✨ 我是 Muzi 的「文章捕手」,擅长在文字的星海中打捞精华。每当新的篇章诞生,我就会像整理贝壳一样,将思想的闪光点串成珍珠项链~
本文详细解析了MySQL深度分页的性能瓶颈及优化方案,包括子查询与JOIN优化、基于ID范围过滤的查询以及游标查询等方法,结合实例展示了各方案的执行计划和效果。此外,文章系统介绍了MySQL主从同步机制的实现流程,涵盖I/O线程、SQL线程的工作原理及binlog传输过程。针对主从同步延迟问题,分析了异步、全同步及半同步复制方式,并重点阐述了MySQL 5.6至8.0版本的并行复制技术演进及原理。最后,提出了业务层和硬件层面减少主从延迟的实用策略,具备较高的技术参考价值和实操指导意义。
2025-01-15🌱上海: ☀️ 🌡️+4°C 🌬️↓19km/h
# MySQL中如何解决深度分页的问题?
# 总结分析
# 什么是深分页?
- 定义:深度分页问题是在数据库查询中,访问分页查询结果集后面部分(深层页码)时出现的性能问题。
- 示例:以数百万条记录的表分页展示为例,当用户请求第 10000 页(pageSize 为 10)数据时,SQL 语句为 LIMIT 99990, 10,数据库需先扫描前 99990 条记录,导致性能显著下降。
- 起始 ID 计算:起始 ID = (页数 - 1) * 每页项目数 + 1 ,并以不同页数为例说明,如第 10000 页起始 ID 为 99991
# 如何解决深分页问题?
- 子查询和 JOIN 优化:先以子查询获取限定条件下的少量主键 id(对应分页目标区域),在 name 有索引时子查询无需回表,再在主查询中用这些 id 获取完整行数据,减少查询量,提升效率。
- 子查询和 ID 过滤优化:以子查询获取分页起始参考点,基于 ID 做范围查询,可减少回表次数,但要求 ID 必须自增。
- 记录上一个 ID:若能提前预估分页条件,记住上一页最大 ID,下一页查询时通过 “id> 上一页最大 ID” 查询,能提升性能。
