用模型的思路。
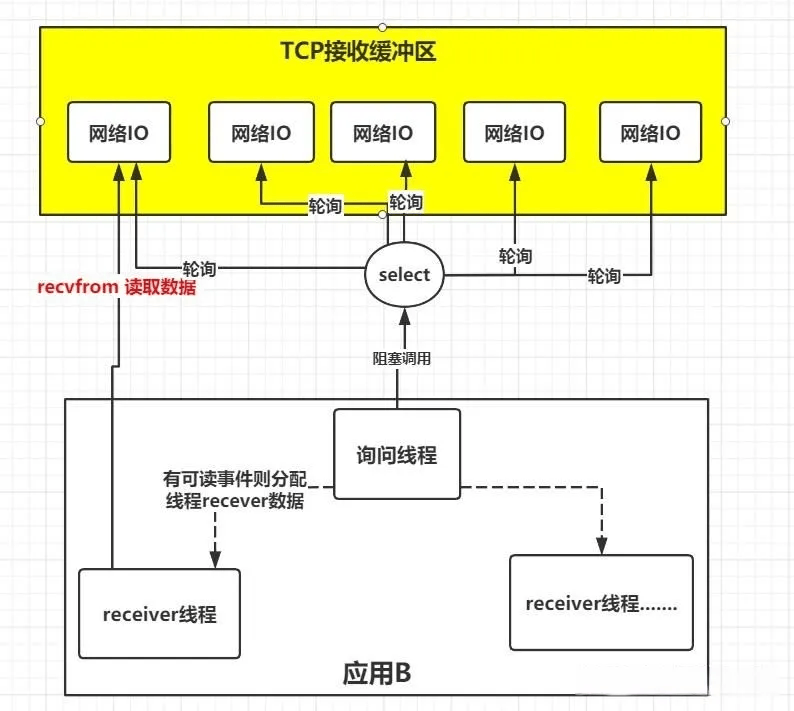
如上图所示,IO复用模型的思路就是系统提供了一种函数可以同时监控多个fd的操作,这个函数一般就是我们常说的select、poll、epoll函数(后面再仔细了解),应用线程通过调用select函数就可以同时监控多个fd,只要其中有任何一个数据状态准备就绪,selet函数就会返回可读状态,然后询问线程再去通知处理数据的线程,对应的线程再发起请求去读取数据。
多路复用IO流程如下
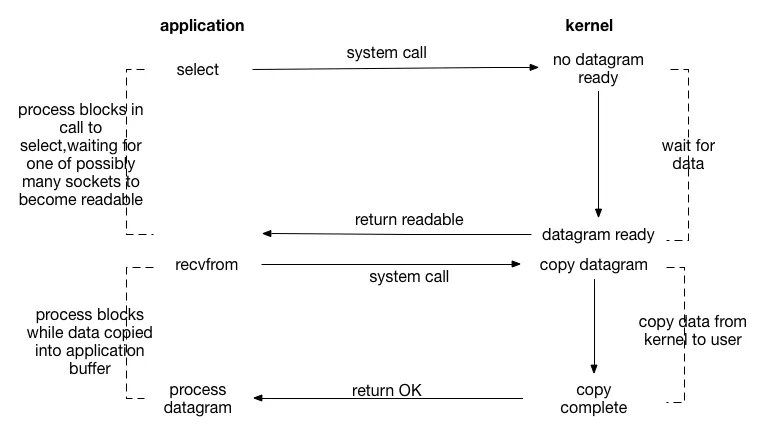
应用程序(application)端:
- 应用程序调用
select系统调用,该调用会阻塞进程(process blocks in call to select),目的是等待多个套接字(sockets)中的任意一个变为可读状态(waiting for one of possibly many sockets to become readable)。 - 当
select检测到有套接字可读(即有数据报准备好,datagram ready)时,select调用返回,表示有套接字可以进行读取操作(return readable)。 - 然后应用程序调用
recvfrom系统调用去接收数据。此时进程会再次阻塞(process blocks while data copied into application buffer),直到内核将数据报从内核空间复制到应用程序的缓冲区(copy datagram,copy data from kernel to user)。 - 数据复制完成(copy complete)后,
recvfrom调用返回成功(return OK),应用程序可以处理接收到的数据报(process datagram)。
内核(Kernel)端:
- 内核一直等待数据到来(wait for data),直到有数据报准备好。
- 当数据报准备好后,内核会将数据报的状态告知
select系统调用,使其返回可读的信息给应用程序。 - 在
recvfrom调用时,内核负责将数据报从内核空间复制到用户空间。
关于select、poll、epoll的具体分析后面题解再讲
# 信号驱动式IO
了解前还是先思考一个问题,select采用轮询的方式监控多个fd,通过不断的轮询fd的可读状态来了解是否有可读的数据,但通常大部分情况下的轮询都是无效的,那怎么才能减少这种无效的轮询判断呢?能不能让数据准备就绪后主动通知呢,这样就减少了无脑的轮询,所以就衍生了信号驱动IO模型
