✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
本文详细解析了操作系统中的用户态与内核态的区别与联系,阐述了两者在权限级别、内存空间分配及切换机制上的设计原理,强调了系统调用、中断和异常等触发态切换的具体场景。文章还深入探讨了Reactor模式,介绍了其基于IO多路复用与线程池技术的事件驱动架构,分别解析了单线程、多线程及主从多线程三种实现模型及其性能优化。最后,文章讲解了虚拟内存的产生背景、局部性原理及其多次性、对换性和虚拟性特征,揭示了虚拟内存如何突破物理内存限制提升系统运行效率,具有较强的技术指导和实用价值。
2025-01-15🌱上海: ☀️ 🌡️+4°C 🌬️↓14km/h
什么是用户态和内核态?
# 总结分析
| 运行模式 | 权限级别 | 可执行操作 | 优势 |
|---|---|---|---|
| 用户态 | 较低 | 不能直接访问硬件或进行特权操作,需通过系统调用让内核执行敏感操作 | 安全性高,程序问题不影响操作系统稳定性 |
| 内核态 | 最高 | 可直接访问硬件资源并执行如内存管理、进程调度等特权操作 | 能高效管理硬件与系统资源 |
# 深入分析
其实简单来说内核态就是操作系统运行线程,用户态就是线程执行用户自己的程序
用户态不能直接使用系统资源,也不能改变CPU的工作状态,只能访问到用户程序自己的存储空间
内核态可以直接使用计算机所有的硬件资源,需要执行操作系统的程序就必须转换到内核态才能执行,这样也保证了安全性和稳定性。
每个进程都有两个栈,分别是用户栈和内核栈,对应用户态和内核态的使用
# 为什么要区分用户态和内核态?
凡是涉及到IO读写、内存分配等硬件资源的操作时,往往不能直接操作,而是通过系统调用的过程让程序从旁那个用户态切换到内核态运行。
因为在CPU的所有指令中,有部分指令是非常危险的,操作不当就会导致系统崩溃,并且对于硬件的操作是非常复杂的,参数繁多,出问题的几率很大。就像我们开发项目一样,生产数据库一般只有高权限的开发人员才可以进行操作,就是避免因为操作不当导致的出现问题。