- 使用搜索引擎:对于基于文本内容的搜索,可采用 Elasticsearch 等全文搜索引擎优化深度分页性能,虽 ES 也存在深度分页问题,但影响小于 MySQL
# 实例测试
-- 创建示例表
CREATE TABLE test_table (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
c1 VARCHAR(255),
c2 VARCHAR(255)
);
-- 插入测试数据
DELIMITER //
CREATE PROCEDURE InsertTestData()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 300000 DO
INSERT INTO test_table (name, c1, c2) VALUES ('Muzi', CONCAT('value1_', i), CONCAT('value2_', i));
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
CALL InsertTestData();# 1. 使用子查询和 JOIN 优化
由于100w数据添加过慢,这里我添加了30w,但是我看了执行时间差别不是很大,所以我们这里看执行计划判断是否进行了优化。
# 优化前
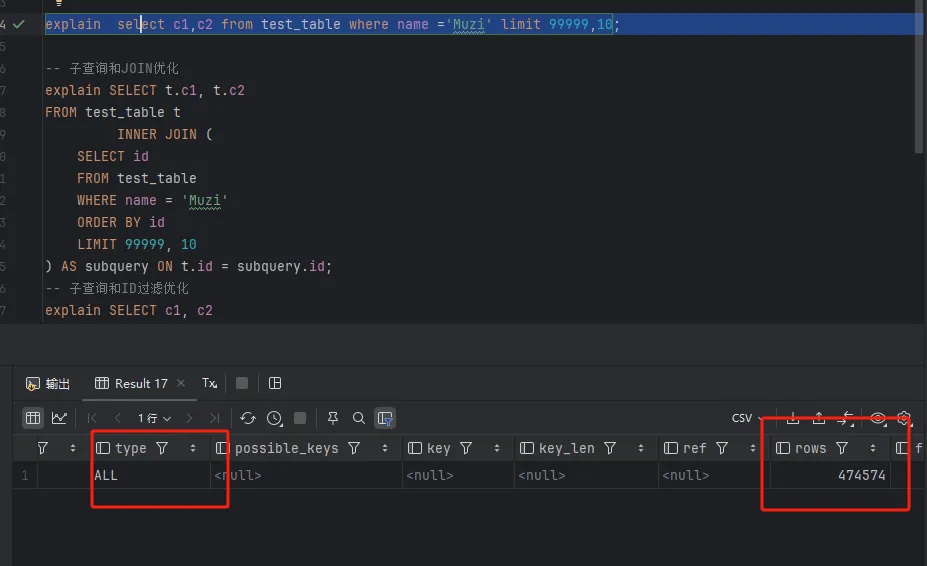
下面的 SQL 语句使用子查询和 JOIN 来优化深度分页:
-- 子查询和JOIN优化
SELECT t.c1, t.c2
FROM test_table t
INNER JOIN (
SELECT id
FROM test_table
WHERE name = 'Muzi'
ORDER BY id
LIMIT 99999, 10
) AS subquery ON t.id = subquery.id;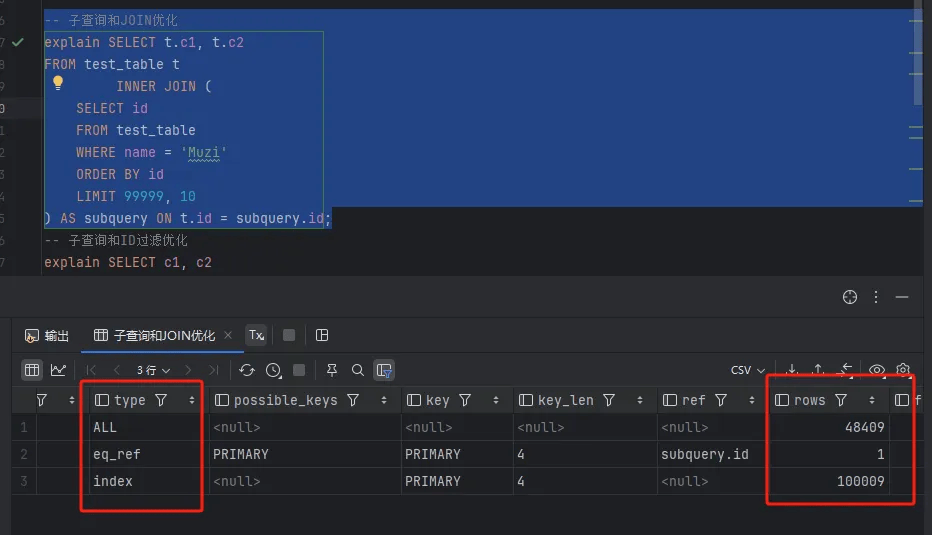