信号驱动IO通过调用sigaction的时候建立一个SIGIO的信号联系,当内核数据准备就绪后再通过SIGIO通知线程数据准备好的可读状态,然后线程收到信号后再向内核发起读取数据的请求,因为这种情况下也不会发生阻塞,所以一个应用线程也可以同时监控多个fd
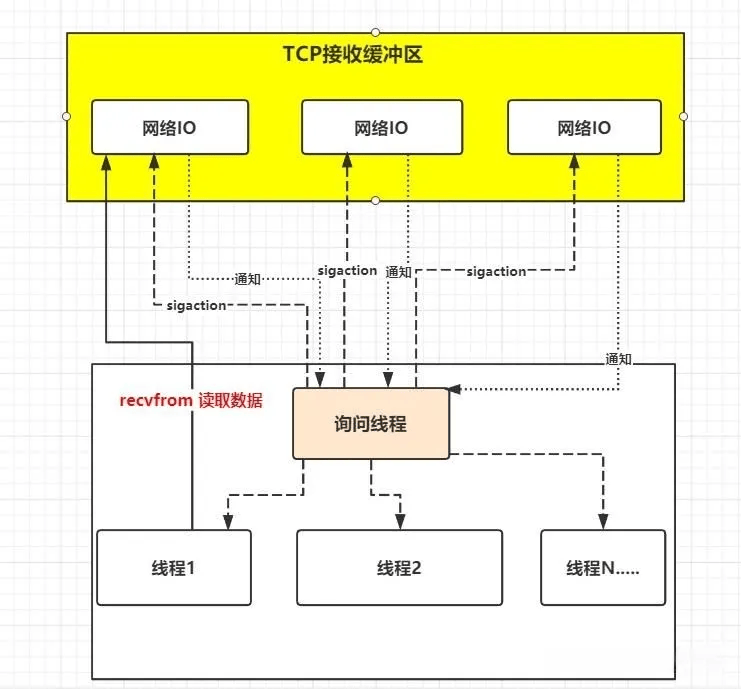
信号驱动IO的流程
应用程序(application)端:
- 应用程序首先通过
sigaction系统调用创建一个sigio(信号 I/O)处理程序(create sigio process handler)。此时,即使数据还未准备好(no datagram ready),该系统调用也会立即返回,应用程序可以继续执行其他操作(process continues executing),而不是像阻塞 I/O 那样被阻塞。 - 当内核中有数据报准备好(datagram ready)时,内核会向应用程序提交
sigio信号(submit sigio),触发之前注册的sigio处理程序(sigio handler)。 - 在
sigio处理程序中,应用程序通常会调用recvfrom系统调用来接收数据。此时,进程会阻塞(process blocks while data copied into application buffer),直到内核将数据报从内核空间复制到应用程序的缓冲区(copy datagram,copy data from kernel to user)。 - 数据复制完成(copy complete)后,
recvfrom调用返回成功(return OK),应用程序可以处理接收到的数据报(process datagram)。
内核(Kernel)端:
- 内核一直等待数据到来(wait for data)。
- 当数据报准备好后,内核向应用程序发送
sigio信号,通知应用程序可以进行数据接收操作。 - 在
recvfrom调用时,内核负责将数据报从内核空间复制到用户空间。
| 类型 | 内容 |
|---|---|
| 优点 | 可避免处理多个描述符时阻塞进程,提高并发性能与响应能力;避免轮询机制开销,减少 CPU 占用 |
| 缺点 | 信号处理耗时,不适合高速 I/O 操作;信号不可靠,可能丢失;多个描述符切换时可能出现竞争条件和死锁问题 |
# 异步IO
通过对上面IO的模型了解,虽然效率有了很大的提升,但是通过对上面两个IO模型的分析,也会发现不管是IO复用还是信号驱动读取一个数据都需要发起两阶段的请求,先询问数据状态是否准备就绪,然后第二次请求读取数据。