上面提到了CPU指令,这里我们大概了解一下,对于CPU指令集是有权限分级的,不同级别权限可以使用的CPU指令集是有限的,以InterCPU为例,把CPU指令集操作的权限由高到低分为4级:
- ring0
- ring1
- ring2
- ring3 权限最低,仅能使用常规的CPU指令集,不能使用操作硬件资源的CPU指令集,比如IO读写、网卡访问、申请内存等。
而在Linux系统中仅采用ring0和ring3这两个权限,ring0被叫做内核态完全在操作系统内核中运行,ring3被叫做用户态,在应用程序中运行。
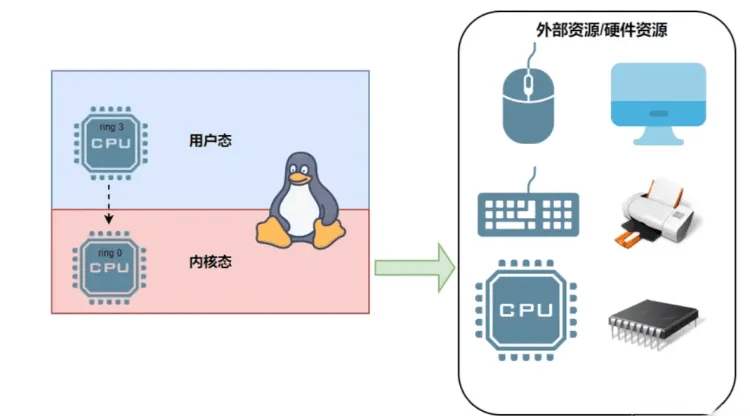
# 用户态和内核态的空间
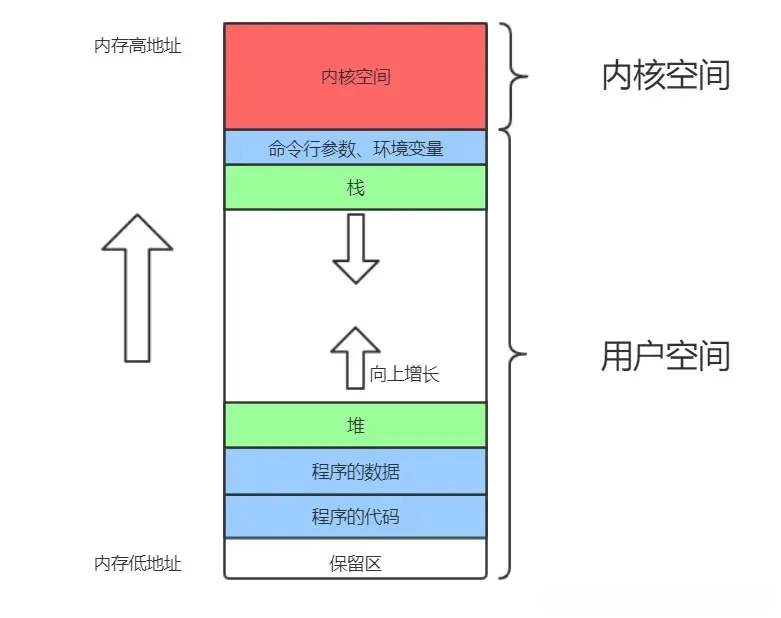
在对内存资源的使用上,操作系统对用户态和内核态也做了限制,每个进程创建都会分配虚拟空间地址,这里先大搞了解下进程的内存结构
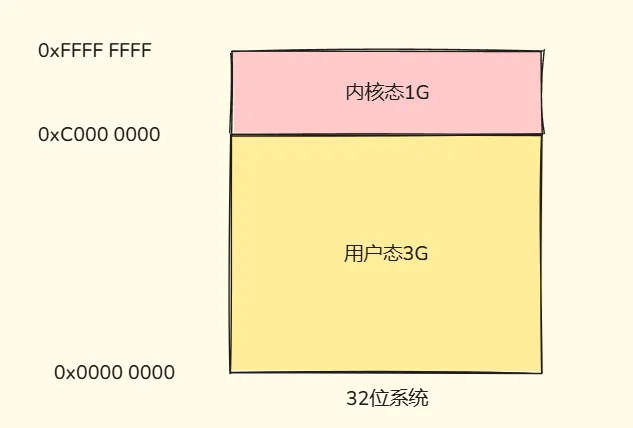
以Linux32位操作系统为例,它的寻址空间范围是2的32次方,算下来就是4G,而操作系统会把虚拟空间地址分为两部分,分别为内核空间和用户空间,高位的 1G(从虚拟地址 0xC0000000 到 0xFFFFFFFF)由内核使用,而低位的 3G(从虚拟地址 0x00000000 到 0xBFFFFFFF)由各个进程使用。
内核态的地址空间存放整个内核的代码、所有的内核模块以及内核维护的数据,这部分是共享的,所有进程的内核态逻辑地址是共享同一块内存地址。同时内核态可以操作全部范围的虚拟空间地址,并且属于内核态的高位虚拟空间地址必须由内核态操作。
从面可以看到。操作系统不仅从指令集权限区分了用户态和内核态,还限制了内存资源的使用。
# 用户态和内核态的切换
用户态和内核态的切换是有开销,但是开销具体在什么地方,我们来了解一下
- 保留用户态现场(上下文、寄存器、用户栈等)
- 复制用户态参数,用户栈切到内核栈,进入内核态
- 额外的检查(因为内核代码对用户不信任)
