✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
本文系统介绍了Linux常用命令及其在日志查看中的应用,重点讲解了tail、head、grep、sed、less和more命令的参数与使用场景,提升日志分析效率。同时,深入解析了内存管理中的分段与分页机制,涵盖覆盖与交换、连续分配(单一、固定、动态分区)及非连续分配的基本原理和优缺点。文章还详细阐述了软中断与硬中断的区别,解释了Linux中断处理的上下半部机制及软中断(softIRQ)的作用,强调软中断作为延迟处理机制,优化了中断响应效率。内容兼具理论深度与实用指导,适合Linux系统管理和操作系统原理学习者参考。
2025-01-18🌱上海: ☀️ 🌡️+13°C 🌬️↑10km/h
# 说下你常用的Linux命令
# 常用总结
# 扩展知识
# 如何在linux服务器上查看生产日志?
虽然现在基本生产上都日志收集管理系统,但是我们有时候查看一些特定的日志,还是使用命令比较方便
但是如何优雅的查看生产日志还是需要仔细学习一下的,比如仅使用cat命令来查看日志文件,不但无法查看实时日志,严重的情况还可能影响服务器的运行。那接下来就分别讲解一下不同的查看日志的命令。
# tail命令
这个命令也是常用的日志查看命令,可以查看实时日志的更新,当日志有更新的时候,实时打印到控制台显示。
参数说明
| 参数 | 作用 |
|---|---|
| -f | 循环读取 |
| -q | 不显示处理信息 |
| -v | 显示详细的处理信息 |
| -c <num> | 显示的字符数 |
| -n <num> | 显示num行内容 |
常用命令
tail -f online.log: 把生产日志文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要文件更新就可以看到最新的文件内容。(停止显示:ctrl+c)tail online.log: 显示 online.log 文件的最后 10 行tail -n 10 online.log: 显示文件 online.log 的最后 10 行日志tail -n +10 online.log: 显示第10行之后的所有日志内容tail -100f online.log: 实时监控100行日志内容(不停刷新,保持100条日志)tail -c 10 online.log: 显示日志文件 online.log 的最后10个字符
# head命令
用法和tail命令相似,前者是从头部开始扫描内容,后者是从尾部开始输出内容(见名知义)
常用命令
head online.log: 显示 online.log 文件的从头开始的前10 行日志内容head -n 10 online.log: 显示文件 online.log 的从首行开始的 10 行日志head -n +100 online.log: 显示第100行之前的所有日志内容head -c 10 online.log: 显示日志文件 online.log 的最开始的10个字符
# grep命令
一般使用这个命令会与正则表达式搭配使用,同时还有egrep和fgrep命令等价于grep -e(支持扩展的正则表达式)和grep -f(不支持正则表达式)。
语法格式
grep 参数 文件名常用参数
| -b | 显示匹配行距文件头部的偏移量 | -o | 显示匹配词距文件头部的偏移量 |
|---|---|---|---|
| -c | 只显示匹配的行数 | -q | 静默执行模式 |
| -E | 支持扩展正则表达式 | -r | 递归搜索模式 |
| -F | 匹配固定字符串的内容 | -s | 不显示没有匹配文本的错误信息 |
| -h | 搜索多文件时不显示文件名 | -v | 显示不包含匹配文本的所有行 |
| -i | 忽略关键词大小写 | -w | 精准匹配整词 |
| -l | 只显示符合匹配条件的文件名 | -x | 精准匹配整行 |
| -n | 显示所有匹配行及其行号 |
参考示例
搜索指定文件中包含某个关键词的内容行:
[root@linuxcool ~]# grep root /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin搜索指定文件中以某个关键词开头的内容行:
[root@linuxcool ~]# grep ^root /etc/passwd
root:x:0:0:root:/root:/bin/bash搜索多个文件中包含某个关键词的内容行:
[root@linuxcool ~]# grep linuxprobe /etc/passwd /etc/shadow
/etc/passwd:linuxprobe:x:1000:1000:linuxprobe:/home/linuxprobe:/bin/bash
/etc/shadow:linuxprobe:$6$9Av/41hCM17T2PrT$hoggWJ3J/j6IqEOSp62elhdOYPLhQ1qDho7hANcm5fQkPCQdib8KCWGdvxbRvDmqyOarKpWGxd8NAmp3j2Ln00::0:99999:7:::# sed命令
