✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
本文系统阐述了MySQL索引数量并非越多越好,过多索引会占用存储空间、降低写入性能并增加查询优化器负担。针对索引过多问题,提出删除无用索引、合并索引、使用前缀和复合索引、优化查询语句及定期维护索引等优化策略。同时,详细介绍了MySQL EXPLAIN语句的各项指标及其性能含义,帮助开发者理解查询执行计划。文章还总结了SQL调优要点,包括合理设计索引、避免索引失效、优化多表JOIN及调整数据库参数,提升整体数据库性能。通过示例和代码演示,具备较强的实用指导价值。
2025-01-15🌱上海: ☀️ 🌡️+4°C 🌬️↓19km/h
# MySQL中的索引数量是否越多越好?为什么?
# 简要回答
索引数量并不是越多越好,虽然索引在提升查询性能方面起着重要作用,但是过多的索引会带来一些负面影响。
- 占用额外的存储空间
每个索引都会占用一定的磁盘空间,当索引数量过多的时候,会导致数据库文件体积增大,不仅浪费磁盘空间,还可能影响数据库的备份和恢复速度,每个索引都是一个B+树,B+树的每个节点通常是一个页,每页默认16KB
- 降低写入性能
每次对表进行插入、更新、删除操作时,数据库不仅要更新表中的数据,同时还要更新相关的索引,所以索引数量越多,更新索引的开销就越大,会导致写入操作的性能下降。
- 查询优化器复杂度增加
过多的索引会使查询优化器在选择执行计划时面临更多的选择,增加了优化器的工作负担,同时还可能导致优化器选择了不合适的执行计划,从而影响了性能。
# 扩展回答
-
Q:当索引数量过多时,该如何优化数据库性能?
-
A:
-
分析并删除不必要的索引
-
使用EXPLAIN语句查看当前执行计划,通过关键字分析索引的使用情况,进行索引的优化。
-
**查询索引使用情况,**通过查询
information_schema库中的TABLE_STATISTICS表来获取索引的使用情况统计信息。例如:SELECT * FROM information_schema.TABLE_STATISTICS WHERE table_schema = 'your_database' AND table_name = 'your_table';上面的语句会返回关于表的统计信息,包括索引的使用次数等,如果某个索引长时间未被使用,可以考虑删除该索引。
-
-
合并索引
-
前缀索引:对于较长的字符串字段,可以考虑使用前缀索引。
-
复合索引:如果多个单列索引经常一起使用,可以考虑将它们合并为一个复合索引,同时注意复合索引的顺序,应该将最常用的字段放在前面。
-
优化查询语句
-
避免索引失效(具体导致索引失效的情况不再复述已经记录很多次了)
-
避免使用select,尽量明确指定需要查询的字段,减少数据库返回的数据量,提升查询性能
-
减少子查询和连接操作,过的子查询和连接操作会增加查询的复杂度和执行时间,可以使用JOIN替代子查询或者优化连接条件。例如:
-- 子查询示例
SELECT column1 FROM your_table WHERE id IN (SELECT id FROM another_table WHERE some_condition);
-- 优化为JOIN
SELECT your_table.column1
FROM your_table
JOIN another_table ON your_table.id = another_table.id
WHERE another_table.some_condition;-
定期维护索引
- 重建索引:随着数据的插入,更新和删除,索引又可能会变得碎片化,影响性能,可以定期重建素银来整理碎片,提高索引的效率。在MySQL中,可以使用以下语句进行重建索引。
ALTER TABLE your_table REBUILD INDEX index_name; - 更新统计信息:数据库的查询优化器依赖统计信息来生成执行计划。定期更新统计信息可以确保优化器做出更准确的决策。语句为:
ANALYZE TABLE your_table;
- 重建索引:随着数据的插入,更新和删除,索引又可能会变得碎片化,影响性能,可以定期重建素银来整理碎片,提高索引的效率。在MySQL中,可以使用以下语句进行重建索引。
-
调整数据库配置参数
- 调整缓存参数:适当增加
innodb_buffer_pool_size等缓存参数的值,可以提高数据库的缓存命中率,减少磁盘 I/O 操作。例如,在 MySQL 配置文件(通常是my.cnf或my.ini)中:innodb_buffer_pool_size=2G - 优化线程参数:根据服务器的硬件资源和业务负载,合理调整