# 2. 使用子查询和 ID 过滤优化
此方法使用子查询获取分页起始点,基于 ID 做范围查询:
-- 子查询和ID过滤优化
SELECT c1, c2
FROM test_table
WHERE name = 'Muzi'
AND id >= (SELECT id FROM test_table WHERE name = 'Muzi' ORDER BY id LIMIT 999900, 1)
ORDER BY id
LIMIT 10;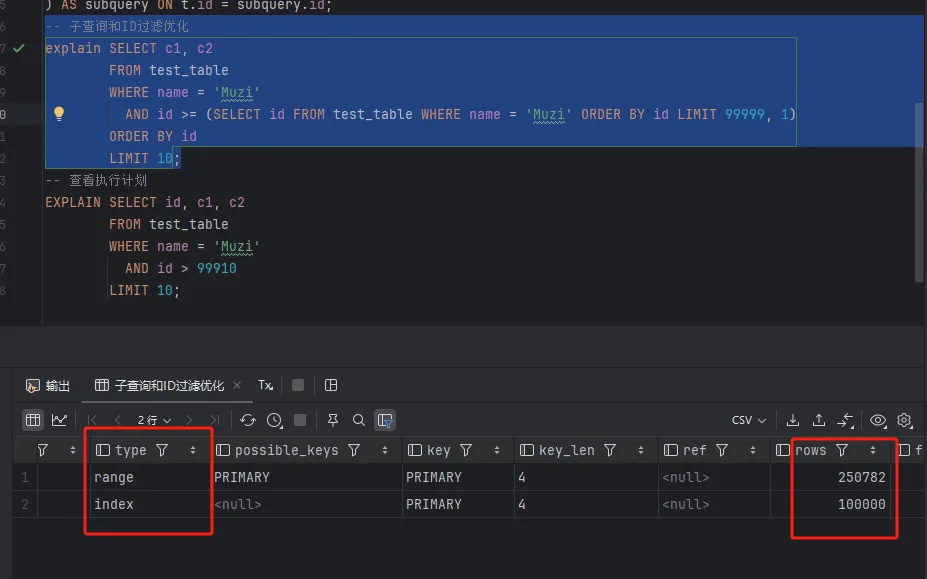
# 3.记录上一个id(也叫做游标查询)
-- 查看执行计划
EXPLAIN SELECT id, c1, c2
FROM test_table
WHERE name = 'Muzi'
AND id > 99910
LIMIT 10;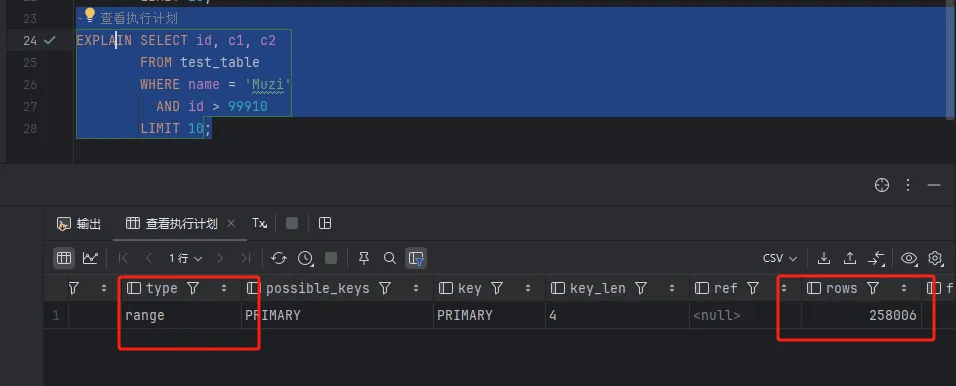
# 什么是MySQL的主从同步机制?它是如何实现的?
# 总结分析
前天的一道题解中已经初步涉及到主从同步机制,具体可看
MySQL 默认的事务隔离级别是什么?为什么选择这个级别? - 木子金又二丨的回答记录 - 面试鸭 - 程序员求职面试刷题神器
接下我们就具体分析下主从同步机制
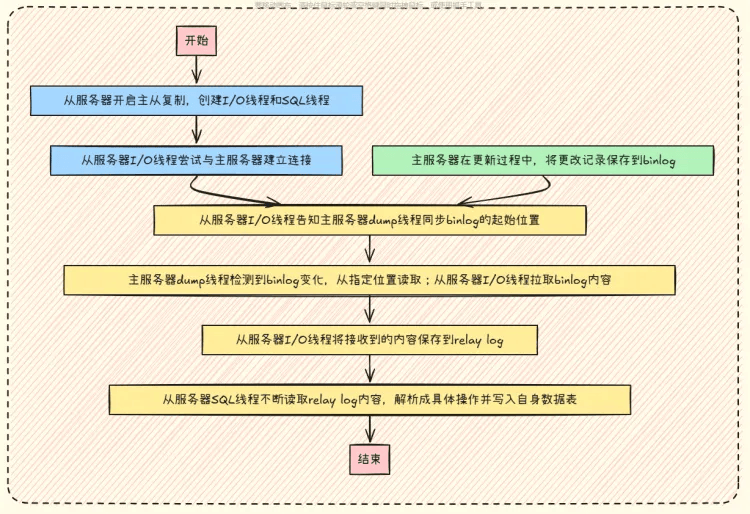
# 主从复制的具体流程
- 线程创建:从服务器开启主从复制后,会创建 I/O 线程和 SQL 线程。
- 连接建立:从服务器的 I/O 线程与主服务器建立连接,主服务器的 binlog dump 线程与之交互。
- 同步位置告知:从服务器的 I/O 线程告知主服务器的 dump 线程从何处开始接收 binlog。
- 主服务器操作:主服务器更新时将更改记录保存到 binlog,不同格式记录内容有别。