是英文词组stream editor的缩写,这个命令是利用脚本来处理文本文件,这里只说明如何用来查看具体时间段的日志内容
语法格式
sed 参数 文件名常用参数
| -e | 使用指定脚本处理输入的文本文件 | -n | 仅显示脚本处理后的结果 |
|---|---|---|---|
| -f | 使用指定脚本文件处理输入的文本文件 | -r | 支持扩展正则表达式 |
| -h | 显示帮助信息 | -V | 显示版本信息 |
| -i | 直接修改文件内容,而不输出到终端 |
参考示例
sed -n '/起始时间/,/结束时间/p' 日志文件
例如:
sed -n '/2019-12-17 12:00:00/,/2019-12-17 12:10:10/p' online.log
// 查看2019-12-17 12:00:00-12:10:10 时间段内的日志内容# less命令
可以对读取文件内容进行分页处理,可以说是linux正统查看文件内容的工具,功能很强大,它可以前后翻页并不需要读取整个文件,加载速度比more快。
语法格式
less 参数 文件名常用参数
| -b | 设置缓冲区大小 | -Q | 不使用警告音 |
|---|---|---|---|
| -e | 当文件显示结束后自动退出 | -r | 显示原始字符 |
| -f | 强制打开文件 | -s | 将连续多个空行视为一行 |
| -g | 仅标识最后搜索的关键词 | -S | 在每行显示较多的内容,而不换行 |
| -i | 忽略搜索时的大小写 | -V | 显示版本信息 |
| -K | 收到中断字符时,立即退出 | -x | 将Tab字符显示为指定个数的空格字符 |
| -m | 显示阅读进度百分比 | -y | 设置向前滚动的最大行数 |
| -N | 显示文件内容时带行号 | --help | 显示帮助信息 |
| -o | 将要输出的内容写入指定文件 |
常用命令
less -N online.log: 查看online.log文件并显示行号,支持前后翻页less -N +10g online.log: 定位到online.log文件的第10行开始显示内容- less查看文件后,
/2019-12-19 10:00:00: 自动高亮显示查找到的内容,后续n下一个,N上一个 cat -n online.log | grep 'debug' | less: 分页显示过滤到的内容(less和more一般都会搭配管道符|一起使用)
常用按键操作
| 命令操作 | 详解 |
|---|---|
| d | 向下翻页 |
| u | 向上翻页 |
| g | 跳到首行 |
| G | 跳到底部 |
| ?查找内容 | 向上查找匹配的内容并高亮显示 |
| / 查找内容 | 向下查找匹配的内容并高亮显示 |
| n | 下一个 |
| N | 上一个 |
| q | 退出less命令 |
# more命令
功能类似cat,cat命令是整个文件的内容从上到下显示在屏幕上,而more会以一页一页的显示方式方便使用者逐页阅读,当画面显示满一页会暂停,然后按空格键可以继续显示下一个画面,或者按 Q键停止显示。同时不可以向前只能向后,加载速度低于less。
语法格式
more 参数 文件名常用参数
| -c | 不滚屏,先显示内容再清除旧内容 | -s | 将多个空行压缩成一行显示 |
|---|---|---|---|
| -d | 显示提醒信息,关闭响铃功能 | -u | 禁止下划线 |
| -f | 统计实际的行数,而非自动换行的行数 | -数字 | 设置每屏显示的最大行数 |
| -l | 将“^L”当作普通字符处理,而不暂停输出信息 | +数字 | 设置从指定的行开始显示内容 |
| -p | 先清除屏幕再显示文本文件的剩余内容 | +/关键词 | 从指定关键词开始显示文件内容 |
参考示例
分页显示指定的文本文件内容:
[root@linuxcool ~]# more File.cfg
#version=RHEL8
ignoredisk --only-use=sda
autopart --type=lvm
# Partition clearing information
clearpart --none --initlabel
# Use graphical install graphical
# Use CDROM installation media
cdrom
………………省略部分输出信息………………先进行清屏操作,随后以每次10行内容的格式显示指定的文本文件内容:
[root@linuxcool ~]# more -c -10 File.cfg
#version=RHEL8
ignoredisk --only-use=sda
autopart --type=lvm
# Partition clearing information
clearpart --none --initlabel
# Use graphical install
graphical repo --name="AppStream" --baseurl=file:///run/install/repo/AppStream
# Use CDROM installation media
cdrom
--More--(20%)更多命令详细操作方式参考:
Linux命令大全(手册) – 真正好用的Linux命令在线查询网站
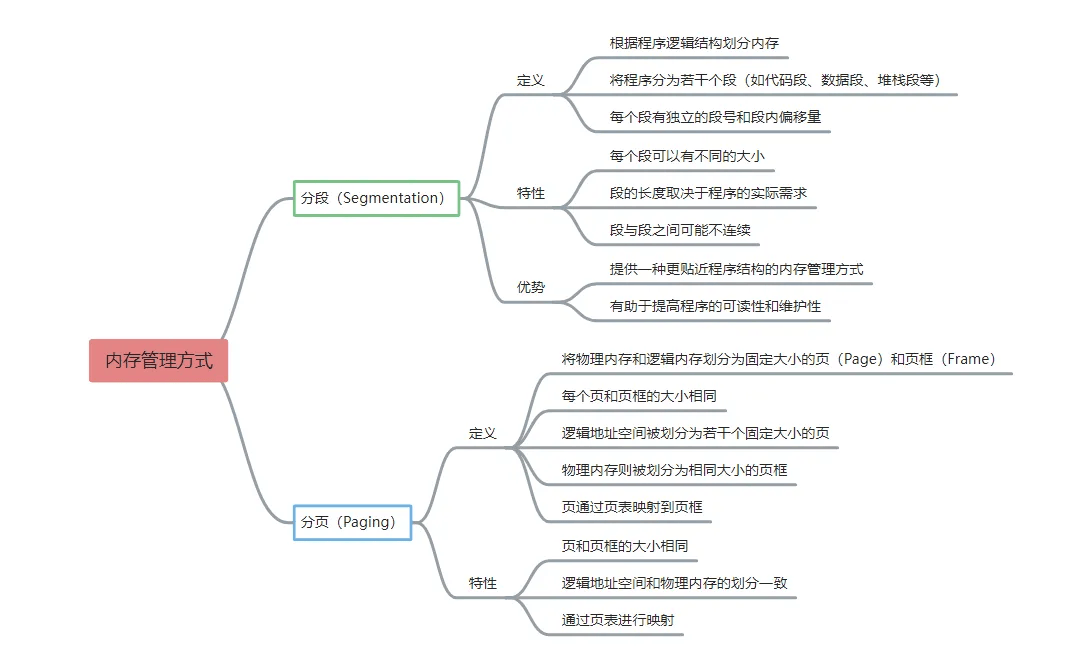
# 什么是分段、什么是分页?
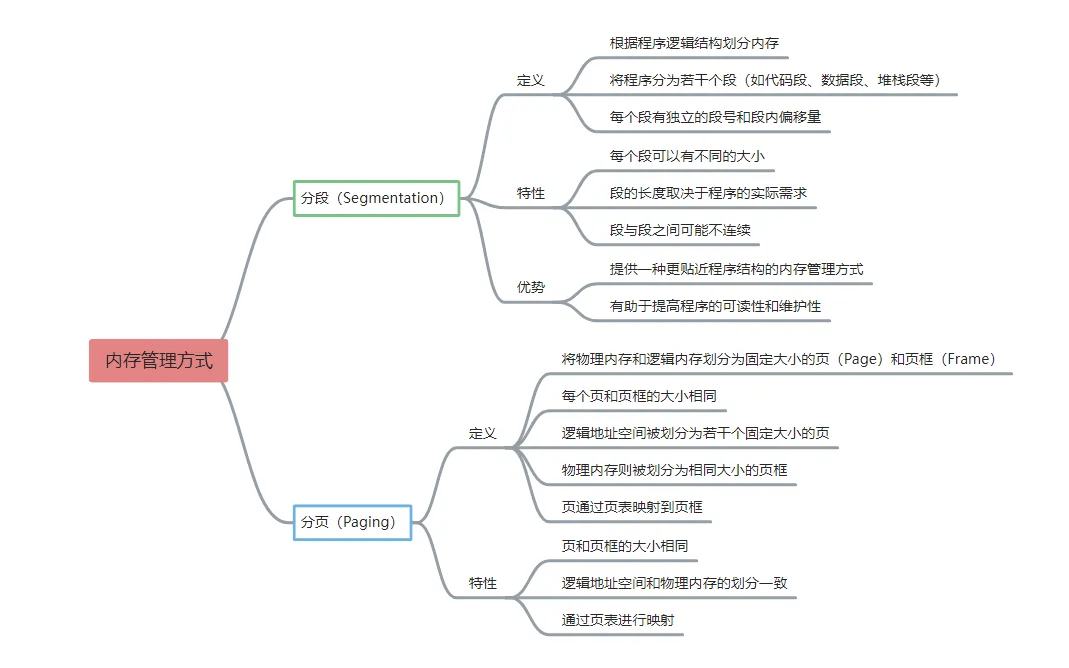
# 深入理解内存管理概念
首先分页和分段都是为了减少程序占用的主存空间来扩充内存,那两者是如何实现的呢?
我们先来了解下覆盖和交换的概念
# 覆盖和交换
覆盖是在同一程序或者进程中的,交换是在不同进程之间的
覆盖
覆盖技术的基本思想:将程序分为多个段,常用的段驻内存,不常用的段在需要时调入内存,打破了必须将一个进程的全部信息装入主存后次啊能运行的限制,解决了程序大小超过物理内存综合的问题,但是对用户不透明,增加了编程的负担。
交换
当内存空间紧张时,系统将内存中的某些进程暂时换出外存,把外村中已经具备运行条件的进程换入内存。交换的时机选择策略一般为:进程不用或者很少再用的就换出,内存空间不够或者面临不够的风险时,启动交换程序换出。
# 连续分配管理模式
连续分配方式是指为一用户程序分配一个连续的内存空间,主要包括单一连续分配、固定分区分配、动态分区分配,这里还需要了解两个概念:
- 内部碎片:分配给某进程的内存区域中,有些部分没有用上
- 外部碎片:是指内存中某些空闲的分区由于太小而难以利用。
# 单一连续分配
在单一连续分配方式中,内存被分为系统区和用户区,系统区通常位于内存的低地址部分,用于存放操作系统相关数据,用户区用于存放用户进程相关数据。这种模式下无外部碎片,有内部碎片。

优点就是实现简单没有外部碎片,可以采用覆盖技术扩充内存,不一定需要采取内存保护,缺点就是只能用于单用户、单任务的操作系统中,有内部碎片,存储器利用率极低。