thread_cache_size等线程参数,以减少线程创建和销毁的开销。
- 调整缓存参数:适当增加
上面的内容只是讲了大概的思路,具体的操作建议自行搜索学习
# 如何使用MySQL的EXPLAIN语句进行查询分析?
# 简要回答
explain主要用来SQL分析,主要的属性详解如下
- id:执行计划中每个操作的唯一标识符。值越大优先级越高,简单查询的id通常为1,复杂查询(比如包含子查询或者UNION)的id会有多个。对于一条查询语句,每个操作都有一个唯一的id,但是在多表join查询的时候,一次explain中的多条记录的id是相同的。
- select_tyep(重要):操作的类型。如SIMPLE(简单查询)、PRIMARY(主要查询)、SUBQUERY(子查询)等
- table:查询的数据表
- partions:当前操作所设计的分区
- type(重要):访问类型,表示查询时所使用的索引类型,包括all、index、range、ref、eq_ref、const、system等。速度由慢到快。
- possible_keys:表示可能被查询优化器选择使用的索引
- key(重要):表示查询优化器选择使用的索引
- key_len: 表示索引的长度。索引的长度越短,查询时的效率越高
- ref:用来表示哪些列或者常量被用来与key列中命名的索引进行比较
- rows(重要):表示此操作需要扫描的行数,即扫描表中多少行才能得到结果。
- filtered:表示此操作过滤中保留的行数占扫描行数的百分比,值越小,说明该步骤筛选掉的数据越多
- Extra(重要):表示其他额外的信息。