- 执行内核态代码
- 复制内核态代码执行结果,回到用户态
- 恢复用户态现场(上下文、寄存器、用户栈等)
但实际上操作系统会比上述的更复杂,可以从上面发现一次切换经历了用户态-》内核态-》用户态。
用户态主动切换到内核态,需要有入口才行,实际上内核态提供了同一的入口
下面是linux整体架构图
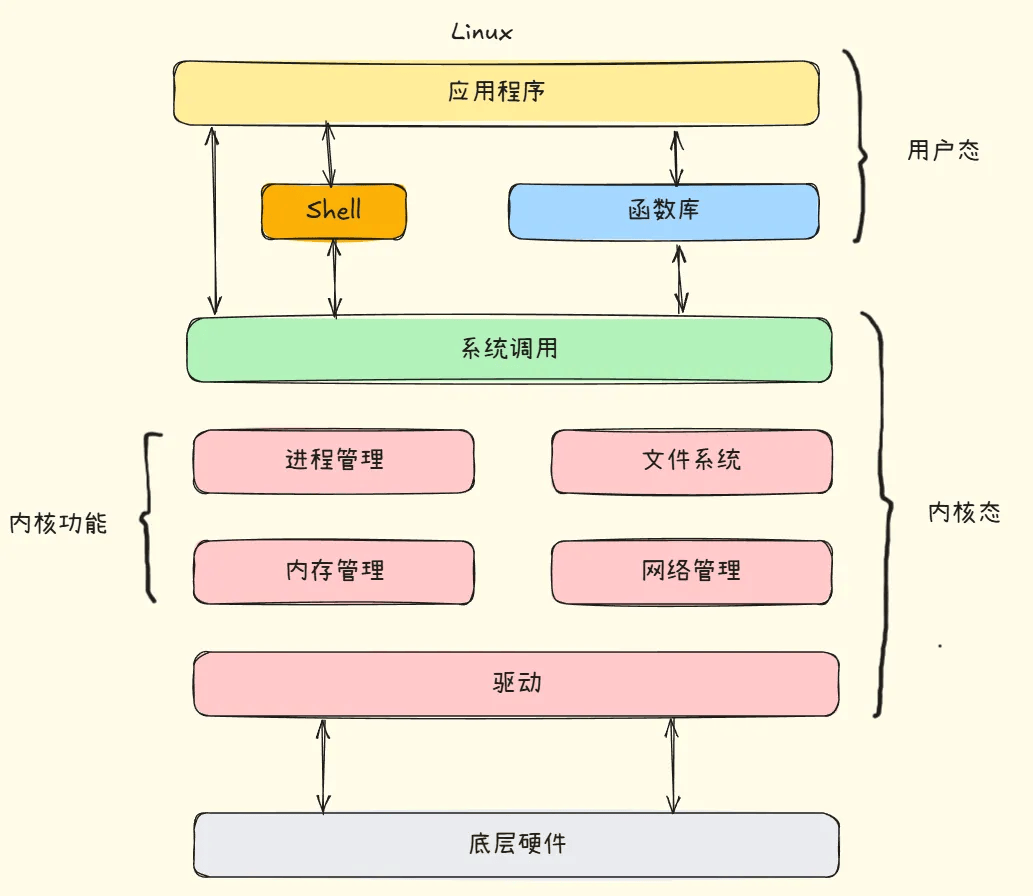
从上图可以看到内核提供了一组通用的访问接口,这些接口就叫做系统调用,
库函数通过屏蔽这些复杂的底层实现细节对系统调用进行封装,提供了简单的基本接口给程序员进行开发,从而更加关注上层的逻辑实现。
Shell俗称命令行,也是一种特殊的应用程序,它也是可编程的,拥有标准的Shell语法,估计大部分开发者都写过简单的Shell脚本提高工作效率。
# 什么情况会导致用户态到内核态切换
- 系统调用:用户态进程主动切换到内核态的方式,用户态进程通过系统调用向操作系统申请资源完成工作,例如 fork()就是一个创建新进程的系统调用,系统调用的机制核心使用了操作系统为用户特别开放的一个中断来实现,如Linux 的 int 80h 中断,也可以称为软中断
- 异常:当 C P U 在执行用户态的进程时,发生了一些没有预知的异常,这时当前运行进程会切换到处理此异常的内核相关进程中,也就是切换到了内核态,如缺页异常
- 中断:当 C P U 在执行用户态的进程时,外围设备完成用户请求的操作后,会向 C P U 发出相应的中断信号,这时 C P U 会暂停执行下一条即将要执行的指令,转到与中断信号对应的处理程序去执行,也就是切换到了内核态。如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后边的操作等。
其实通过用户态和内核态的切换,可以扩展到进程的上下文切换,线程的上下文切换。
这里简单提一下
首先,进程是由内核态管理和调度的,进程的切换只能发生在内核态,所以进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:
- 在保存内核态资源(当前进程的内核状态和CPU寄存器)之前,需要先把该进程的用户资源(虚拟内存、栈等)保存下来
- 在加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
线程上下文切换的话,相同进程间的线程是共享虚拟内存的,所以线程间的上下文切换,省去了虚拟内存的切换,只需要切换线程私有的栈及寄存器即可。
# 到底什么是Reactor?
# 总结分析
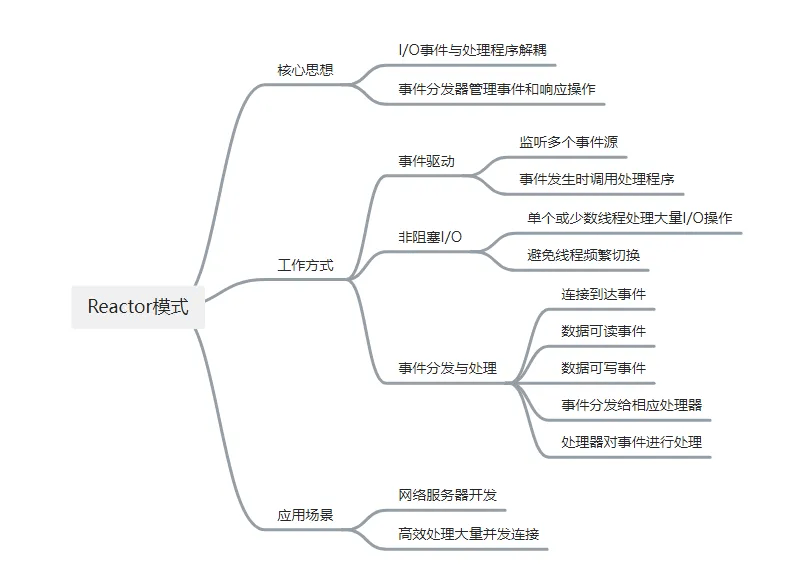
# 深入分析
Reactor英文解释为“反应堆”,但是通俗点来讲,Reacotr = IO多路复用 + 池化技术,将IO多路复用技术结池化技术(线程池进程池)结合的一种模式。IO多路服用负责统一监听事件,收到事件后派发给资源池中的某个线程或进程。
# Reactor模型
之前我们了解了五种IO模型,其中就提到了非阻塞IO和多路复用IO模型,其中非阻塞IO我还提到了两种方案,一种是轮询,一种是事件驱动,其实Reactor就是事件驱动模型的一种实现,同时它也采用了IO多路复用处理方案。
可以理解为Reactor模型中的反应器角色,类似于事件转发器(这点官方题解中也有提到),用来承接连接建立、IO处理以及事件分发
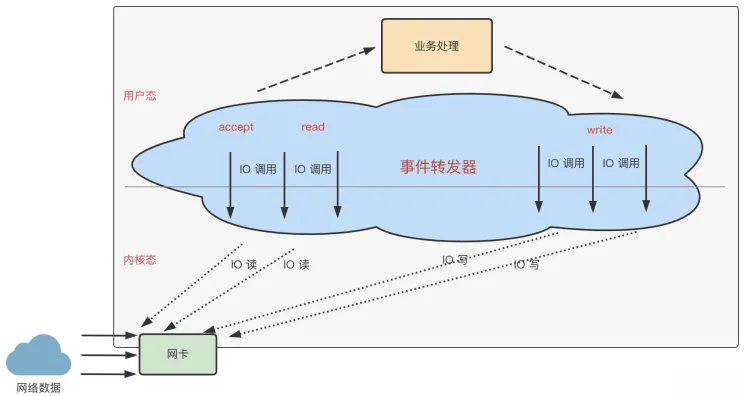
Reactor模式主要由Reator线程、Handlers处理器两大角色组成,它们的职业分别为:
- 主要负责连接建立、监听IO事件、IO事件读写以及将事件分发到Handlers处理器
- 后者主要负责非阻塞的执行业务处理逻辑
# 三种Reactor模型
Reactor模型在不同的阶段都有相关的优化策略,常见的有以下三种方式实现:
- 单线程模型(单Reactor单线程)所有组件都在一个线程中进行
- 多线程模型(单Reactor多线程)Reactor在主线程中监听事件,每当有事件发生时,将事件分发给工作线程池处理,一般是指在Worker端使用多线程来提升业务上的处理能力
- 主从多线程模型(多Reactor多线程)使用多个Reactor实例,每个Reactor管理一部分连接,并通过多线程处理事件。将建立连接和IO事件监听/读写以及事件分发两部分用不同的线程处理,同时为了提高事件处理的效率,通常可以使用线程池来处理IO事件监听/读写及事件分发这部分操作。
其实从某些方面看,主要由单线程和多线程两种模型,其中多线程模型就包含了多线程模型和主从多线程模型。多线程模型的演进分为两个方面:
- 升级Handler。通过线程池,使用多线程执行业务处理
- 升级Reactor,引入多个Selector(选择器),提升选择大量通道的能力。
# 单线程模型
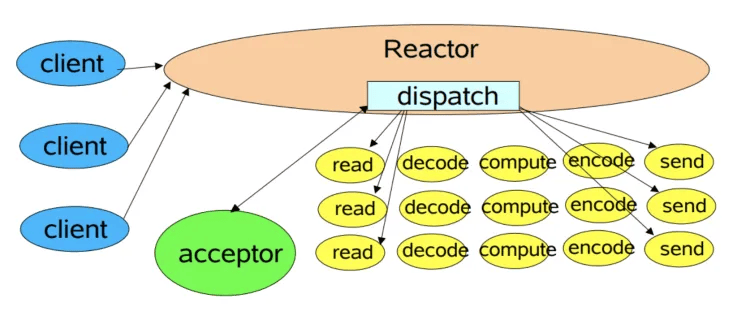
可以从图中看到,在Reactor单线程模型中,所有IO操作(连接建立、数据读写、事件分发)、业务处理都在是一个线程完成的。缺陷也很明显:
- 一个线程支持处理的连接数非常有限,CPU 很容易打满,性能方面有明显瓶颈;
- 当多个事件被同时触发时,只要有一个事件没有处理完,其他后面的事件就无法执行,这就会造成消息积压及请求超时;
- 线程在处理 I/O 事件时,Select 无法同时处理连接建立、事件分发等操作;
- 如果 I/O 线程一直处于满负荷状态,很可能造成服务端节点不可用。
因为所有操作都在用一条线程中执行,也带来了一个问题,当其中某个Handler阻塞时,会导致其他所有的Handler都无法执行,其他相应的操作也会阻塞,所以演进为多线程模型。