# 固定分区分配
固定分区分配是最简单的一种多道程序存储管理方式,它将用户内存空间划分你为若干固定大小的分区,每个分区只装入一道作业,当有空闲分区时,便可以再从外从的后备队列中选择适当大小的作业装入该分区。
同时固定分区分配还分为分区大小相等和不相等两种方式
# 动态分区分配
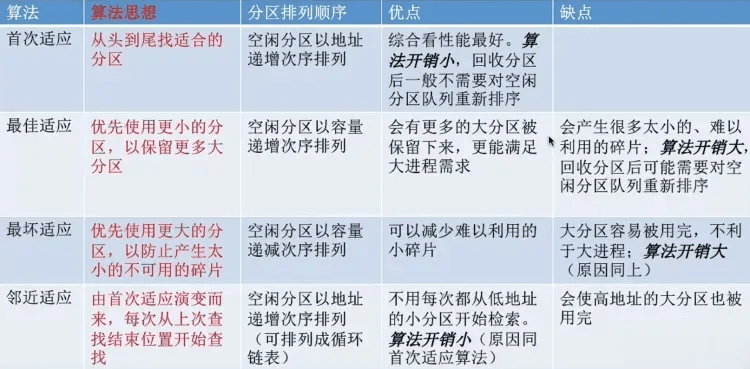
动态分区分配不预先分配内存,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需求,系统中分区的大小和数目是可变的。
动态分区分配会产生外部碎片,克服外部碎片可以采用紧凑技术来解决,即操作系统不时地对进程进行移动和调整,但这需要重定位寄存器的支持,并且需要消耗一定时间。
关于回收内存分区时可能会遇到四种情况
- 回收区之后有相邻的空闲分区
- 回收区之前有相邻的空闲分区
- 回收区前、后都有相邻的空闲分区
- 回收区前、后都没有相邻的空闲分区
同时动态分区分配的策略有以下几种算法
接下来就是讲解分页和分段的具体实现,同时也是非连续分配管理方式
# 非连续分配管理方式
非连续分配允许程序分散装入不相邻内存分区,因需额外存储索引,存储密度低于连续存储。其根据分区大小是否固定分为分页和分段存储管理方式,分页存储管理又分基本分页和请求分页存储管理方式。
呃这段我感觉官方题解将的更为详细清晰,总体而言就是为了减少程序使用的主存空间来扩充内存。后续补充。。。
# 什么是软中断、什么是硬中断?
# 总结分析
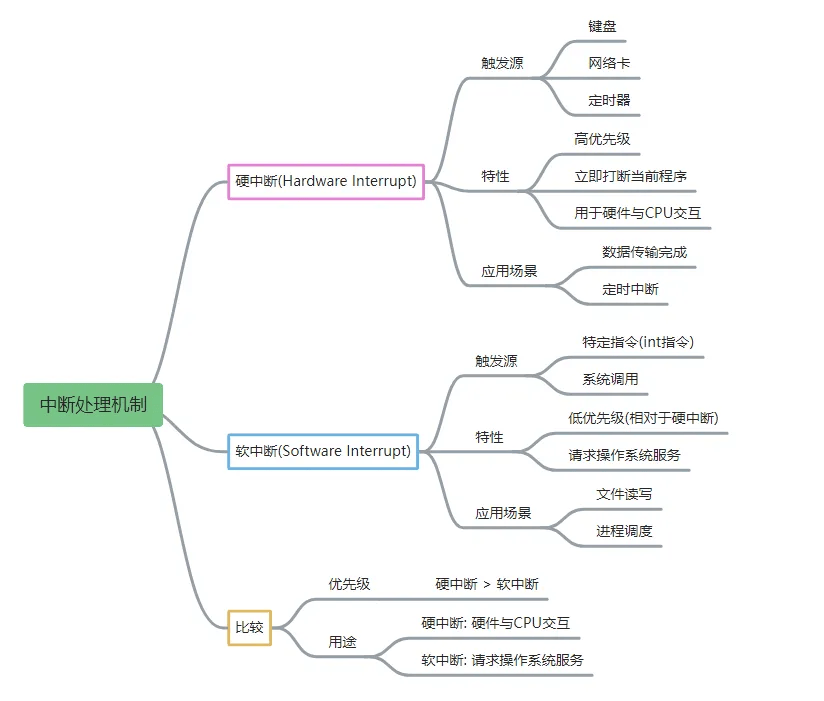