# 扩展知识
为了更好的测试不同的数据信息,建了一个表
-- 创建一个名为example1的表
CREATE TABLE example1 (
id INT NOT NULL,
field1 VARCHAR(100) NOT NULL,
field2 VARCHAR(100) NOT NULL,
field3 VARCHAR(100) NOT NULL,
-- 定义主键
PRIMARY KEY (id),
-- 唯一索引
UNIQUE INDEX idx_unique_field1 (field1),
-- 定义包含三个字段的复合索引
INDEX idx_field1_field2_field3 (field1, field2, field3),
-- 非唯一索引
INDEX id_field2(field2)
);
-- 创建一个名为example2的表
CREATE TABLE example2(
id INT NOT NULL,
field1 VARCHAR(100) NOT NULL,
field2 VARCHAR(100) NOT NULL,
field3 VARCHAR(100) NOT NULL,
-- 定义主键
PRIMARY KEY (id),
-- 唯一索引
UNIQUE INDEX idx_unique_field1 (field1),
-- 定义包含三个字段的复合索引
INDEX idx_field1_field2_field3 (field1, field2, field3),
-- 非唯一索引
INDEX id_field2(field2)
);并制造了500条测试数据
package com.muzi.easychat;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Random;
public class InsertTestData {
private static final String URL = "";
private static final String USER = "";
private static final String PASSWORD = "";
// 生成随机字符串
private static String generateRandomString(int length) {
StringBuilder sb = new StringBuilder();
Random random = new Random();
String characters = "abcdefghijklmnopqrstuvwxyz";
for (int i = 0; i < length; i++) {
int index = random.nextInt(characters.length());
sb.append(characters.charAt(index));
}
return sb.toString();
}
public static void main(String[] args) {
try (Connection connection = DriverManager.getConnection(URL, USER, PASSWORD)) {