还是了解前先思考一个问题,为什么读取数据非要先发起一个询问数据状态的请求,然后再发起真正的读取数据请求,能不能只发送一个请求告诉内核我要读取数据,然后让内核主动去完成剩下的所有事情呢?
所以就有这种方案,应用只需要向内核发送一个read请求,告诉内核要读取数据然后即刻返回。内核收到请求后会建立一个信号联系,当数据准备就绪后,会主动把数据从内核复制到用户空间,等到所有操作完成后,内核会通知告诉应用。上面就是异步IO的思路。
异步IO的流程如下
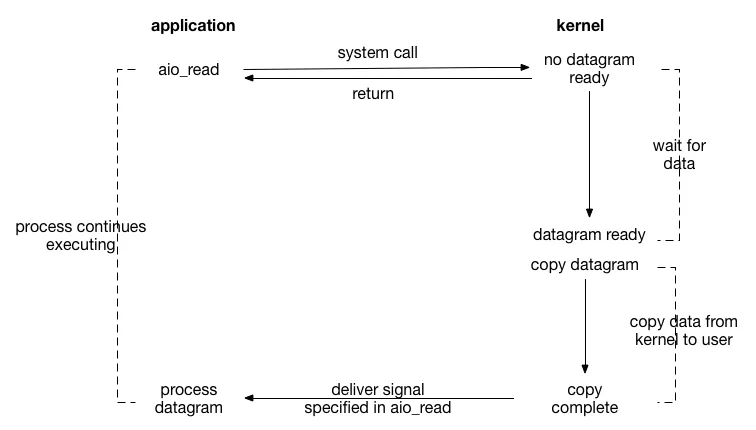
应用程序(application)端:
- 应用程序调用
aio_read系统调用发起异步读操作(system call aio_read)。此时,无论数据是否准备好,该调用都会立即返回(return),应用程序的进程可以继续执行其他任务(process continues executing),而不会被阻塞等待 I/O 操作完成。 - 当内核中的数据报准备好(datagram ready)后,内核会在后台进行数据报的复制操作(copy datagram,copy data from kernel to user),将数据从内核空间复制到用户空间。
- 数据复制完成(copy complete)后,内核会按照
aio_read调用中指定的方式向应用程序发送信号(deliver signal specified in aio_read),通知应用程序数据已准备好可以进行处理。 - 应用程序收到信号后,就可以处理接收到的数据报(process datagram)。
内核(Kernel)端:
- 内核一直等待数据到来(wait for data)。
- 当数据报准备好后,内核负责将数据报从内核空间复制到用户空间,并在完成后向应用程序发送信号。
# 五种IO模型针对阻塞对比
| IO 模型 | 是否阻塞 | 说明 |
|---|---|---|
| 阻塞 I/O(Blocking I/O) | 是 | 调用 I/O 操作(如recvfrom<br><br>)时,进程会一直阻塞,直到数据准备好并完成复制到用户空间才返回 |
| 非阻塞 I/O(Non-blocking I/O) | 否 | 调用 I/O 操作(如recvfrom<br><br>)时,如果数据未准备好,立即返回错误或状态,进程可继续执行其他操作,但通常需要轮询检查数据是否就绪 |
