✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
本文系统阐述了MySQL事务的实现机制,重点介绍了锁机制、Redo Log、Undo Log及MVCC的作用。通过Undo Log实现事务的原子性和回滚,Redo Log保障事务持久性,锁机制和MVCC实现事务隔离性,提升并发性能。详细解析了Binlog、Redo Log与Undo Log三种日志的定义、用途、记录内容及持久化策略,明确其在备份、恢复和事务管理中的不同职责。文章还深入剖析了MVCC的工作原理,包括快照读与当前读、行记录隐式字段及Read View的可见性判断,揭示了MVCC如何通过多版本数据快照实现无锁并发控制,增强数据库的并发处理能力。整体内容技术详实,具有较强的实用价值。
2025-01-15🌱上海: ☀️ 🌡️+4°C 🌬️↓19km/h
# MySQL是如何实现事务的?
# 简要回答
主要是通过锁、Redo log、Undo Log 、MVCC来实现事务
通过事务的特性来分析
-
原子性: undo log(回滚日志),它会记录事务的反向操作,也就是保存数据的历史版本,用于事务的回滚,可以在事务执行失败之后恢复之前的数据,实现原子性和隔离性
-
一致性:通过原子性、隔离性、持久性来达到一致性的目的
-
隔离性:
-
Mysql利用锁机制,通过对数据并发修改的控制,满足事务的隔离性。
-
MVCC(多版本并发控制),满足了非锁定读的需求,提高了并发度,实现了读已提交和可重复读两种隔离级别,实现了事务的隔离性
-
持久性: redo log通过记录事务对数据库的所有修改,在崩溃时恢复未提交的更改,用来满足事务的持久性
# 补充回答
# binlog、redo log 和 undo log的作用及区别?
三者都是日志类型文件,但是各自的作用和实现方法有所不同
- binlog主要用来对数据库进行数据备份、崩溃恢复和数据复制等操作,redo log、和undo log主要用于事务管理,记录的都是数据修改操作和回滚操作。redolog用来做恢复,undolog用来做回滚。
- binlog是MySQL用于记录数据库中的所有DDL、DML语句的一种二进制日志,它记录了所有对数据库结构和数据的修改操作。binlog主要用来对数据库进行数据备份、灾难恢复和数据复制等操作。binlog的格式分为基于语句的格式和基于行的格式。
- redolog是MySQL用于实现崩溃恢复和数据持久性的一种机制
- undolog则用于事务回滚或者系统崩溃时撤销(回滚)事务所做的修改,同时Undo log还支持MVCC(多版本并发控制)机制,用于在并发事务执行时提供一定的隔离性。
| 对比维度 | Binlog | Redolog | Undolog |
|---|---|---|---|
| 定义与用途 | 记录数据库变更信息,用于数据库恢复和复制,如主从复制场景及数据误操作后的恢复 | 保证事务的持久性,事务提交时,若数据未持久化到磁盘,系统崩溃后可通过其恢复数据 | 用于记录事务执行过程中数据修改前的值,支持事务回滚操作、MVCC |
| 记录内容 | 数据库层面操作,如基于语句模式下的 SQL 语句或基于行模式下的行数据变化情况 | 物理层面数据修改,对数据页的修改信息,包括修改字节偏移量、修改后的数据内容等 | 数据修改前的旧值,以便回滚时恢复数据 |
| 写入时机与持久化策略 | 事务提交后写入,可配置不同持久化策略,如每次提交后立即同步磁盘或累积一定数量事务后同步 | 事务执行过程中不断写入,事务提交前必须先持久化到磁盘(先写入 redo log buffer,再刷到磁盘 redo log 文件) | 事务执行过程中写入,事务开始分配空间记录旧值,事务提交后可清理,回滚时使用记录恢复数据 |
| 文件格式与存储位置 | 二进制文件,由 MySQL 定义格式,默认存于数据库数据目录下,文件名如 “binlog.xxxxxx” | 由 InnoDB 存储引擎管理,多个 redo log 文件循环使用,存于 InnoDB 数据目录下,文件大小和数量可配置 | 存储在 InnoDB 共享表空间或独立 undo 表空间(依配置而定),与数据页管理紧密结合 |