- binlog 传输:主服务器 dump 线程检测到 binlog 变化,从指定位置读取,由从服务器 I/O 线程拉取,采用拉取模式利于从库管理同步进度和处理延迟。
- 中继日志存储:从服务器 I/O 线程将接收到的内容保存到 relay log 中。
- 数据写入:从服务器的 SQL 线程读取 relay log 内容,解析成具体操作后写入自身数据表 。
# 扩展知识
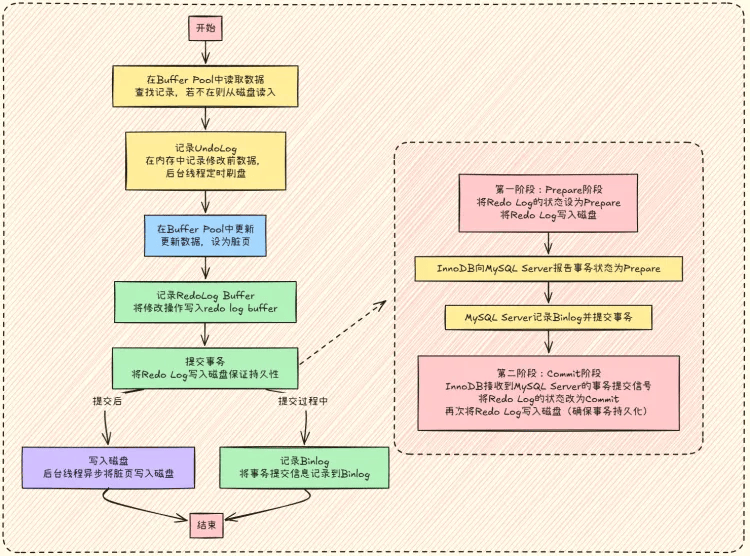
# innoDB的一次更新事务流程
- 数据读取:从 Buffer Pool 中查找待更新记录,若不存在则从磁盘读取到 Buffer Pool。
- 记录 UndoLog:修改前在内存中记录原数据,之后由后台线程定时写入磁盘,用于事务回滚以保证原子性和一致性。
- 更新数据:在 Buffer Pool 中更新数据,并将数据页标记为 “脏页”。
- 记录 RedoLog Buffer:将修改操作写入 redo log buffer 。
- 提交事务:完成修改后提交事务,将 Redo Log 写入磁盘保证持久性。
- 写入磁盘:提交后,后台线程异步将 Buffer Pool 中的脏页写入磁盘实现持久化。
- 记录 Binlog:提交过程中,将事务相关信息(如开始时间、数据库名等)记录到 Binlog,用于主从复制 。
# 主从同步的方式
- 异步复制:是默认方式,主库执行完事务马上给客户端返回,不关注从库是否完成事务执行。缺点是主库故障时,若未来得及同步数据,从库升级为主库会丢失事务变更内容。
- 全同步复制:主库执行完事务后,等待所有从库完成数据复制才给客户端反馈。安全性高,但性能差,从库数量多会延长整个过程。
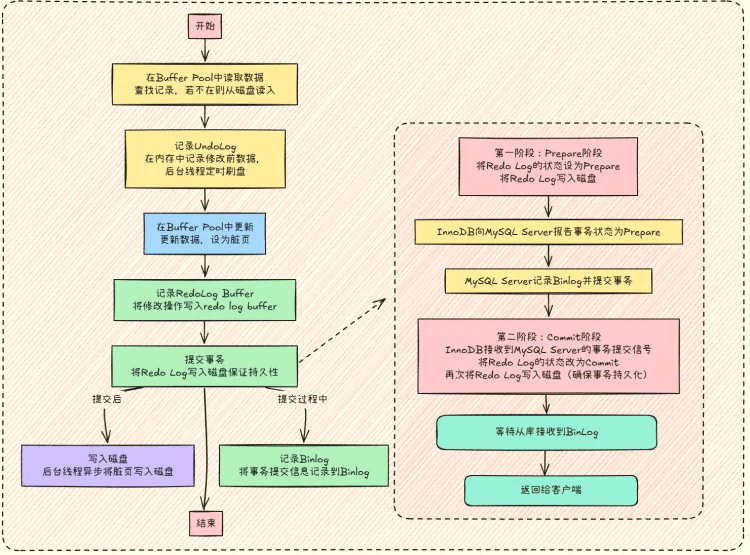
- 半同步复制:介于前两者之间,主库执行完事务不立即给客户端反馈,而是等其中一个从库接收到事件后再反馈。在事务提交两阶段完成后,等从库接收 binlog 才返回成功 。