# 注意
上面讲的软中断正确来讲是软件中断(官方题解中也有说明),网上通常讲的软中断是对于中断处理的一种优化,也就是softirq,下面会着重讲下该定义。先区分下软中断和软件中断。
- 1)软中断(softIRQ),即中断下半部机制。ISR运行时间不易过长,linux将中断中的一部分逻辑推后执行,这就是softIRQ,它完全由软件实现;
- 2)软件中断(Software Interrupt),从软件中断指令而来。在32位x86中,为了实现linux用户态到内核态的切换,linux使用软中断指令“int 0x80”来触发异常,切换CPU特权级,实现系统调用。
# 什么是中断
在计算机中,中断时系统用来响应硬件设备请求的一种机制。操作系统收到硬件的中断请求,会打断正在执行的进程,然后调用内核中的中断处理程序来响应请求。
举一个简单的例子,就是点外卖,当我们外卖点完后,就去做其他的事情,等到外卖员打电话说外卖到了,我们就需要停下手中正在做的工作,去取外卖。这里的电话通知就对应到计算机里的中断,当接到电话就是发生中断,然后停下当前的事情去取外卖也就是进行另一个事情。
所以可看出中断是一种异步的事件处理机制,可以提高系统的并发处理能力。
因为操作系统收到了中断情爱u,会打断其他进程的运行没所以中断处理程序要尽可能快的执行完,减少对正常进程运行调度的影响。
同时中断处理程序在响应中断时,可能还会遇到临时关闭中断,因为当前中断处理程序没有执行完之前,系统中的其他中断请求都无法被响应,也就是说中断有可能丢失,所以中断处理程序要短且快。
举个例子,就是同时点了两份外卖,然后由不同的配送员进行配送,第一份外卖送到时,配送员和我电话沟通了太长时间导致第二个配送员因为通话中(相当于关闭了中断响应),自然就无法打通电话,可能后续尝试了几次就放弃了(相当于丢失了一次中断)。