| 支持引擎 | innodb、myiasm、... | innodb | innodb |
# MySQL中的MVCC是什么?
# 简要回答
MVCC,多版本并发控制。和数据库锁一样,也是一种并发控制的解决方案。允许多个事务同时读取和写入数据库,而无需互相等待,从而提高数据库的并发性能。
在MVCC中,数据库会为每个事务创建一个数据快照。每当数据发生修改时,MySQL不会覆盖原本的数据,而是生成一个存储版本号和时间戳的记录,多版本之间串联起来形成一条版本连,这样不同时刻启动的事务可以无锁的获得不同版本的数据。此时读写操作不会阻塞。
写操作会创建信息的数据版本,但只有在事务提交后,新版本才会对其他事务可见。未提交的事务的修改不会影响其事务的读取,历史版本记录可供已经启动的事务读取。
# 补充回答
在数据库中,对于数据的操作主要有两种,分别是读和写。在并发场景下,就有可能出现以下三种情况:
- 读-读并发
- 读-写并发
- 写-写并发
读-读并发是不会出现问题的,写-写并发这种情况比较常用的就是通过加锁的方式实现。读-写并发则可以通过MVCC机制解决。
# 扩展回答
对于MVCC,我认为了解前需要了解以下几个概念:
- 快照读和当前读
- Undo Log
- 行记录的隐藏字段
- Read View(视图)
# 快照读和当前读
所谓快照读,就是读取的是快照数据,也就是快照生成的那一刻数据,普通读(无锁读)就是快照读。如:
SELECT * FROM TABLE WHERE ...;和快照读相对应的就是当前读,当前读就是读取最新数据。加锁读、增删改都会进行当前读,比如:
SELECT * FROM TABLE LOCK IN SHARE MODE;
SELECT * FROM TABLE FOR UPDATE;
INSERT INTO TABLE ...
DELETE FROM TABLE ...
UPDATE TABLE ...快照读是MVCC实现的基础,当前读是悲观锁实现的基础
那么快照是存在哪里的呢?
这里就需要了解下一个概念 Undo Log
# Undo Log
undo log是事务日志之一,同时它是一种用于回退的日志,在事务没有提交之前,MySQL会记录更新前的数据到undo log日志文件中,当事务回滚时或者数据库崩溃时,可以利用undo log进行回退。