# 多线程模型
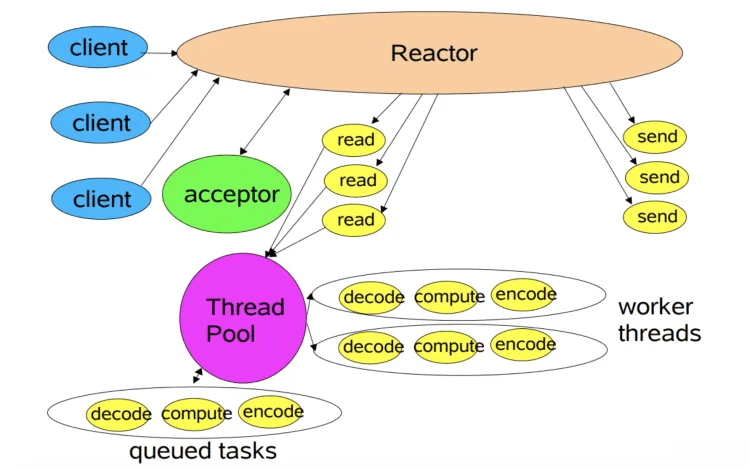
多线程模型将业务逻辑处理交给线程池中的多线程进行处理,不过除此之外,其他的操作比如连接建立、IO事件读写及事件分发等都是由一个线程完成,这点和单线程模型类似。
一般的请求中,耗时最长的一般就是业务处理,所以用一个线程池来处理业务操作,性能也提升了不少,但是连接建立、IO事件读取及事件分发完全由单线程处理,假如某个连接通过系统调用正在读取数据,此时相对于其他事件来说就是阻塞状态,新连接无法处理、其他连接的IO及查询IO读写、事件分发都无法完成。
对于Nginx、Netty这种对高性能、高并发要求极高的网络框架就不适用了,所以就演进了多Reactor多线程模型。
# 主从多线程模型
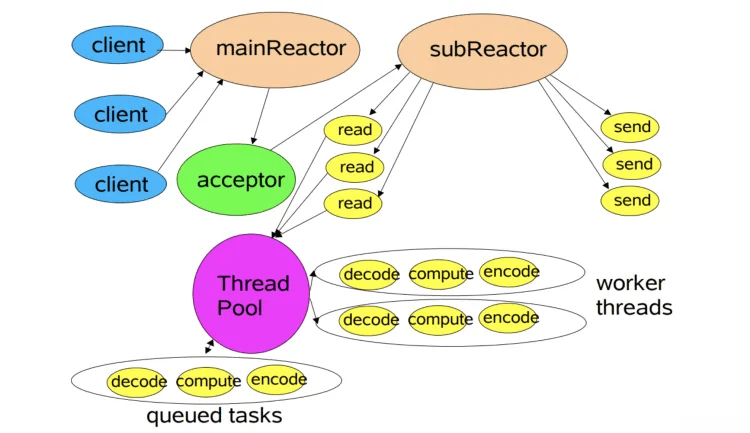
在上面的多线程模型中,主要缺陷就是在于同一间无法处理大量新连接、IO就绪事件;所以就可以使用多Reactor多线程模式
在主从模式中,主Reactor负责出建立的连接,其他Reactor负责处理IO读写事件/事件分发。这样就可以解决同一时间处理大量新连接并将其注册到其他Reactor上进行IO事件监听处理。同时由于IO事件监听及数据处理相对新连接处理更加耗时,所以采用线程池来处理,就能使更多就绪的IO事件及时处理。
简单来说,主从多线程模型就是由多个Reactor多线程组成,每个Reactor线程都有独立的Selector对象,部分Reactor仅负责处理客户端连接的accept事件,连接建立成功后将新创建的连接对象注册到其他负责进行IO读写事件的Reactor上,再由该Reactor分配线程池中的IO线程与其连接绑定,负责连接生命周期内所有的IO事件。