| I/O 多路复用(I/O Multiplexing) | 调用多路复用函数(如select<br><br>、poll<br><br>、epoll_wait<br><br>)时阻塞 |
调用多路复用函数时,进程阻塞等待所监听的多个 I/O 事件中有一个或多个就绪,返回后再进行具体 I/O 操作(如recvfrom<br><br>)时可能阻塞 |
| 信号驱动 I/O(Signal-driven I/O) | 调用recvfrom<br><br>等接收数据函数时阻塞 |
设置信号处理程序(sigaction<br><br>)时不阻塞,内核数据准备好发送信号后,在信号处理程序中调用接收数据函数时可能阻塞 |
| 异步 I/O(Asynchronous I/O) | 否 | 发起 I/O 请求(如aio_read<br><br>)后立即返回,进程无需等待 I/O 完成即可继续执行其他任务,内核在后台完成 I/O 操作并在完成时通知进程 |
# select、poll、epoll之间有什么区别?
# 总结分析
| 多路复用机制 | 数据结构 | 最大连接数 | 遍历方式 | 工作模式 | 适用场景 |
|---|---|---|---|---|---|
| select | 固定长度数组表示文件描述符集 | 通常为 1024 | 每次调用需重新构建和检查文件描述符集 | 无特定模式 | 小规模连接场景 |
| poll | 动态数组存储文件描述符 | 无限制 | 每次调用需遍历全部描述符 | 无特定模式 | 连接数较多,但对效率要求不是极高的场景 |
| epoll | 基于事件通知,有红黑树和就绪链表等数据结构 | 无限制 | 仅处理实际发生变化的描述符 | 边缘触发(ET)和水平触发(LT)模式 | 高并发场景 |
# 深入分析
介绍select、poll、epoll之前,首先了解一下Linux操作系统中的基础概念:
- 用户空间 / 内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操作系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。 - 进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的,并且进程切换是非常耗费资源的。 - 进程阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得了CPU资源),才可能将其转为阻塞状态。当进程进入阻塞状态,是不占用CPU资源的。 - 文件描述符