String sql = "INSERT INTO example2 (id, field1, field2, field3) VALUES (?,?,?,?)";
try (PreparedStatement statement = connection.prepareStatement(sql)) {
for (int i = 1; i <= 500; i++) {
statement.setInt(1, i);
statement.setString(2, "Muzi"+i);
statement.setString(3, generateRandomString(10));
statement.setString(4, "Muzi"+i/50);
statement.executeUpdate();
}
}
System.out.println("500条数据插入成功!");
} catch (SQLException e) {
e.printStackTrace();
}
}
}# type中不同的值的详细信息
system: 系统表,少量数据,往往不需要进行磁盘IOconst:使用常数索引,MySQL只会在查询时使用常数值进行匹配(使用唯一性索引做唯一查询)
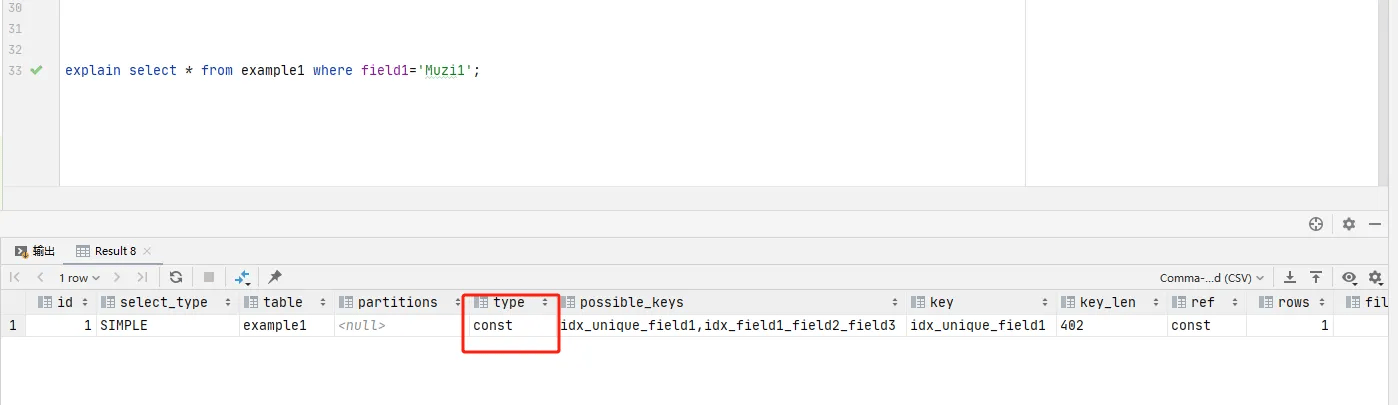
eq_ref:唯一索引扫描,只会扫描索引树中的一个匹配行
eq_ref类型的查询通常表示使用了唯一索引或主键进行连接,并且在连接条件中,对于每个来自驱动表的行,最多只从被驱动表中找到一行匹配的记录。以下是一个示例,展示如何在example1和example2这两个表之间生成一个eq_ref类型的查询语句:
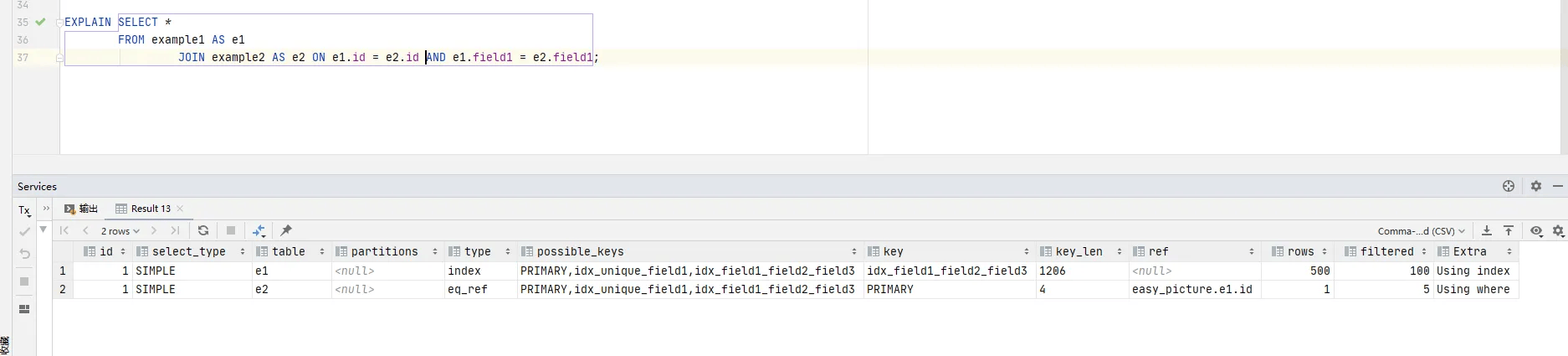
ref:非唯一索引扫描,只会扫描索引树中的一部分来查找匹配的行
使用非唯一索引进行查询

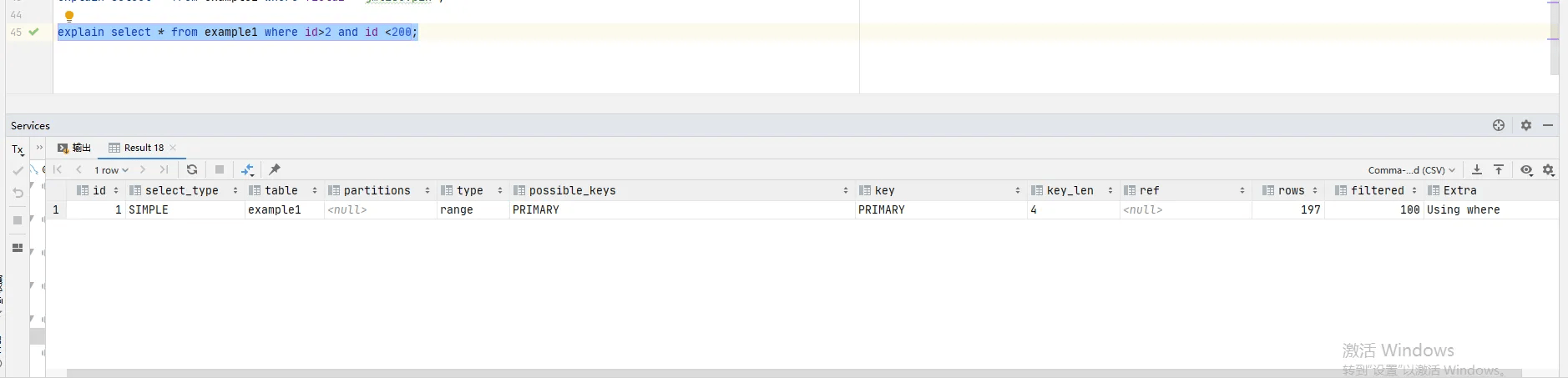
range:范围扫描,只会扫描索引树中的一个范围来查找匹配的行
使用索引进行范围查询
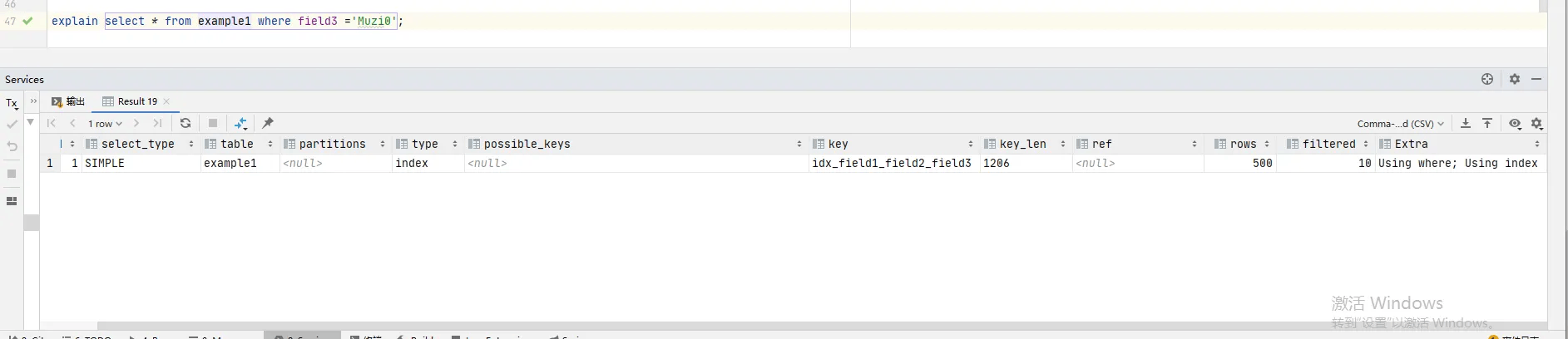
index:全索引扫描,会遍历索引树来查找匹配的行
不符合最左前缀匹配的查询
all:全表扫描,将遍历全表来找到匹配的行
使用非索引字段查询
总结:以上速度由快到慢
system> const > eq_ref >ref>range> index >ALL
# possible_keys 和key
possible_keys 表示查询语句中可以使用的索引,而不一定实际使用了这些索引。这个字段列出了可能用于这个查询的所有索引,包括联合索引的组合。而 key 字段表示实际用于查询的索引。如果在查询中使用了索引,则该字段将显示使用的索引名称;
# extra
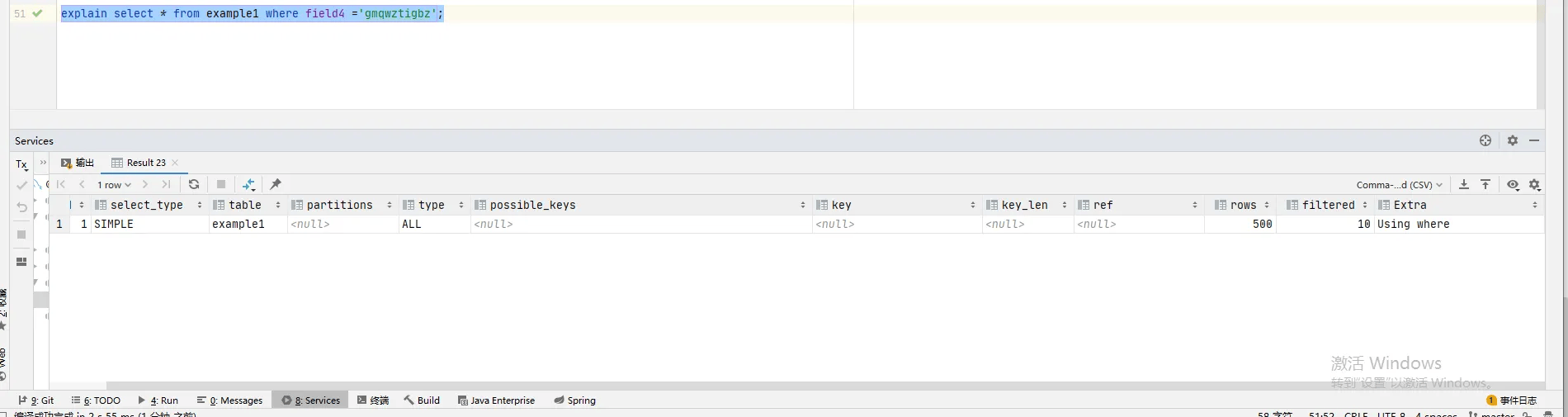
Using where::表示 MySQL 将在存储引擎检索行后,再进行条件过滤(使用 WHERE 子句);查询的列未被索引覆盖,where筛选条件非索引的前导列或者where筛选条件非索引列。
非索引字段查询
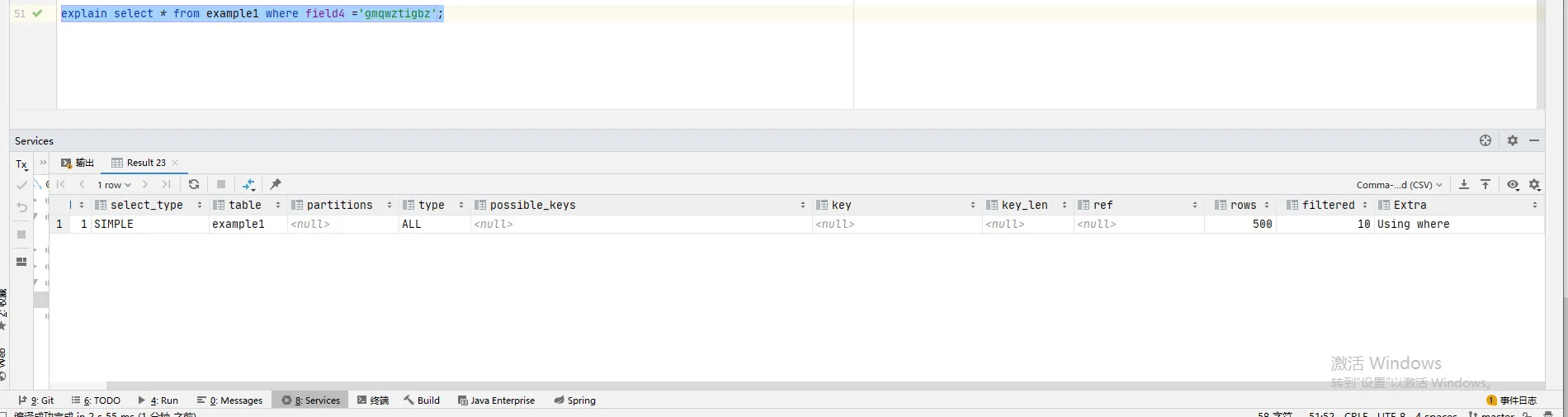