上面提到的"更新前的数据"就是我们前面提到的快照。
一个记录在同一时刻会有多个事务在执行(也就是读-写并发),undo log中会有一条记录的多个快照,那么在一时刻发生普通读操作时要读哪个快照呢?
接下来就需要了解另外几个概念信息了。
# 行记录的隐式字段
首先了解一下行记录存储格式,
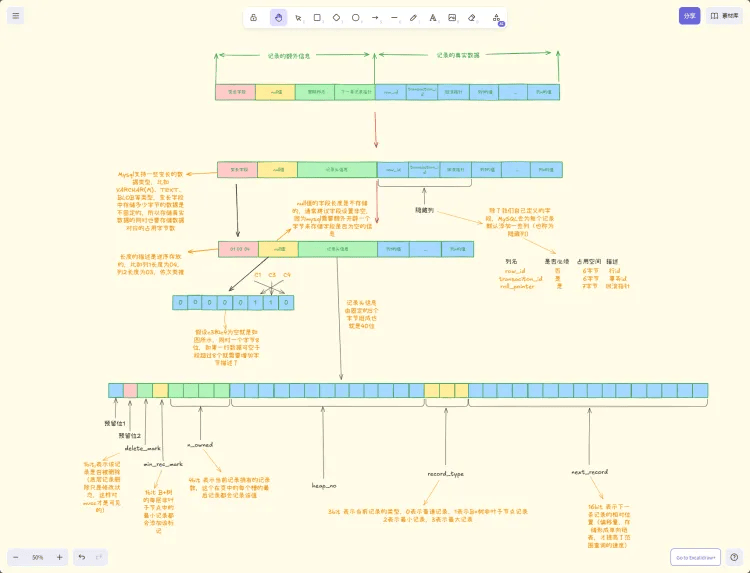
从上面的图可以看到数据库中的每行记录中,除了保存了我们自己定义的一些字段外,还有一些重要隐式字段:
- db_row_id:隐藏主键,如果我们没有给这个表创建主键,那么会以这个字段来创建聚簇索引。
- db_trx_id:对这条记录做了最新一次修改的事务的ID
- db_roll_ptr:回滚指针,指向这条记录的上一个版本,其实他指向的就是Undo Log中的上一个版本的快照的地址。
以上字段,只有聚簇索引的行记录才会有,普通二级索引中是没有这些值的。二级索引的MVCC支持,后面再了解
每次记录变更之前都会先存储一份快照到undo log中,那么这几个隐式字段也会跟着记录一起保存在undo log,同时这个几个字段也是构成版本链的重要成分。db_trx_id、db_roll_ptr是重点。快照链表如下:
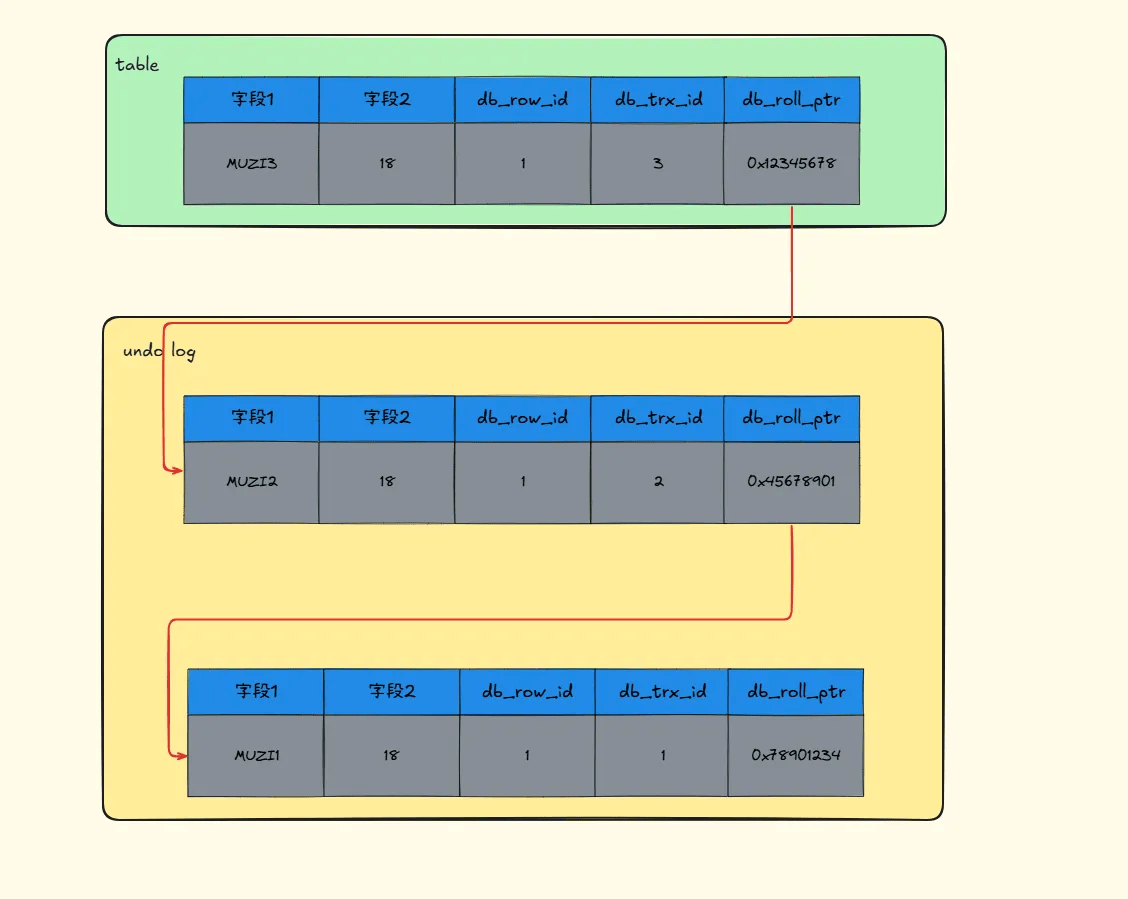
# Read View
Read View 主要来帮我们解决可见性的问题的, 即他会来告诉我们本次事务应该看到哪个快照,不应该看到哪个快照
在MySQL 中,只有READ COMMITTED 和 REPEATABLE READ这两种事务隔离级别才会使用快照读。
- 在 RR 中,快照会在事务开始时生成,只有在本事务中对数据进行更改才会更新快照。
- 在 RC 中,每次读取都会重新生成一个快照,总是读取行的最新版本。
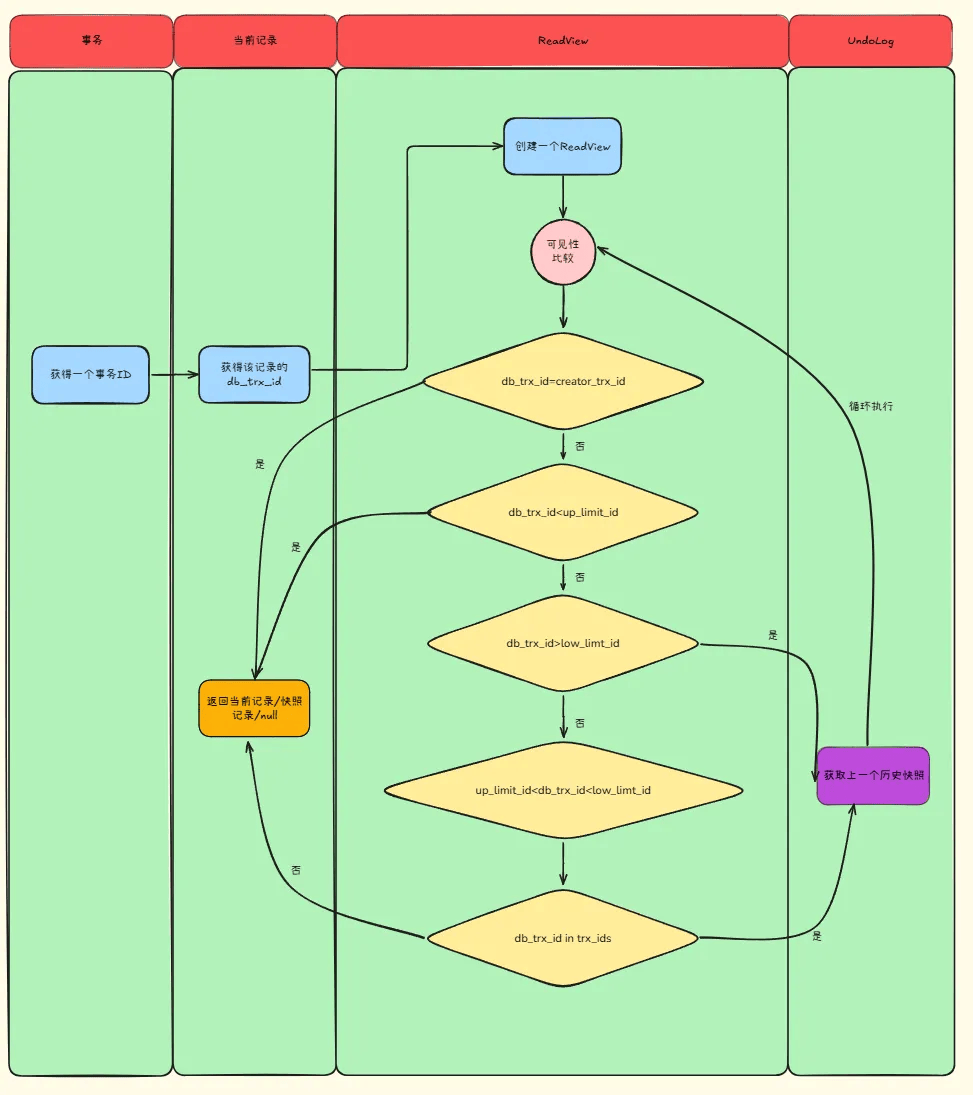
在 Read View 中有几个重要的属性:
- trx_ids,表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。
- low_limit_id,应该分配给下一个事务的id 值。