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。 - 缓存I/O
缓存I/O又称为标准I/O,大多数文件系统的默认I/O操作都是缓存I/O。在Linux的缓存I/O机制中,操作系统会将I/O的数据缓存在文件系统的页缓存中,即数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
# Select
# select函数分析
int select(int maxfdp1,fd_set *readset,fd_set *writeset,fd_set *exceptset,const struct timeval *timeout);fd_set 本质上是一个位图,位图中的每一位对应一个文件描述符的状态。大小为 1024 位(与 FD_SETSIZE 定义相关),每一位表示一个文件描述符。位图中的每一位的值为 1 表示该文件描述符需要监视,为 0 表示不需要监视。
再了解下三种监视类型,分别存储在不同的 fd_set 中:
- 可读事件(readfds):监视文件描述符是否有数据可读。
- 可写事件(writefds):监视文件描述符是否可写(即是否可以发送数据)。
- 异常事件(exceptfds):监视文件描述符上是否有异常情况(如带外数据)。
参数说明:
- maxfdp1:
- 表示要监视的文件描述符的范围,通常是最大文件描述符加 1。
- 例如,如果要监视的文件描述符为
3、5、7,则maxfdp1为8。这是因为文件描述符从 0 开始,所以要确保能覆盖所有要监视的文件描述符,需要使用最大文件描述符加 1。
- readset:
- 指向
fd_set类型的指针,用于监视可读事件的文件描述符集合。 fd_set是一个特殊的文件描述符集合,可通过FD_SET、FD_CLR、FD_ISSET、FD_ZERO等宏操作。- 在调用
select之前,使用FD_SET将需要监视可读事件的文件描述符添加到readset中。
- writeset:
- 指向
fd_set类型的指针,用于监视可写事件的文件描述符集合。 - 操作方式与
readset类似,使用FD_SET可将需要监视可写事件的文件描述符添加到writeset中。
- exceptset:
- 指向
fd_set类型的指针,用于监视异常事件的文件描述符集合。 - 同样,使用
FD_SET可将需要监视异常事件的文件描述符添加到exceptset中。
- timeout:
- 指向
struct timeval类型的指针,用于设置select的超时时间。 struct timeval结构体通常定义如下:
struct timeval {
long tv_sec; // 秒数
long tv_usec; // 微秒数
};-
三种情况:
-
timeout为NULL:select将一直阻塞,直到至少一个文件描述符就绪或出错。 -
timeout中的tv_sec和tv_usec都为 0:select立即返回,进行非阻塞检查。 -
具体的
tv_sec和tv_usec值:select会阻塞相应的时间,超时后返回,即使没有文件描述符就绪。
函数返回值:
-
若成功返回,返回值为就绪文件描述符的数量。
-
若超时,返回 0。
-
若出错,返回 -1,并设置
errno为相应的错误码,例如: -
EBADF:文件描述符不合法。 -
EINTR:被信号中断。 -
EINVAL:参数无效。
# 运行流程如下:
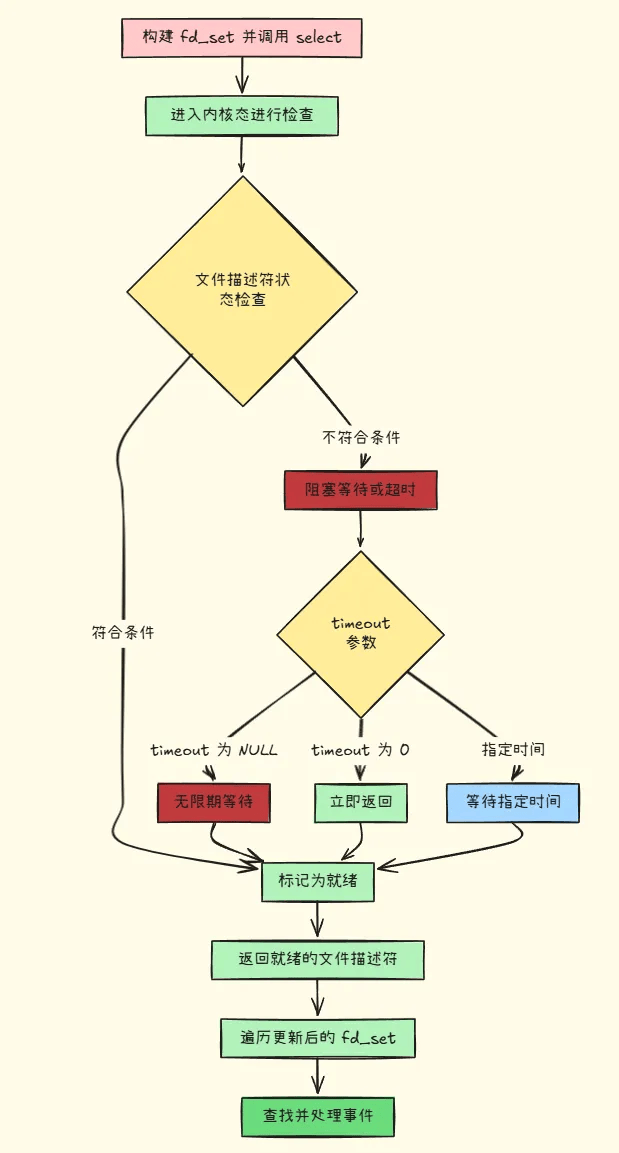
# 优缺点分析
| 方面 | 说明 |
|---|---|
| 优势 | 一个线程内可同时处理多个 socket 的 I/O 请求,与同步阻塞模型不同,无需多线程;无需创建和维护进程 / 线程,节约系统开销 |
| 缺点 | 调用 select 函数时,fd_set 集合需从用户态拷贝到内核态,集合大时开销大;调用时内核要遍历所有 fd_set,集合大时开销大;内核对 fd_set 集合大小有限制 |
# Poll
# poll函数分析
int poll(struct pollfd *fds, nfds_t nfds, int timeout);参数分析:
- fds:
- 指向
struct pollfd结构体数组的指针,该结构体包含要监视的文件描述符及其相应的事件信息。 - 可以通过操作
fds数组中的元素,设置每个文件描述符需要监视的事件(使用events),以及在poll调用返回后检查实际发生的事件(使用revents)。
- nfds:
- 表示
fds数组中元素的数量,即要监视的文件描述符的数量。
- timeout:
-
表示超时时间,单位是毫秒(ms)。
-
有以下三种情况:
-
若
timeout为-1:poll函数将一直阻塞,直到至少一个文件描述符上发生了感兴趣的事件。 -
若
timeout为0:poll函数立即返回,进行非阻塞检查。 -
若
timeout大于0:poll函数将阻塞等待,直到有事件发生或超时。
函数返回值:
-
若成功,返回值为发生事件的文件描述符的数量。
-
若超时,返回
0。 -
若出错,返回
-1,并设置errno为相应的错误码,常见错误码有: -