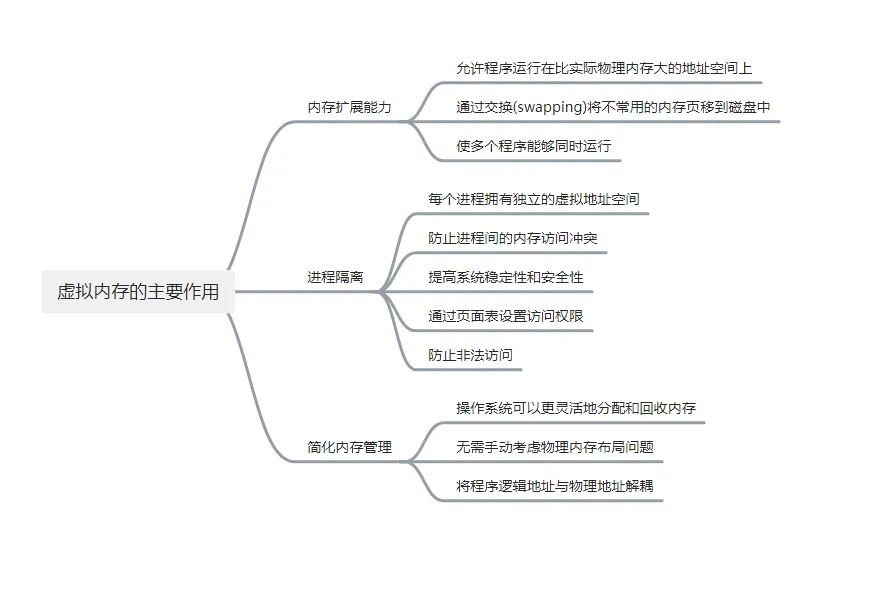
# 为什么要有虚拟内存?
# 总结分析
# 扩展知识
首先了解下传统存储管理方式的特征
- 一磁性:作业必须一次性全部装入内存后,才能开始运行
- 驻留性:作业被装入内存后,就一直驻留在内存中,其任何部分都不会被患处,直到作业结束运行。
# 局部性原理
高速缓存技术利用的是局部性原理,将频繁使用的数据放到更告诉的存储器中。
- 时间局部性:如果执行了程序中的某条指令,那么不久后这条指令很有可能再次执行;如果某个数据被访问过,不久之后该数据很可能再次被访问。(因为程序中存在大量的循环)
- 空间局部性:一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也很有可能被访问。(因为很多数据在内存中都是连续存放的)
# 虚拟存储器的定义和特性
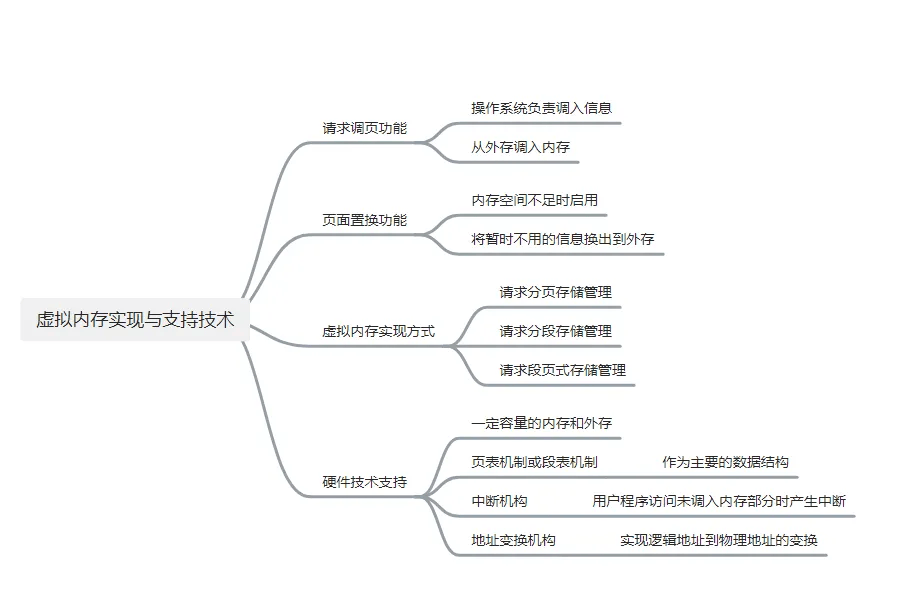
基于局部性原理,在程序装入时,可以将程序中很快会用到的部分装入内存,暂时用不到的部分留在外存,就可以让程序开始执行。在程序执行过程中,当所访问的信息不在内存时,由操作系统负责将所需信息从外存调入内存,然后继续执行程序。若内存空间不够,由操作系统负责将内存中暂时用不到的信息换出到外存。在操作系统的管理下,在用户看来似乎有一个比实际内存大得多的内存,这就是虚拟内存。
虚拟存储器的最大容量由计算机的地址结构决定,实际容量 = min{内存和外存的容量之和,CPU的寻址范围}。并不是简单的内外存容量相加。
虚拟存储器有以下三个特性:
- 多次性:无需在作业运行时一次性全部装入内存,而是允许被分成多次调入内存。
- 对换性:在作业运行时无需一直常驻内存,而是允许在作业运行过程中,将作业换入、换出
- 虚拟性:从逻辑上扩充了内存的容量,使用户看到的内存容量,远大于实际的容量。
很多知识点还得继续学习研究,先扩展部分内容,后续补充