- up_limit_id,未提交的事务中最小的事务 ID。
- creator_trx_id,创建这个 Read View 的事务 ID。
每开启一个事务,我们都会从数据库中获得一个事务 ID,这个事务 ID 是自增长的,通过 ID 大小,我们就可以判断事务的时间顺序。
假设当前事务要读取某一个记录行,该记录行的 db_trx_id(即最新修改该行的事务ID)为 trx_id,那么,就有以下几种情况了:
- 1、trx_id< up_limit_id,即小于5的事务,说明这些事务在生成ReadView之前就已经提交了,那么该事务的结果就是可见的。
- 2、trx_id>low_limit_id,即大于8的事务,说明该事务在生成 ReadView 后才生成,所以该事务的结果就是不可见的。
- 3、up_limit_id<trx_id<low_limit_id,即大于等于5,小于8,这种情况下,会再拿事务ID和Read View中的trx_ids进行逐一比较。
- 如果,事务ID在trx_ids列表中,那么表示在当前事务开启时,这个事务还是活跃的,那么这个记录对于当 前事务来说应该是不可见的。
- 如果,事务id不在trx_ids列表中,那么表示的是在当前事务开启之前,其他事务对数据进行修改并提交 了,所以,这条记录对当前事务就应该是可见的。
- 当然这里有个例外情况,那就是这个trx_id=creator_trx_id,那么就肯定是可见的
所以,当读取一条记录的时候,经过以上判断,发现记录对当前事务可见,那么就直接返回就行了。那么如果不可见怎么办?没错,那就需要用到undo log了。
当数据的事务ID不符合Read View规则时候,那就需要从undo log里面获取数据的历史快照,然后数据快照的事务ID再来和Read View进行可见性比较,如果找到一条快照,则返回,找不到则返回空。
# MySQL中的日志类型有哪些?以及它们的作用和区别是什么?
# 简要回答
三者都是日志类型文件,但是各自的作用和实现方法有所不同
- binlog主要用来对数据库进行数据备份、崩溃恢复和数据复制等操作,redo log、和undo log主要用于事务管理,记录的都是数据修改操作和回滚操作。redolog用来做恢复,undolog用来做回滚。