未索引覆盖,用联合索引的非前导列查询
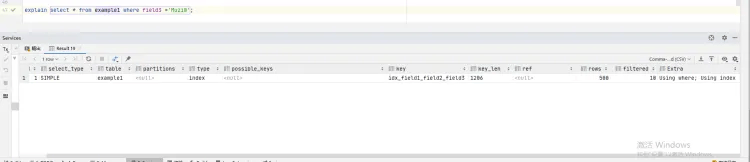
Using index:表示MySQL使用了覆盖索引优化,只需要扫描索引,而无需回到数据表中检索行。
正常来说应该是Using index,由于field1是唯一索引且等值匹配,并且数据量太小,优化器认为用不到覆盖索引技术进行优化。
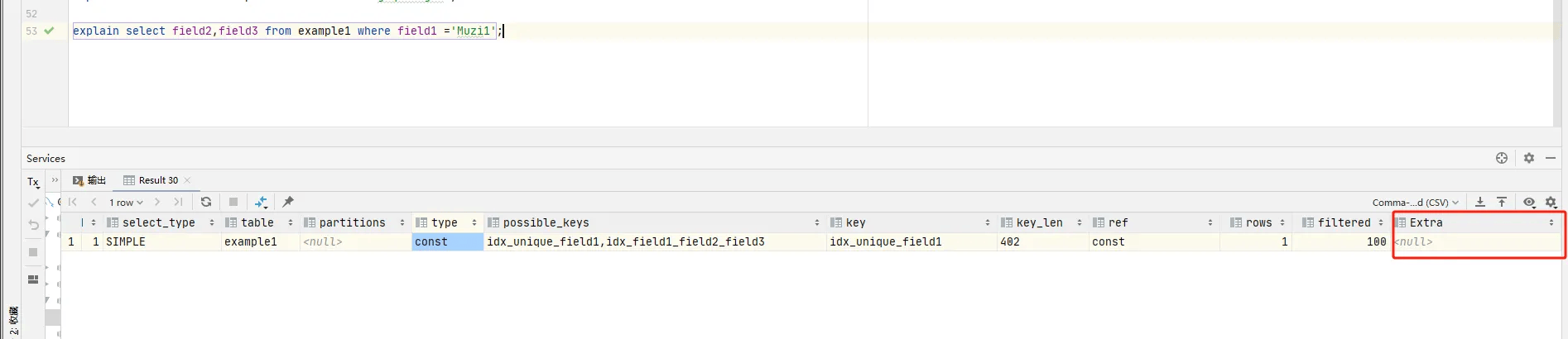
Using index condition:表示查询在索引上执行了部分条件过滤,这通常和索引下推有关
使用到索引下推
我发使用复合索引时,如果前导列同时是唯一索引,就不会使用索引下推技术,优化器会自动选择最优解。
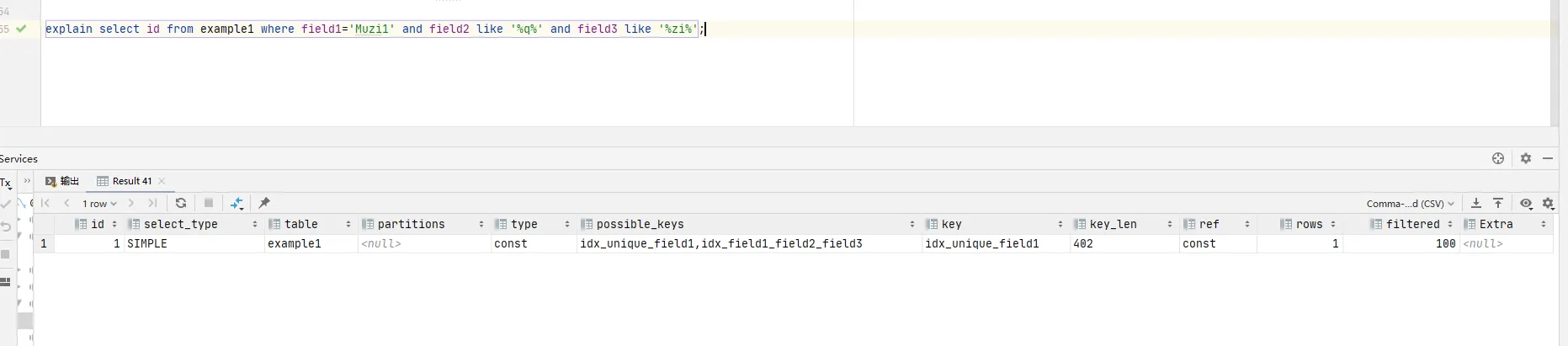
以下的部分类型都是在数据量大的情况下才会出现,这里由于测试数据太少,没办法做测试,后续添加更多数据再进行测试演示。
-
Using where; Using index:查询的列被索引覆盖,并且where筛选条件是索引列之一,但不是索引的前导列,或者where筛选条件是索引列前导列的一个范围 -
索引覆盖,但是不符合最左前缀
-
索引覆盖,但是前导列是个范围
-
Using join buffer:表示 MySQL 使用了连接缓存;
explain select * from example1 join example2 on example1.id = example2.id where example1.field1 = 'Muzi1'; -
