✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
本文详细解析了MySQL中B+树查询数据的全过程,阐述了索引查找的步骤和原理,提升对数据库索引机制的理解。同时,比较了count(*)、count(1)与count(字段名)三者在功能和性能上的差异,指出count(*)和count(1)效率相近,count(字段名)需过滤null值,性能略低但视字段属性而定。文章还介绍了MyISAM与InnoDB存储引擎中count函数的实现差异及优化策略。最后,系统总结了char与varchar两种字符串类型的存储方式、空间占用、性能影响及适用场景,为数据库设计提供实用参考。
2025-01-15🌱上海: ☀️ 🌡️+4°C 🌬️↓19km/h
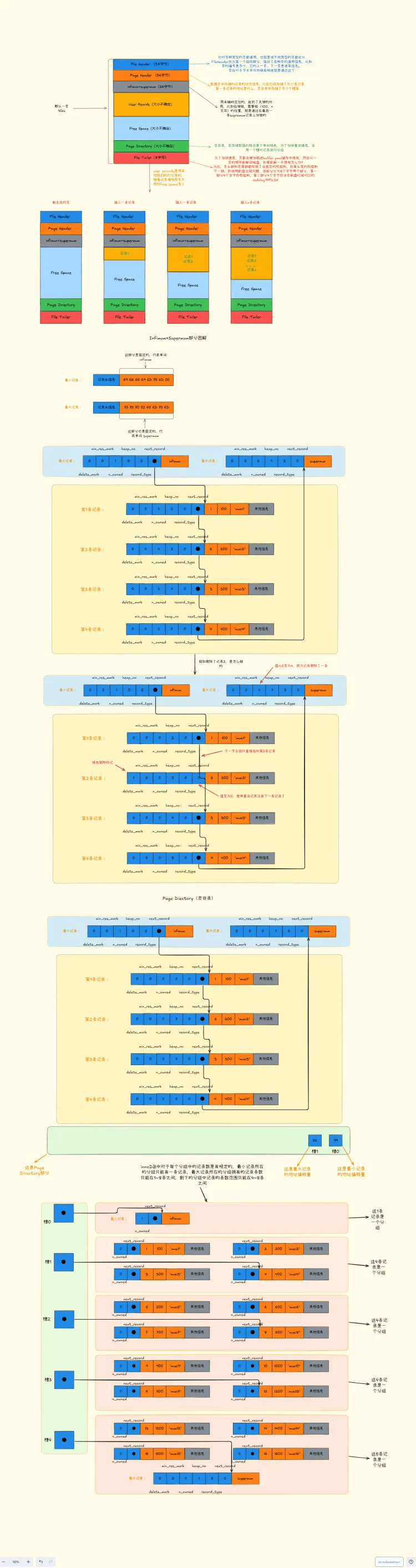
# 请详细描述MySQL的B+树中查询数据的全过程
# MySQL中count(*)、count(1)和count(字段名)有什么区别?
# 简要回答
都是用来统计行数的聚合函数,但是还有一些区别:
-
功能上:
-
1. count(*)会统计表中所有行的数量,包括null值(不会忽略任何一行的数据)。由于只是计算行数,不需要对具体的列进行计算,所以性能一般较高
-
2. count(1)和count(*)几乎没有差别,也会统计表中包括null值的所有行的数量
-
3. count(字段名)只统计指定字段不为null的行数。
-
效率上:
-
1. count(1)和count(*)效率一致(官网上声明了)
-
2. count(字段)查询就是全表扫描,正常情况下还需要判断字段是否是null值,所以理论上会比其他两个慢。但是如果字段不为null,比如是主键,那么理论上也差不多。效率上不需要纠结,主要看使用场景是否需要统计null值
# 扩展知识
MyISAM中,由于只有表锁,因此把每张表的总数单独记录维护(表锁使得对表的修改是串行,因此能维护总数,毕竟查询的时候不会有别人修改记录数据导致查询的总数不一致)所以count(*)非常快,等于直接返回了一个字段,前提是不需要条件过滤而是直接返回整表数据。
InnoDB中由于支持行锁,所以会有很多并发修改表的数据,因此无法维护记录的总数,但相应的innoDB也对count(*)和count(1)也做了一定的优化。
count需要扫描全表。如果扫的是主键索引,因为主键索引的叶子节点上保存的是完整的记录,占据的空间和内存都比较大,此时选择二级索引扫描成本会耕地。
在没有对应的条件过滤等功能时innoDB会评估这个成本选择合适的索引扫描。
# MySQL中varchar和char有什么区别?
# 简要回答
| 特点 | char | varchar |
|---|---|---|
| 存储方式 | 定长字符串(字符串长度小于定义的长度,会使用空格进行填充) | 变长字符串(不会额外填充空格) |
| 存储空间 | 始终占用固定长度空间 | 只占用实际需要的存储空间 |
| 性能影响 | 始终占用固定长度的存储空间,因此在存储时可能会浪费一些空间 <br>(不需要记录额外长度信息,在某些情况下可能更快) | 只占用实际需要的存储空间,因此可以节省存储空间 <br>(需要记录额外长度信息,占据1~2个字节),在某些情况下可能稍微影响性能) |
| 适用场景 | 适合存储固定且短的字符串 | 适合存储变化或较长的字符串 |