- binlog是MySQL用于记录数据库中的所有DDL、DML语句的一种二进制日志,它记录了所有对数据库结构和数据的修改操作。binlog主要用来对数据库进行数据备份、灾难恢复和数据复制等操作。binlog的格式分为基于语句的格式和基于行的格式。
- redolog是MySQL用于实现崩溃恢复和数据持久性的一种机制
- undolog则用于事务回滚或者系统崩溃时撤销(回滚)事务所做的修改,同时Undo log还支持MVCC(多版本并发控制)机制,用于在并发事务执行时提供一定的隔离性。
| 对比维度 | Binlog | Redolog | Undolog |
|---|---|---|---|
| 定义与用途 | 记录数据库变更信息,用于数据库恢复和复制,如主从复制场景及数据误操作后的恢复 | 保证事务的持久性,事务提交时,若数据未持久化到磁盘,系统崩溃后可通过其恢复数据 | 用于记录事务执行过程中数据修改前的值,支持事务回滚操作、MVCC |
| 记录内容 | 数据库层面操作,如基于语句模式下的 SQL 语句或基于行模式下的行数据变化情况 | 物理层面数据修改,对数据页的修改信息,包括修改字节偏移量、修改后的数据内容等 | 数据修改前的旧值,以便回滚时恢复数据 |
| 写入时机与持久化策略 | 事务提交后写入,可配置不同持久化策略,如每次提交后立即同步磁盘或累积一定数量事务后同步 | 事务执行过程中不断写入,事务提交前必须先持久化到磁盘(先写入 redo log buffer,再刷到磁盘 redo log 文件) | 事务执行过程中写入,事务开始分配空间记录旧值,事务提交后可清理,回滚时使用记录恢复数据 |
| 文件格式与存储位置 | 二进制文件,由 MySQL 定义格式,默认存于数据库数据目录下,文件名如 “binlog.xxxxxx” | 由 InnoDB 存储引擎管理,多个 redo log 文件循环使用,存于 InnoDB 数据目录下,文件大小和数量可配置 | 存储在 InnoDB 共享表空间或独立 undo 表空间(依配置而定),与数据页管理紧密结合 |
| 支持引擎 | innodb、myiasm、... | innodb | innodb |