Using temporary:表示 MySQL 创建了临时表来存储查询结果。这通常是在排序或分组时发生的; -
Using filesort:表示 MySQL 将使用文件排序而不是索引排序,这通常发生在无法使用索引来进行排序时; -
Using index for group-by:表示 MySQL 在分组操作中使用了索引。这通常是在分组操作涉及到索引中的所有列时发生的; -
Using filesort for group-by:表示 MySQL 在分组操作中使用了文件排序。这通常发生在无法使用索引进行分组操作时; -
Range checked for each record:表示 MySQL 在使用索引范围查找时,需要检查每一条记录; -
Using index for order by:表示 MySQL 在排序操作中使用了索引,这通常发生在排序涉及到索引中的所有列时; -
Using filesort for order by:表示 MySQL 在排序操作中使用了文件排序,这通常发生在无法使用索引进行排序时; -
Using index for group-by; Using index for order by:表示 MySQL 在分组和排序操作中都使用了索引。
# MySQL中如何进行SQL调优?
# 简要回答
- 避免select *,只查询必要的字段
- 合理设计索引,通过联合索引进行覆盖索引及索引下推技术的优化,减少回表的次数,提升效率
- 避免SQL中进行函数计算等操作,导致无法命中索引
- 避免使用like,导致全表扫描(如果符合最左前缀匹配原则可以走索引)
- 注意使用联合索引需满足最左匹配原则
- 不要对无索引字段进行排序操作
- 连表查询需注意不同字段的字符集保持一致,
- 注意隐式类型转换操作,会导致索引失效
- 使用OR ,两边需保持等值匹配且都为索引列,才会走索引
# 补充回答
以上都是对SQL进行优化,避免索引失效等进行SQL调优,还可以从其他方面进行考虑,比如先分析SQL慢的原因
- 索引失效
- 多表join
- 查询字段太多
- 表中数据量太大
- 索引区分度不高
- 数据库连接数不够
- 数据库的表结构不合理
- 数据库IO或者CPU比较高
- 数据库参数不合理
- 长事务导致的
- 锁竞争导致的长时间的等待
一次完整的SQL调优,一般要考虑以上几个因素,一般会涉及其中一个或者多个问题。
# 扩展回答
Q: 为什么多表join会导致SQL慢?
A : MySQL是使用了嵌套循环(Nested-Loop Join)的方式来实现关联查询的,简单点说就是要通过两层循环,用第一张表做外循环,第二张表做内循环,外循环的每一条记录跟内循环中的记录作比较,符合条件的就输出。
而具体到算法实现上主要有simple nested loop,block nested loop和index nested loop这三种。而且这三种的效率都没有特别高。
MySQL是使用了嵌套循环(Nested-Loop Join)的方式来实现关联查询的,如果有2张表join的话,复杂度最高是O(n2),3张表则是O(n3)...随着表越多,表中的数据量越多,JOIN的效率会呈指数级下降。
Q: 不使用join,如何做关联查询?
A: 主要有以下做法:
1、在内存中自己做关联,即先从数据库中把数据查出来之后,我们在代码中再进行二次查询,然后再进行关联。
2、数据冗余,那就是把一些重要的数据在表中做冗余,这样就可以避免关联查询了。
3、宽表,就是基于一定的join关系,把数据库中多张表的数据打平做一张大宽表,可以同步到ES或者干脆直接在数据库中直接查都可以
Q:你上面说数据量太大也会导致SQL慢,那怎么解决?
A:具体的解决方案有以下几种:
1、数据归档,把历史数据移出去,比如只保留最近半年的数据,半年前的数据做归档。
2、分库分表、分区。把数据拆分开,分散到多个地方去,这里不详细介绍了,我们的文档中有分库分表和分区的详细介绍,不展开了。
3、使用第三方的数据库,比如把数据同步到支持大数量查询的分布式数据库中,如oceanbase、tidb,或者搜索引擎中,如ES等。
Q:数据库参数不合理需要怎么调整?
**A:**首先通过SHOW VARIABLES LIKE 'innodb%';查看当前的innoDB参数配置,这些参数包括缓冲池大小、刷新间隔、日志大小等。
- 调整缓冲池大小(设置为系统可用内存的70%-80%,假设有8g内存可用)
SET GLOBAL innodb_buffer_pool_size=6G;
- 调整存储引擎使用的I/O线程数量(通常这两个参数设置为CPU核心数的一半)
SET GLOBAL innodb_read_io_threads=4;
SET GLOBAL innodb_write_io_threads=4;- 调整事务日志文件的大小(默认为5M,但远远不够,可以设置为业务高峰2小时写入的日志量,也可以直接设置为1G或者系统内存的1/4)
SET GLOBAL innodb_log_file_size=1G;