EFAULT:fds指针不合法。 -
EINTR:被信号中断。
# pollfd结构体分析
typedef struct pollfd {
int fd; // 需要被检测或选择的文件描述符
short events; // 对文件描述符fd上感兴趣的事件
short revents; // 文件描述符fd上当前实际发生的事件
} pollfd_t;参数分析:
- fd:
- 这是一个整数,表示要监视的文件描述符。
- 可以是文件、套接字、管道等的文件描述符。例如,对于一个监听套接字,其文件描述符可以存储在此处。
- events:
-
是一个
short类型的变量,用于指定用户希望监视该文件描述符的哪些事件。 -
可以使用一些预定义的宏来设置
events,例如: -
POLLIN:监视文件描述符是否可读。 -
POLLOUT:监视文件描述符是否可写。 -
POLLERR:监视文件描述符是否发生错误。 -
POLLHUP:监视文件描述符是否被挂起。 -
POLLNVAL:监视文件描述符是否无效。 -
可以使用位或操作符
|来组合多个事件。例如,如果想要监视一个文件描述符是否可读和可写,可以这样设置:
struct pollfd pfd;
pfd.events = POLLIN | POLLOUT;- revents:
- 也是一个
short类型的变量,由内核填充,用于表示实际发生在该文件描述符上的事件。 - 当调用
poll函数后,内核会根据实际发生的情况设置revents的值。 - 程序可以通过检查
revents的值,使用&操作符来判断发生了哪些事件。例如:
if (pfd.revents & POLLIN) {
// 文件描述符可读,进行相应操作
}
if (pfd.revents & POLLOUT) {
// 文件描述符可写,进行相应操作
}# 运行流程如下
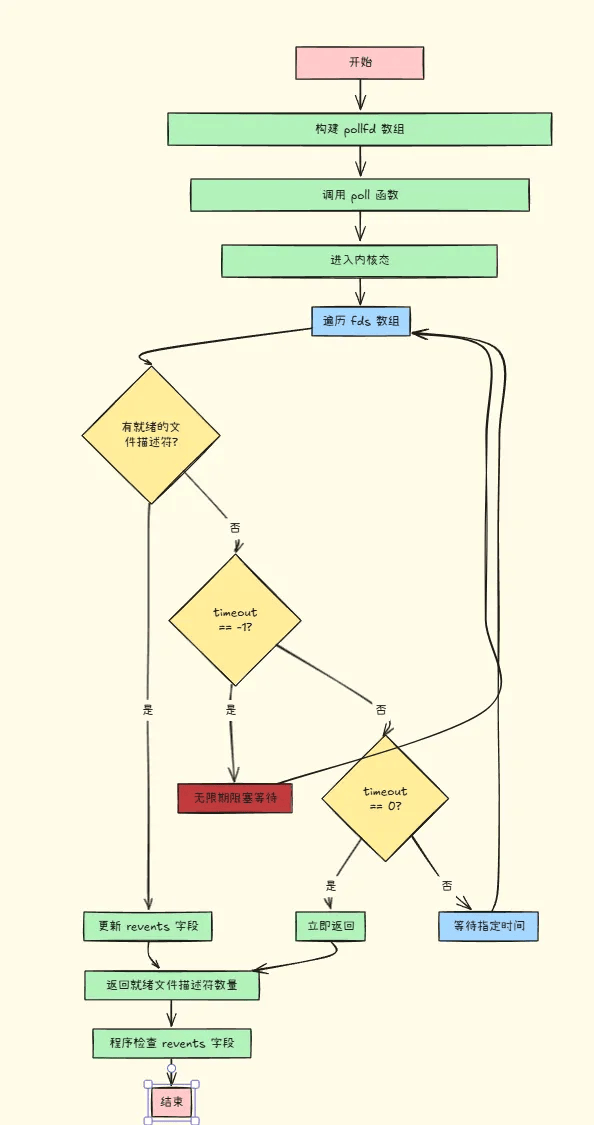
# Epoll
# epoll_create 函数
int epoll_create(int size);功能:
- 创建一个新的
epoll实例,并返回一个文件描述符epfd,该文件描述符用于后续的epoll操作。 size参数在较新的 Linux 内核中已被忽略,但仍需传入一个大于 0 的值。
# epoll_ctl 函数
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);功能:
- 用于对
epoll实例进行控制操作,如添加、修改或删除文件描述符及相应的事件。
参数说明:
-
epfd:由epoll_create创建的epoll实例的文件描述符。 -
op:操作类型,包括: -
EPOLL_CTL_ADD:添加文件描述符到epoll实例。 -
EPOLL_CTL_MOD:修改epoll实例中文件描述符的事件。 -
EPOLL_CTL_DEL:从epoll实例中删除文件描述符。 -
fd:要操作的文件描述符,如套接字文件描述符。 -
event:指向struct epoll_event结构体的指针,该结构体描述了文件描述符的事件信息。
# epoll_wait 函数
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);功能:
- 等待
epoll实例上的事件发生。
参数说明:
-
epfd:epoll实例的文件描述符。 -
events:指向struct epoll_event结构体数组的指针,用于存储发生的事件。 -
maxevents:events数组的最大长度。 -
timeout:超时时间,单位是毫秒。 -
-1:阻塞等待,直到有事件发生。 -
0:立即返回,不阻塞。 -
大于 0:阻塞等待相应毫秒数,超时后返回。
# epoll_event结构体定义
struct epoll_event {
uint32_t events; // 感兴趣的事件
epoll_data_t data; // 用户数据
};
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;events可以是EPOLLIN(可读)、EPOLLOUT(可写)、EPOLLERR(错误)等事件标志的组合。data是一个联合体,可存储用户自定义数据,最常用的是存储文件描述符fd。
# 运行流程如下
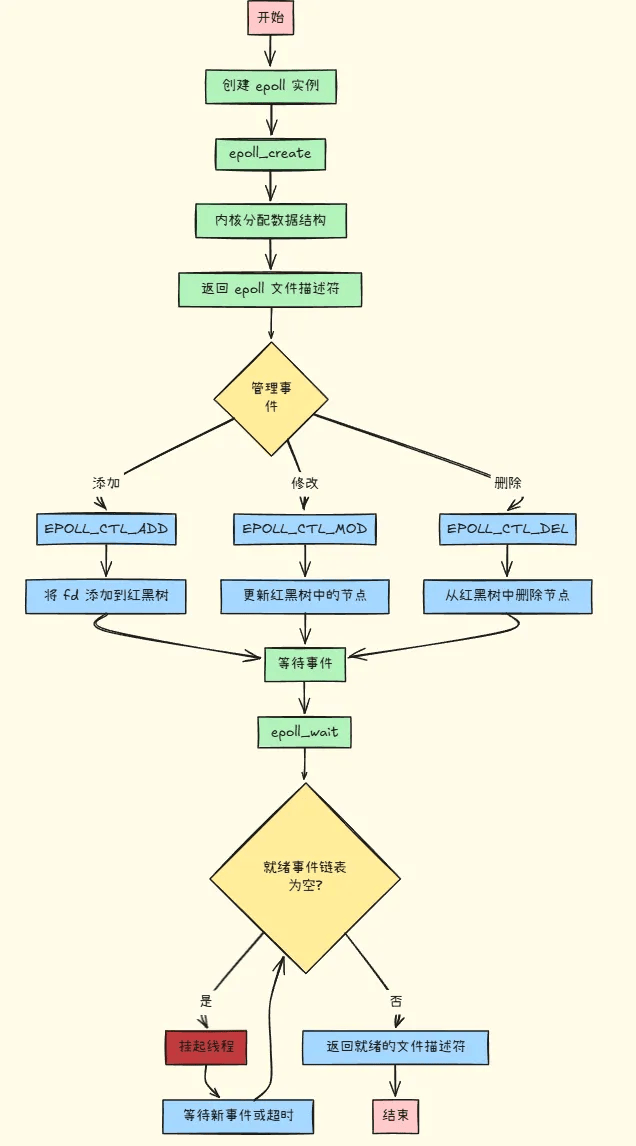
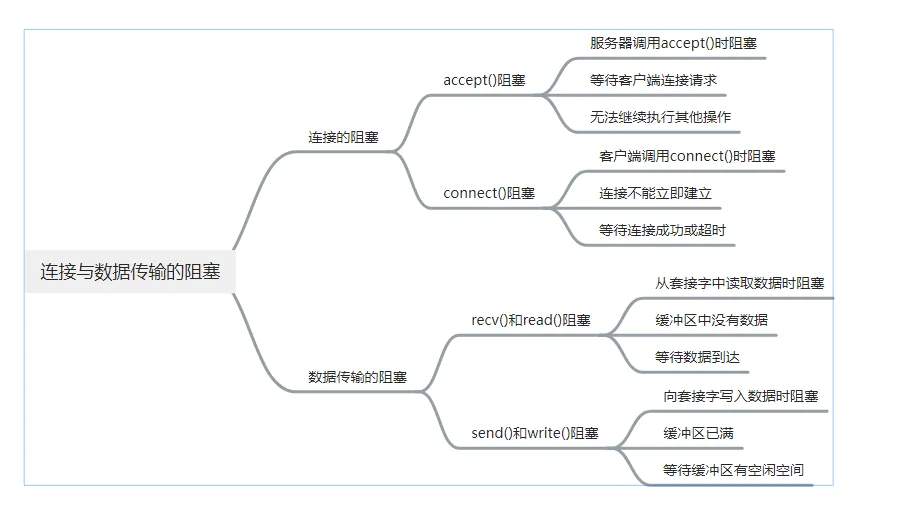
# 为什么网络IO会被阻塞?
# 总结分析
| 阻塞原因 | 具体说明 |
|---|---|
| 等待数据到达或发送完成 | 进程从网络套接字读取数据,若数据未到则进入阻塞,直至数据到达;数据发送时,若缓冲区无空闲空间,发送操作也会阻塞,直至有空间 |
| 系统资源有限 | 当网络缓冲区、连接数等系统资源被占满,新的 I/O 请求会被阻塞,需等待资源释放 |
| 默认的阻塞行为 | 多数网络 API(如 recv、send、accept 等)默认设置为阻塞模式,调用时条件不满足,调用者会等待,直至 I/O 操作完成 |