如果把半同步复制过程加入到整体事务流程中,流程如下
# 如何解决主从同步的延迟?
数据库主从延迟指主从复制过程中从服务器与主服务器数据的时间差,常见原因如下:
- 网络延迟:主从节点间网络不佳是常见致因。
- 从节点性能问题:硬件资源(CPU、内存、磁盘)不足会使处理复制事件能力受限,进而增加延迟。
- 复制线程不够:从节点线程少或不足会导致数据回放慢,引发主从数据延迟。
解决主从延迟可采取以下措施:
- 优化网络:保证主从节点网络稳定,同城或同单元部署以降低延迟。
- 提高从服务器性能:增加硬件资源提升处理能力。
- 并行复制:利用 MySQL 并行复制功能提升效率、减少延迟。
# 并行复制的原理
在 MySQL 主从复制中,因从库单个 SQL 线程处理大量日志易导致主从延迟,MySQL 推出多种并行复制方案:
- MySQL 5.6 库级别并行复制:基于 Schema(库)进行并行复制,每个库可拥有自己的复制线程来并行处理不同库的写入,提升性能。但多数业务为单库,该方案实用性欠佳,未获开发者和 DBA 认可。
- MySQL 5.7 基于组提交的并行复制(MTS):组提交将多个事务的提交操作合并为批处理,减少磁盘 IO 和锁定开销。当多个事务进入 Prepare 阶段且锁无冲突(即修改不同行记录)时,可在从库用多个 SQL 线程并行执行组提交中的 SQL,提高主从复制效率,降低延迟。不过该方案依赖主库并行度,主库并发不高时可能无法进行组提交,也就无法使用并行复制优化。同时如果主库的SQL执行并没有那么频繁,那么时间间隔可能就会超过组提交的那两个参数阈值,就不会进行组提交。那么复制的时候就不能用并行复制了。
- MySQL 8.0 基于 WRITESET 的并行复制:为解决 MySQL 5.7 方案的局限性而引入。即便主库串行提交事务,只要事务间不冲突,在从库就能并行回放。WRITESET 是使用 C++ STL 中 set 容器的集合,元素为行数据主键和唯一键的 hash 值(与指定算法有关)。通过检测事务更新记录的 hash 值是否冲突,判断能否并行回放,确保同一 write_set 中的变更不冲突,进而可通过多个线程并行回放 SQL 。
上面的MTS并行复制涉及到了组提交,关于组提交的回答我之前也有解析过
MySQL 事务的二阶段提交是什么? - 木子金又二丨的回答记录 - 面试鸭 - 程序员求职面试刷题神器
# 如何处理MySQL的主从同步延迟?
# 总结分析
在数据库读写场景中,主从延迟难以完全消除,只能尽量减少,常见解决方式如下:
- 二次查询:从库查不到数据时再去主库查询,由 API 封装此逻辑作为兜底策略。优点是简单,缺点是会将读压力转移到主库,易遭受恶意查询冲击。
- 强制主库操作:把写后立即读的操作固定走主库,这种方式过于死板,缺乏灵活性,不推荐使用。
- 按业务区分:关键业务读写都走主库,非关键业务采用读写分离。根据业务实际情况调整,如用户注册等操作可读写主库,能避免类似登录时用户不存在的问题。
- 使用缓存:主库写入后同步到缓存,查询先查缓存以避开延迟问题,但会带来缓存数据一致性的新问题
除了上面的业务层面解决的方案,还可以通过硬件层面解决,毕竟只要有钱,什么瓶颈问题都不是问题,加钱就行!
解决主从延迟可采取以下措施:
- 优化网络:保证主从节点网络稳定,同城或同单元部署以降低延迟。
- 提高从服务器性能:增加硬件资源提升处理能力。
- 并行复制:利用 MySQL 并行复制功能提升效率、减少延迟。
# 并行复制的原理
在 MySQL 主从复制中,因从库单个 SQL 线程处理大量日志易导致主从延迟,MySQL 推出多种并行复制方案:
- MySQL 5.6 库级别并行复制:基于 Schema(库)进行并行复制,每个库可拥有自己的复制线程来并行处理不同库的写入,提升性能。但多数业务为单库,该方案实用性欠佳,未获开发者和 DBA 认可。
- MySQL 5.7 基于组提交的并行复制(MTS):组提交将多个事务的提交操作合并为批处理,减少磁盘 IO 和锁定开销。当多个事务进入 Prepare 阶段且锁无冲突(即修改不同行记录)时,可在从库用多个 SQL 线程并行执行组提交中的 SQL,提高主从复制效率,降低延迟。不过该方案依赖主库并行度,主库并发不高时可能无法进行组提交,也就无法使用并行复制优化。同时如果主库的SQL执行并没有那么频繁,那么时间间隔可能就会超过组提交的那两个参数阈值,就不会进行组提交。那么复制的时候就不能用并行复制了。
- MySQL 8.0 基于 WRITESET 的并行复制:为解决 MySQL 5.7 方案的局限性而引入。即便主库串行提交事务,只要事务间不冲突,在从库就能并行回放。WRITESET 是使用 C++ STL 中 set 容器的集合,元素为行数据主键和唯一键的 hash 值(与指定算法有关)。通过检测事务更新记录的 hash 值是否冲突,判断能否并行回放,确保同一 write_set 中的变更不冲突,进而可通过多个线程并行回放 SQL 。
上面的MTS并行复制涉及到了组提交,关于组提交的回答我之前也有解析过