# 什么是软中断(softIRQ)?
前面提到了中断请求的处理程序应该要短且快,以减少对正常进程运行调度的影响,而且中断处理程序可能会暂时关闭中断,这时如果中断处理程序执行实践过程,可能在还未执行完中断处理程序前,会丢失当前其他设备的中断请求。
Linux 系统为解决中断处理程序执行过长和中断丢失问题,将中断过程分为两个阶段:上半部和下半部。
- 上半部:用于快速处理中断,通常会暂时关闭中断请求,主要处理与硬件紧密相关或时间敏感的事务。
- 下半部:用于延迟处理上半部未完成的工作,一般以内核线程的方式运行。
比如网卡通过 DMA 将接收数据写入内存后,以硬件中断通知内核,内核处理该事件分上半部和下半部:
- 上半部:禁止网卡中断,避免频繁硬中断影响内核效率,随后触发软中断,负责处理耗时短的工作,直接处理硬件请求(硬中断),快速执行。
- 下半部:即软中断处理程序,由内核触发,从内存找网络数据,按网络协议栈解析处理后送应用程序,负责上半部未完成的耗时较长工作,延迟执行。
所以中断处理程序的上半部和下半部可以理解为:
- 上半部直接处理硬件请求,也就是硬中断,主要负责耗时短的工作,特点是执行快
- 下半部是由内核触发,也就是说软中断,主要负责上半部未完成的工作,通常都是耗时比较长的事情,特点是延迟执行。
还有一个区别,就是硬中断会打断CPU正在执行的任务,然后立即执行中断处理程序,而软中断是以内核线程的方式执行,并且每一个CPU都对应一个软中断内核线程,名字通常为ksoftirqd/CPU编号,比如0号CPU对应的软中短内核线程名字是ksoftirqd/0.
不过软中断不只是包括硬件设备中断处理程序的下半部,一些内核自定义事件也属于软中断,比如内核调度等、RCU锁(内核里常用的一种锁)等。
- 硬中断:由硬件设备(如网卡、硬盘等)发起的中断请求。当硬件设备完成特定操作或需要 CPU 关注时,会通过硬件信号向 CPU 发送中断请求。例如,网卡收到网络包后,会通过硬件中断通知内核。CPU 在接收到硬中断信号后,会暂停当前正在执行的任务,转而执行相应的中断处理程序。硬中断是真正意义上由硬件引发的中断,它会打断 CPU 的正常执行流程,具有较高的优先级。
- 软中断:从本质上讲,软中断并非像硬中断那样由硬件直接触发的真正中断,而是软件层面通过程序模拟中断的行为。软中断通常用于处理那些可以延迟处理且相对耗时的任务,这些任务往往与硬件设备相关,但不需要立即响应。例如,在网卡接收数据的过程中,硬中断处理程序(上半部)先快速处理一些关键操作,然后触发软中断,将剩余较耗时的处理工作(如下半部)交给软中断处理程序去执行。
具体了解参考:
https://zhuanlan.zhihu.com/p/360683396